



技术栈 MinIO · Apache Iceberg · Apache Flink · Apache Spark · Apache Doris
适用场景 本地化部署 · 智慧供热数据平台

一座中等供热企业,覆盖三千余万平方米、四五百座换热站、三四十万用户,每个采暖季产生数十亿条时序记录。这些数据要能秒级写入、要能低成本留存五年、要能同时支撑实时告警和全局能耗分析——这正是本地湖仓一体化要解决的问题。本文从采集链路、物理存储、入湖流程到三大引擎的具体用法,把落地实现细节讲透。
一、供热数据特征与采集链路
1.1 数据从哪里来
供热系统沿"热源—一次管网—换热站—二次管网—楼栋—用户"物理链路部署传感器,数据来源覆盖全链路:
| 数据来源 | 采集内容 | 采集方式 |
|---|---|---|
| 热源厂(锅炉/首站) | 锅炉出口温度、压力、流量,燃料消耗,烟气排放(颗粒物、SO₂、NOₓ),循环泵运行参数 | PLC/DCS 直采 |
| 换热站 | 一次网/二次网供回水温度、压力、流量,循环泵/补水泵运行参数,换热器状态,电动阀开度 | PLC 经 SCADA |
| 热计量表(超声波热量表) | 用户端累计热量、瞬时流量、供回水温度,符合 CJ/T 188 标准 | 无线/MBus 远传 |
| 室温采集器 | 室内温度、用户温控阀状态 | LoRa/NB-IoT |
| 气象数据 | 室外温度、湿度、风速、降雪量 | 气象 API 定时拉取 |
| 客服工单 | 报修、投诉、缴费记录、用热偏好 | 业务系统数据库 |
1.2 数据特征
按团体标准 T/PPZL 029—2024,关键参数(供回水温度、压力、流量)采集频率不低于 1 次/分钟,一般参数不低于 1 次/10 分钟,数据延迟不超过 30 秒,存储期限不少于 5 年。部分企业已达秒级上报。
供热运行数据属于典型时序数据——写多读少、按时间有序、重复度高。温度、压力这类物理量变化平缓,相邻采样值高度相似,列存压缩率极高。数据质量要求:温度误差 ≤ ±0.5℃,压力误差 ≤ ±0.01MPa,流量误差 ≤ ±2%。
1.3 采集链路:从设备到 Kafka
数据从设备到湖仓,经过四跳:
传感器/仪表 → 采集网关(PLC/RTU) → SCADA/前置机 → Kafka → Flink → Iceberg
第一跳:传感器到采集网关。换热站 PLC 通过 Modbus/OPC UA 协议轮询本站传感器,热计量表通过无线汇聚到集中器,室温采集器通过 LoRa/NB-IoT 上报到网关。
第二跳:采集网关到 SCADA 前置机。各站 PLC 经 4G/光纤把数据推送到 SCADA 前置机,前置机做协议转换(统一为 JSON/Protobuf),并写入本地缓冲。
第三跳:SCADA 前置机到 Kafka。前置机通过 Kafka Producer 把标准化后的消息推送到 Kafka。这是关键的"削峰填谷"环节——Kafka 承接高频写入,下游 Flink 按自己的节奏消费。
第四跳:Kafka 到 Iceberg。Flink 消费 Kafka,清洗后写入 Iceberg 表,数据正式入湖。
1.4 Kafka Topic 设计
按数据类型分 topic,便于 Flink 作业按类型独立消费、独立容错:
| Topic 名 | 数据内容 | 分区数 | 保留策略 |
|---|---|---|---|
heat.scada.station_metric |
换热站运行参数(温度压力流量) | 24 | 7 天 |
heat.source.boiler_metric |
热源厂锅炉运行参数 | 6 | 7 天 |
heat.meter.heat_consumption |
用户热量表读数 | 12 | 7 天 |
heat.room.temperature |
室温采集器数据 | 12 | 7 天 |
heat.weather.observation |
气象观测数据 | 3 | 7 天 |
heat.cdc.business |
业务库变更(工单/缴费/用户档案) | 6 | 3 天 |
分区数按峰值流量估算:单分区吞吐约 10MB/s,一个中型供热企业峰值约 5 万条/秒、每条约 200 字节(约 10MB/s),24 分区留足余量。
1.5 Kafka 消息格式
推荐用 Protobuf 或 JSON。一条换热站运行参数消息的 JSON 示例:
{
"station_id": "ST-2024-001",
"device_id": "DEV-PLC-001",
"metrics": {
"primary_supply_temp": 85.2,
"primary_return_temp": 60.1,
"secondary_supply_temp": 50.3,
"secondary_return_temp": 43.7,
"primary_pressure": 0.82,
"primary_flow": 142.5,
"secondary_flow": 88.3,
"heat_power": 1850.6,
"circulation_pump_freq": 35.2,
"makeup_pump_status": 1,
"valve_opening": 65
},
"quality": 192,
"event_time": "2026-01-15T08:30:00.000+08:00",
"ingest_time": "2026-01-15T08:30:01.200+08:00"
}
quality 是数据质量位掩码:bit0=通信正常,bit1=传感器校验通过,bit2=量程内。Flink 据此做清洗过滤。
二、整体架构设计
整套架构分为五层,自下而上依次是存储层、表格式层、计算层、服务层与接入层。各层职责清晰、解耦演进。
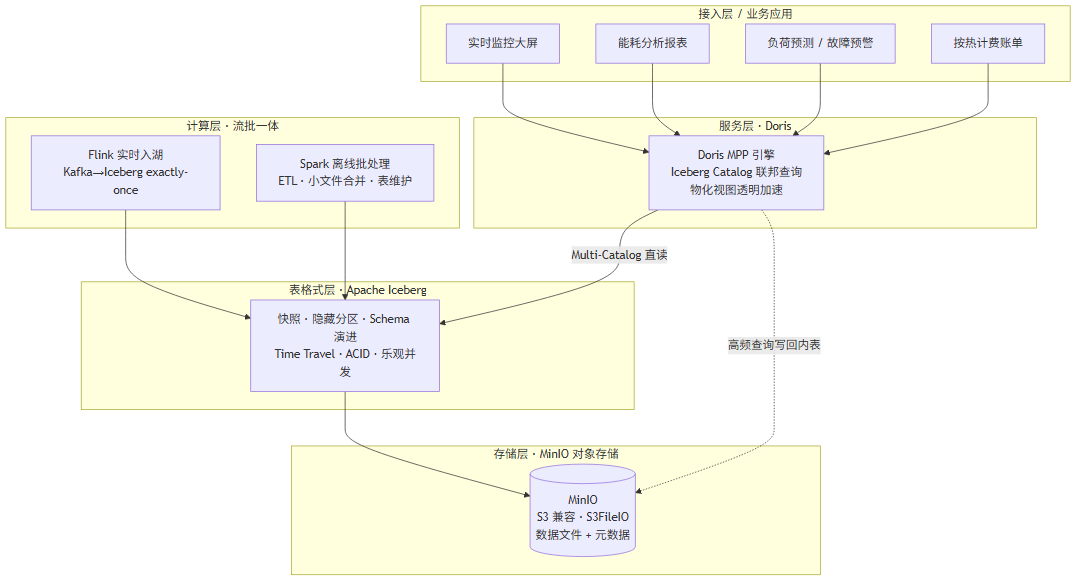
图 1:供热行业本地湖仓一体化五层架构
核心主线是"数据只落一份"。所有时序与业务数据最终都沉淀在 MinIO 上的 Iceberg 表里;Flink 和 Spark 分别从实时、离线两个方向写湖;Doris 不搬运数据,而是通过 Multi-Catalog 直接读取 Iceberg 表,高频查询结果再以物化视图或内表形式缓存加速。接入层的各类业务应用统一经 Doris 提供的 SQL 接口获取数据。
分层的好处是每层可独立演进:存储扩容只动 MinIO;新增分析能力往往只动 Doris 物化视图;流处理逻辑调整只动 Flink 作业,互不干扰。
三、存储底座:MinIO + Iceberg
3.1 MinIO:S3 兼容的本地对象存储
MinIO 提供 S3 兼容 API,纯本地部署即可获得对象存储的全部能力——高吞吐、按容量扩展、纠删码冗余。对供热企业,"数据不出厂区"是硬约束,MinIO 正好满足,且直接以本地磁盘速度提供服务。
MinIO 在湖仓中的角色是单纯的存储:它只管把字节存好,不感知表结构。表的 schema、分区、快照这些"表语义"全部交给 Iceberg 的元数据管理。这种解耦使得 Flink、Spark、Doris 可以直接读写对象存储上的 Iceberg 表,无需数据搬迁。
MinIO 部署要点:生产环境建议至少 4 节点、每节点多块数据盘,启用纠删码(默认 EC:4,4 数据 + 4 校验,可容忍 4 块盘故障)。关键启动参数:
minio server /data{1...8} \
--console-address ":9001" \
--address ":9000"
# 环境变量
MINIO_ROOT_USER=heat_admin
MINIO_ROOT_PASSWORD=<强密码>
MINIO_DOMAIN=minio.heat.local # 支持虚拟主机风格寻址
启动后创建 bucket warehouse(Iceberg 数据仓库根目录)和 warehouse-meta(可选,独立元数据 bucket)。
3.2 Iceberg:开放表格式
Apache Iceberg 在对象存储之上叠加一层元数据,把"一堆文件"变成"一张有事务语义的表"。核心特性对应供热痛点:
- 快照与 Time Travel:每次写操作生成新快照,可查询历史版本、可回滚。供热出问题时能回到事故前一刻复盘。
- 隐藏分区:用户只写查询过滤条件,Iceberg 自动按分区裁剪。按
days(event_time)分区,查某天数据时自动只扫对应文件。 - Schema 演进:增删改列是纯元数据操作,列绑定唯一 ID,历史数据对新列返回 NULL,无需重写数据文件。供热设备种类多、字段常变,这一特性尤为关键。
- ACID 与乐观并发:多引擎可并发读写同一张表,Flink 在写、Doris 在读,互不阻塞。
3.3 Iceberg 元数据四层结构
Iceberg 的元数据呈四层结构,这是它能做到快速查询规划的根本原因:

图 2:Iceberg 元数据四层结构
各层职责:
| 层级 | 文件 | 内容 | 数量级 |
|---|---|---|---|
| metadata file | v1.metadata.json, v2.metadata.json… |
表 schema、分区规则、属性、当前快照指针、所有快照历史 | 每次表结构/快照变更生成一个 |
| manifest list | <uuid>.avro(snap-xxx.avro) |
一个快照的入口,指向多个 manifest 文件 | 每个快照 1 个 |
| manifest files | <uuid>.m0.avro |
清单,记录数据文件路径 + 每列的 min/max/null_count/记录数 | 每个快照若干个 |
| data files | <uuid>-0-0-<commit-uuid>.parquet |
实际数据,Parquet 列存 | 与数据量正相关 |
查询引擎读查询时的工作流程:读 metadata file 找到当前快照 → 读 manifest list → 读 manifest files,利用其中的 min/max 统计做文件裁剪(Data Skipping)→ 只打开命中的 data files 读取数据。即便一张表存了五年、数十亿条记录,查某天某站的温度,也只会扫描极少数文件。
3.4 数据在 MinIO 上的物理布局
这是理解"设备数据在 Iceberg 里怎么存"的关键。以 ODS 层 SCADA 时序表 heat_catalog.ods.scada_metric_raw 为例,按 days(event_time), bucket(16, station_id) 分区,物理目录结构如下:
s3://warehouse/heat_catalog/ods/scada_metric_raw/
├── data/
│ ├── event_time_day=2026-01-15/
│ │ ├── station_id_bucket=0/
│ │ │ ├── 00000-0-1a2b3c4d-5e6f-7a8b-9c0d.parquet ← 数据文件
│ │ │ ├── 00001-0-2b3c4d5e-6f7a-8b9c-0d1e.parquet
│ │ │ └── 00002-0-3c4d5e6f-7a8b-9b0c-1d2e.parquet
│ │ ├── station_id_bucket=1/
│ │ │ └── 00000-0-4d5e6f7a-8b9c-0d1e-2f3a.parquet
│ │ ├── ... (station_id_bucket=2 ~ 15)
│ │ └── station_id_bucket=15/
│ │ └── 00000-0-5e6f7a8b-9c0d-1e2f-3a4b.parquet
│ ├── event_time_day=2026-01-16/
│ │ └── station_id_bucket=0/
│ │ └── ...
│ └── ...
├── metadata/
│ ├── v1.metadata.json ← 表初始 metadata
│ ├── v2.metadata.json ← 第一次写入后
│ ├── v3.metadata.json ← 第二次写入后
│ ├── snap-1640995200000-1.avro ← manifest list(快照入口)
│ ├── snap-1640995260000-2.avro
│ ├── 1a2b3c4d-5e6f-7a8b-9c0d.m0.avro ← manifest 文件
│ ├── 2b3c4d5e-6f7a-8b9c-0d1e.m0.avro
│ └── ...
目录命名规则:event_time_day=YYYY-MM-DD 是隐藏分区的物理体现——分区值由 Iceberg 从 event_time 字段经 days() 函数推导,用户无需手动填分区列。station_id_bucket=N 是 bucket(16, station_id) 哈希分桶的结果,N 取值 0~15,把同一天的数据按站点哈希分散到 16 个子目录,避免单目录文件过多。
数据文件命名:00000-0-<uuid>.parquet,前缀是 task 编号,uuid 全局唯一。每次 Flink checkpoint 提交时,新写入的文件作为一个新快照被记录到 metadata。
3.5 Parquet 文件内部结构
每个 .parquet 数据文件内部也是分层的,理解它有助于理解为什么列存对时序数据压缩率极高:
Parquet 文件
├── Row Group 1 (128MB,约 100 万行)
│ ├── Column Chunk: station_id (STRING)
│ │ ├── Page 1 (字典编码 + RLE,压缩后 ~50KB)
│ │ └── Page 2
│ ├── Column Chunk: metric_code (STRING)
│ │ └── Page 1 (字典编码,指标码就十几种,压缩率极高)
│ ├── Column Chunk: metric_value (DOUBLE)
│ │ └── Page 1 (温度值 85.2/85.3/85.1...,Delta 编码 + zstd,压缩率 ~10x)
│ └── Column Chunk: event_time (TIMESTAMP)
│ └── Page 1 (时间戳递增,Delta 编码,压缩率 ~20x)
├── Row Group 2
└── Footer (schema + column statistics: min/max/null_count)
时序数据天然适合列存:station_id、metric_code 这类低基数字段用字典编码后压缩率可达 50~100 倍;metric_value 相邻值高度相似,Delta + zstd 压缩率约 10 倍;event_time 单调递增,Delta 编码压缩率约 20 倍。综合下来,供热时序数据在 Parquet 中的压缩率通常在 8~15 倍,这也是"4 年 950GB 压缩到 77GB"的底层原因。
Footer 中的 column statistics(每列的 min/max/null_count)会被 Iceberg 提取到 manifest 文件里,查询时用于 Data Skipping——查"ST-2024-001 站 1 月 15 日温度",引擎发现某数据文件的 station_id max 不含该站或 event_time 范围不符,直接跳过该文件。
3.6 Catalog 与 S3FileIO 配置
Catalog 是 Iceberg 的元数据入口,决定了多引擎如何"找到"同一张表。推荐 REST Catalog(apache/iceberg-rest-fixture),它为所有引擎提供统一的元数据服务。MinIO 与 Iceberg 对接,官方推荐 S3FileIO 而非 Hadoop file-io——前者针对 S3 语义优化、依赖更轻、性能更好。
REST Catalog 服务(Docker 部署)的环境变量配置:
# Iceberg REST Catalog 服务环境变量
AWS_ACCESS_KEY_ID=heat_admin
AWS_SECRET_ACCESS_KEY=<强密码>
AWS_REGION=us-east-1
CATALOG_WAREHOUSE=s3://warehouse/
CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO
CATALOG_S3_ENDPOINT=http://minio:9000
CATALOG_S3_PATH_STYLE_ACCESS=true
三个关键参数:CATALOG_IO__IMPL 指定 S3FileIO;CATALOG_S3_ENDPOINT 指向 MinIO 地址;CATALOG_WAREHOUSE 用 s3:// 协议。CATALOG_S3_PATH_STYLE_ACCESS=true 强制使用 path-style 寻址(http://minio:9000/bucket/key),避免本地 DNS 不支持虚拟主机风格的问题。
REST Catalog 启动后,Flink、Spark、Doris 三个引擎用相同的 uri(如 http://rest:8181)连接它,就能看到同一套表元数据,实现多引擎共享元数据。
四、数据入湖全流程
4.1 整体数据流
数据从设备到最终被业务查询,经过一条完整的入湖链路:
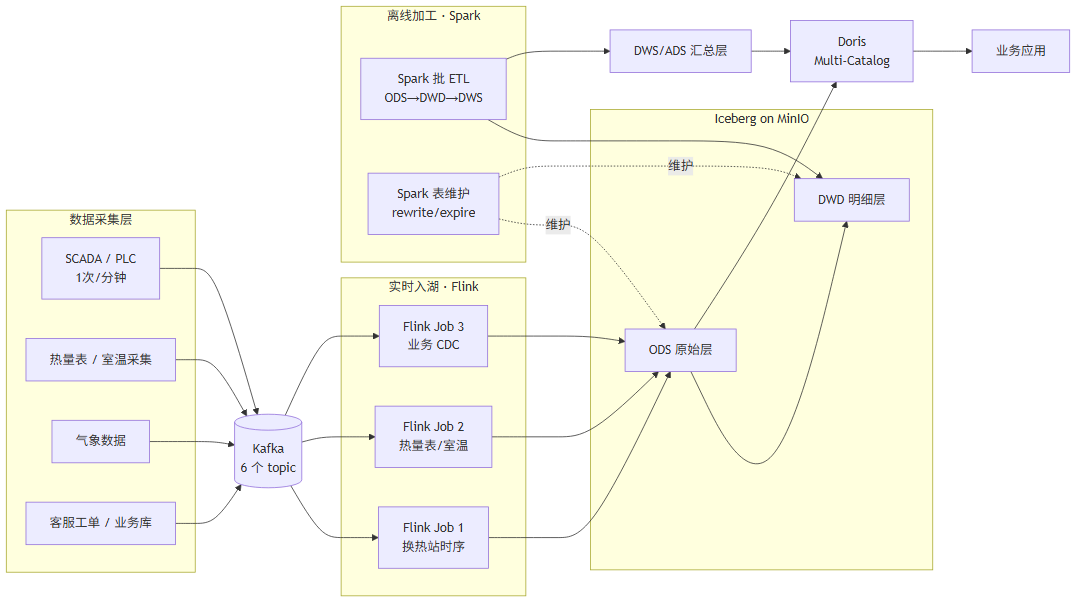
图 3:供热数据端到端入湖流程
4.2 入湖的三个关键阶段
阶段一:实时入湖(Kafka → Flink → ODS)
这是数据进湖的第一站。Flink 消费 Kafka,做基础清洗(去野值、补质量标记),按 exactly-once 语义写入 ODS 层 Iceberg 表。这一阶段追求"快和准"——数据延迟在分钟级(checkpoint 间隔),不丢不重。ODS 层保留原始粒度(分钟级),不做聚合。
阶段二:离线加工(ODS → DWD → DWS → ADS)
Spark 每日凌晨从 ODS 读取前一天数据,加工成 DWD(清洗标准化)、DWS(轻度聚合,如站日粒度)、ADS(应用指标,如达标率)。这一阶段追求"全和准"——可以做重计算、跨表关联、复杂聚合,不受实时延迟约束。同时 Spark 负责表维护(合并小文件、过期快照)。
阶段三:查询服务(Iceberg → Doris → 应用)
Doris 通过 Iceberg Catalog 直读湖中各层表,高频查询命中物化视图透明加速,维度信息通过联邦查询关联 MySQL 维表。这一阶段追求"快和灵活"——交互式响应、统一 SQL 接口。
4.3 为什么这样分工
实时链路只做轻量清洗和入湖,不做重计算——因为流处理的窗口聚合容易出错、状态大、恢复慢。重计算交给离线 Spark,它可以用全量数据、从容重算。Doris 不搬运数据,只加速查询——避免数据冗余和一致性问题。三者各司其职,是这套架构能同时满足"实时"和"全局分析"的根本。
五、Flink 实时入湖详解
Flink 是实时入湖的核心引擎。本节以换热站时序数据为例,从 Source 到 Sink 完整讲解一个 Flink 作业的实现。
5.1 Flink 作业整体结构
一个完整的 Flink 入湖作业包含五步:Source(读 Kafka)→ 反序列化 → 清洗(UDF)→ Watermark → Sink(写 Iceberg)。

5.2 Maven 依赖
<!-- Flink 核心(按版本选,以 1.19 为例)-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.19.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>3.2.0-1.19</version>
</dependency>
<!-- Iceberg Flink runtime -->
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-flink-runtime-1.19</artifactId>
<version>1.5.0</version> <!-- 或 1.6.x,与 Doris SDK 对齐 -->
</dependency>
<!-- Iceberg AWS S3(S3FileIO 依赖)-->
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-aws-bundle</artifactId>
<version>1.5.0</version>
</dependency>
版本对齐铁律:
iceberg-flink-runtime的大版本必须与 Flink 版本对应(1.19 配 runtime-1.19),Iceberg 版本号(1.5.0/1.6.0)需与 Spark 和 Doris 的 Iceberg SDK 兼容。
5.3 Source:Kafka 连接器配置
// 1. 配置 Iceberg Catalog Loader
Configuration icebergConf = new Configuration();
icebergConf.set(CatalogProperties.CATALOG_IMPL, "org.apache.iceberg.rest.RESTCatalog");
icebergConf.set(CatalogProperties.URI, "http://rest:8181");
icebergConf.set(CatalogProperties.WAREHOUSE_LOCATION, "s3://warehouse/");
icebergConf.set("io-impl", "org.apache.iceberg.aws.s3.S3FileIO");
icebergConf.set("s3.endpoint", "http://minio:9000");
icebergConf.set("s3.access-key-id", "heat_admin");
icebergConf.set("s3.secret-access-key", "<密码>");
icebergConf.set("s3.path-style-access", "true");
CatalogLoader catalogLoader = CatalogLoader.custom(
"heat_catalog", icebergConf.toMap(),
new HashMap<>(), "org.apache.iceberg.rest.RESTCatalog");
TableLoader tableLoader = TableLoader.fromCatalog(catalogLoader,
TableIdentifier.of("ods", "scada_metric_raw"));
// 2. Kafka Source
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("kafka:9092")
.setTopics("heat.scada.station_metric")
.setGroupId("flink-scada-to-iceberg")
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
关键配置说明:
setStartingOffsets(committedOffsets):从上次提交的 offset 续读,作业重启不丢数据不重读。OffsetResetStrategy.LATEST:首次启动(无 committed offset)从最新位开始,避免回放历史。
5.4 反序列化与数据清洗
Kafka 消息是 JSON 字符串,需要解析成 Flink RowData,再做清洗。供热数据常见质量问题:传感器故障导致温度值 999(野值)、通信中断导致重复值、时间戳乱序。
// 3. 解析 + 清洗
DataStream<RowData> cleanedStream = env
.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafka-source")
.map(new ScadaParseAndCleanMap()) // JSON → RowData + 清洗
.filter(Objects::nonNull) // 过滤掉清洗失败的脏数据
.assignTimestampsAndWatermarks(
WatermarkStrategy.<RowData>forBoundedOutOfOrderness(Duration.ofSeconds(30))
.withTimestampAssigner((row, ts) ->
row.getTimestamp(6, 6).getMillisecond())); // event_time 字段索引 6
清洗 UDF 的核心逻辑:
public class ScadaParseAndCleanMap extends MapFunction<String, RowData> {
// 物理量合理范围(用于去野值)
static final double TEMP_MIN = -30.0, TEMP_MAX = 150.0;
static final double PRESSURE_MIN = 0.0, PRESSURE_MAX = 2.5;
static final double FLOW_MIN = 0.0, FLOW_MAX = 5000.0;
@Override
public RowData map(String json) throws Exception {
JSONObject obj = JSON.parseObject(json);
String stationId = obj.getString("station_id");
JSONObject m = obj.getJSONObject("metrics");
long eventTimeMs = parseToMillis(obj.getString("event_time"));
// 去野值:超出物理量程的置 NULL,不丢弃,保留记录便于追溯
Double supplyTemp = sanitize(m.getDouble("primary_supply_temp"), TEMP_MIN, TEMP_MAX);
Double pressure = sanitize(m.getDouble("primary_pressure"), PRESSURE_MIN, PRESSURE_MAX);
Double flow = sanitize(m.getDouble("primary_flow"), FLOW_MIN, FLOW_MAX);
// 构造 RowData(字段顺序与 Iceberg 表 schema 对齐)
GenericRowData row = new GenericRowData(8);
row.setField(0, StringData.fromString(stationId));
row.setField(1, StringData.fromString(obj.getString("device_id")));
row.setField(2, StringData.fromString("PRIMARY_SUPPLY_TEMP"));
row.setField(3, supplyTemp); // null 表示野值
row.setField(4, obj.getIntValue("quality"));
row.setField(5, TimestampData.fromEpochMillis(eventTimeMs));
row.setField(6, TimestampData.fromEpochMillis(System.currentTimeMillis()));
return row;
}
private Double sanitize(Double val, double min, double max) {
if (val == null) return null;
return (val >= min && val <= max) ? val : null; // 超量程置 NULL
}
}
清洗策略选择:供热场景下,野值置 NULL 而非丢弃整条记录——因为一条消息里可能有 10 个指标,其中一个超量程不应影响其余 9 个。NULL 在 Doris 查询时可用
COALESCE或FILTER处理。
5.5 Watermark 与时间语义
供热数据存在网络延迟导致的事件时间乱序,用 BoundedOutOfOrderness(30s) 水位线策略——允许 30 秒乱序,超过 30 秒的迟到数据仍会写入(Iceberg Sink 不按 watermark 过滤),但基于 event_time 的窗口聚合(如有)会正确处理。
WatermarkStrategy.<RowData>forBoundedOutOfOrderness(Duration.ofSeconds(30))
.withTimestampAssigner((row, ts) ->
row.getTimestamp(5, 6).getMillisecond()) // event_time 字段
.withIdleness(Duration.ofMinutes(1)); // 防止空闲分区阻塞水位线
.withIdleness(1min) 解决一个问题:某些 station_id bucket 分区可能长时间无数据(非采暖季),会阻塞全局水位线推进。标记为 idle 后,水位线由活跃分区推进。
5.6 Iceberg Sink 配置
// 4. 写入 Iceberg
FlinkSink.forRowData(cleanedStream)
.tableLoader(tableLoader)
.set("write.target-file-size-bytes", String.valueOf(128 * 1024 * 1024)) // 128MB
.set("write.distribution-mode", "hash") // 按分区键 hash 分布到各 task
.set("write.parquet.compression-codec", "zstd")
.set("write.metadata.delete-after-commit.enabled", "true") // 提交后删旧 metadata
.set("write.metadata.metrics.default", "full") // 记录完整列统计
.append(); // 追加模式,不覆盖
关键参数解读:
| 参数 | 值 | 作用 |
|---|---|---|
write.target-file-size-bytes |
128MB | 目标文件大小,写入时持续追加直到达到此大小再滚动新文件 |
write.distribution-mode |
hash |
按 days(event_time)+bucket(station_id) 哈希,同一分区数据落同一 task,减少小文件 |
write.parquet.compression-codec |
zstd |
zstd 压缩率优于 snappy,解压速度也够快 |
write.metadata.metrics.default |
full |
在 manifest 中记录每列完整 min/max/null_count,最大化 Data Skipping 效果 |
5.7 Checkpoint 与 exactly-once 语义
Flink 写 Iceberg 的 exactly-once 语义不是 connector 开关,而是 Flink checkpointing 的函数。Iceberg sink 参与两阶段提交:
- 预提交:checkpoint 触发时,sink 把当前周期写入的 Parquet 文件标记为"待提交",文件已写到 MinIO 但未在 Iceberg 元数据中可见。
- 正式提交:所有算子 checkpoint 成功后,JobManager 协调提交,sink 把这批文件作为一个新快照写入 Iceberg metadata,数据对后续查询可见。
- 失败回滚:若 checkpoint 前失败,已写的文件成为孤儿文件(后续由
remove_orphan_files清理),Kafka offset 回滚到上次成功 checkpoint。
// 5. Checkpoint 配置
env.enableCheckpointing(5 * 60 * 1000); // 5 分钟一次
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(10 * 60 * 1000); // 10 分钟超时
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(60 * 1000); // 两次 checkpoint 间至少 1 分钟
env.getCheckpointConfig().setExternalizedCheckpointCleanup(
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); // 作业取消时保留 checkpoint
// 6. State Backend(RocksDB,支持大状态增量 checkpoint)
env.setStateBackend(new EmbeddedRocksDBStateBackend());
env.getCheckpointConfig().setCheckpointStorage("file:///opt/flink/checkpoints/");
5 分钟 checkpoint 间隔是供热场景的合理起点:间隔越短产生的小文件越多,间隔越长故障恢复时需重放的数据越多。供热数据量平稳,5 分钟重放约几十万条记录,恢复时间可接受。
5.8 小文件问题与治理
流式写入天生产生小文件——每个 checkpoint(5 分钟)每个分区至少一个文件。一个采暖季按天分区、24 个站点 bucket,一天理论上有 24 * 12 = 288 个文件,如果每文件才几 MB,查询规划时要扫描大量文件元数据,拖慢查询。
治理第一层:写入时控制。write.distribution-mode=hash 让同一分区数据落同一 task,target-file-size=128MB 让文件持续滚动到 128MB。正常流量下,一个 task 在一个 checkpoint 周期内能攒满 128MB(约 60 万条记录),不会产生小文件。低流量时段(深夜)可能攒不满,产生几 MB 的小文件。
治理第二层:Flink 原生 compaction。Iceberg 1.7 起,flink-iceberg-runtime 内置 compaction action,可在 Flink 作业内触发:
// 在 Flink 作业中定期触发 compaction(只针对冷分区)
Actions.forTable(table)
.rewriteDataFiles()
.targetFileSizeInBytes(128 * 1024 * 1024)
.filter(Expressions.lessThan("event_time",
currentHourMinus2Hours())) // 只 compact 2 小时前的冷分区
.execute();
治理第三层:Spark 集中 compaction。把 compaction 交给 Spark 定时作业统一处理(见第六节),Flink 作业专注写入。这是生产环境更常见的做法,避免 Flink 作业承担过多职责。
运维铁律:冷分区才 compaction
禁止 compact 当前正在接收流写的热分区——Flink 持有该分区的写锁,compaction 提交时触发 commit 冲突(OCC 乐观并发冲突),导致写入失败。compaction 只针对冷分区,即落后于流写边界 1 到 2 个周期的分区。供热数据按天分区,当天分区是热分区,compaction 只处理昨天及之前的分区。
5.9 Dynamic Sink 与 Schema 演进
Flink 1.20/2.0/2.1 配合 Iceberg 1.10+ 的 Dynamic Iceberg Sink 提供三大能力:
- 自动 Schema 演进:遇到新字段自动调 catalog 加列,元数据级操作,老数据返回 NULL。
- 多表 fan-out:单个 sink 写多张表,按记录内的 routing key 路由。
- 自动建表:遇到未知 routing key 自动建表。
供热设备型号杂、字段增减频繁——新换一批热量表多了"瞬时功率"字段,Dynamic Sink 自动加列,无需停作业改 DDL。约束:仅支持 widening(加列、改名、int→long),不支持流式作业 drop 列。建议配合 Confluent Schema Registry 的 FULL_TRANSITIVE 兼容性规则,禁止破坏性变更。
5.10 Flink SQL 方式(替代 DataStream)
除了 DataStream API,也可用 Flink SQL 实现相同逻辑,适合简单场景:
-- 创建 Kafka 源表
CREATE TABLE kafka_scada_source (
station_id STRING,
device_id STRING,
metrics ROW<
primary_supply_temp DOUBLE,
primary_return_temp DOUBLE,
primary_pressure DOUBLE,
primary_flow DOUBLE,
heat_power DOUBLE
>,
quality INT,
event_time TIMESTAMP(6),
ingest_time TIMESTAMP(6),
WATERMARK FOR event_time AS event_time - INTERVAL '30' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'heat.scada.station_metric',
'properties.bootstrap.servers' = 'kafka:9092',
'properties.group.id' = 'flink-scada-sql',
'scan.startup.mode' = 'group-offsets',
'format' = 'json'
);
-- 创建 Iceberg 目标表(通过 REST Catalog)
CREATE CATALOG heat_catalog WITH (
'type' = 'iceberg',
'catalog-impl' = 'org.apache.iceberg.rest.RESTCatalog',
'uri' = 'http://rest:8181',
'warehouse' = 's3://warehouse/',
'io-impl' = 'org.apache.iceberg.aws.s3.S3FileIO',
's3.endpoint' = 'http://minio:9000',
's3.access-key-id' = 'heat_admin',
's3.secret-access-key' = '<密码>',
's3.path-style-access' = 'true'
);
-- 展平 metrics 并写入 Iceberg
INSERT INTO heat_catalog.ods.scada_metric_flat
SELECT
station_id, device_id,
metrics.primary_supply_temp AS supply_temp,
metrics.primary_return_temp AS return_temp,
metrics.primary_pressure AS pressure,
metrics.primary_flow AS flow,
metrics.heat_power AS heat_power,
quality, event_time, ingest_time
FROM kafka_scada_source
WHERE metrics.primary_supply_temp BETWEEN -30 AND 150 -- 去野值
AND metrics.primary_pressure BETWEEN 0 AND 2.5;
DataStream API 适合复杂清洗逻辑(多指标独立校验、UDF 复用),Flink SQL 适合简单过滤和字段映射。生产环境按场景选择。
六、Spark 批处理与表维护详解
Spark 承担两类工作:批 ETL 加工(ODS→DWD→DWS→ADS)和 Iceberg 表维护(小文件合并、快照过期、孤儿文件清理)。它是对 Iceberg 支持最完整的引擎,DDL/DML、Time Travel、维护存储过程一应俱全。
6.1 SparkSession 配置
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("heat-lakehouse-etl") \
.config("spark.sql.extensions",
"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.heat_catalog",
"org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.heat_catalog.type", "rest") \
.config("spark.sql.catalog.heat_catalog.uri", "http://rest:8181") \
.config("spark.sql.catalog.heat_catalog.warehouse", "s3://warehouse/") \
.config("spark.sql.catalog.heat_catalog.io-impl",
"org.apache.iceberg.aws.s3.S3FileIO") \
.config("spark.sql.catalog.heat_catalog.s3.endpoint",
"http://minio:9000") \
.config("spark.sql.catalog.heat_catalog.s3.access-key-id", "heat_admin") \
.config("spark.sql.catalog.heat_catalog.s3.secret-access-key", "<密码>") \
.config("spark.sql.catalog.heat_catalog.s3.path-style-access", "true") \
.config("spark.sql.defaultCatalog", "heat_catalog") \
.config("spark.sql.adaptive.enabled", "true") \
.config("spark.sql.adaptive.coalescePartitions.enabled", "true") \
.getOrCreate()
IcebergSparkSessionExtensions 注册 Iceberg 的 DDL/DML 扩展(如 CALL system.rewrite_data_files),adaptive.enabled 开启 AQE 自适应执行,自动合并小分区。
Maven 依赖需与 Spark/Scala 版本严格匹配:
<!-- Spark 3.5 + Scala 2.12 -->
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-spark-runtime-3.5_2.12</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-aws-bundle</artifactId>
<version>1.5.0</version>
</dependency>
6.2 批 ETL:ODS → DWD(清洗标准化)
DWD 层把 ODS 的长表(一行一个指标)转换为宽表(一行包含一个站点一次采集的所有指标),并补充数据质量标记。
-- DWD: 换热站运行数据宽表(按站×分钟粒度)
INSERT INTO heat_catalog.dwd.station_metric_wide
SELECT
station_id,
device_id,
event_time,
-- 透视:把 metric_code 行转列
MAX(CASE WHEN metric_code = 'PRIMARY_SUPPLY_TEMP' THEN metric_value END) AS primary_supply_temp,
MAX(CASE WHEN metric_code = 'PRIMARY_RETURN_TEMP' THEN metric_value END) AS primary_return_temp,
MAX(CASE WHEN metric_code = 'SECONDARY_SUPPLY_TEMP' THEN metric_value END) AS secondary_supply_temp,
MAX(CASE WHEN metric_code = 'SECONDARY_RETURN_TEMP' THEN metric_value END) AS secondary_return_temp,
MAX(CASE WHEN metric_code = 'PRIMARY_PRESSURE' THEN metric_value END) AS primary_pressure,
MAX(CASE WHEN metric_code = 'PRIMARY_FLOW' THEN metric_value END) AS primary_flow,
MAX(CASE WHEN metric_code = 'SECONDARY_FLOW' THEN metric_value END) AS secondary_flow,
MAX(CASE WHEN metric_code = 'HEAT_POWER' THEN metric_value END) AS heat_power,
MAX(CASE WHEN metric_code = 'VALVE_OPENING' THEN metric_value END) AS valve_opening,
-- 供回水温差(衍生指标)
MAX(CASE WHEN metric_code = 'PRIMARY_SUPPLY_TEMP' THEN metric_value END)
- MAX(CASE WHEN metric_code = 'PRIMARY_RETURN_TEMP' THEN metric_value END) AS primary_temp_diff,
-- 数据质量:任一关键指标为 NULL 则标记 0
CASE WHEN
MAX(CASE WHEN metric_code = 'PRIMARY_SUPPLY_TEMP' THEN metric_value END) IS NULL
OR MAX(CASE WHEN metric_code = 'PRIMARY_FLOW' THEN metric_value END) IS NULL
THEN 0 ELSE 1
END AS data_quality_flag,
current_timestamp() AS etl_time
FROM heat_catalog.ods.scada_metric_raw
WHERE date(event_time) = date_sub(current_date(), 1) -- 处理前一天数据
GROUP BY station_id, device_id, event_time;
6.3 批 ETL:DWD → DWS(轻度聚合)
DWS 层把分钟级数据聚合成站日粒度,供能耗分析和报表使用:
-- DWS: 换热站能耗日表
INSERT INTO heat_catalog.dws.station_energy_daily
SELECT
station_id,
date(event_time) AS stat_date,
-- 温度统计
avg(primary_supply_temp) AS avg_supply_temp,
avg(primary_return_temp) AS avg_return_temp,
avg(primary_temp_diff) AS avg_temp_diff,
min(primary_supply_temp) AS min_supply_temp,
max(primary_supply_temp) AS max_supply_temp,
-- 流量与热量
avg(primary_flow) AS avg_flow,
sum(primary_flow * 60) AS daily_flow_volume, -- L/min × 60min = L/h → 累计
sum(heat_power * 60 / 1e6) AS daily_heat_gj, -- W × 60s / 1e6 = GJ
-- 运行时长(有数据的小时数)
count(DISTINCT hour(event_time)) AS running_hours,
-- 数据完整率(有效记录数 / 应有记录数 1440)
count(*) / 1440.0 AS data_completeness
FROM heat_catalog.dwd.station_metric_wide
WHERE date(event_time) = date_sub(current_date(), 1)
AND data_quality_flag = 1
GROUP BY station_id, date(event_time);
隐藏分区让这种按日查询极其高效——Iceberg 自动只扫描前一天分区的数据文件,无需全表扫描。
6.4 批 ETL:DWS → ADS(应用指标)
ADS 层面向具体业务场景,如室温达标率、单耗排名:
-- ADS: 室温达标率(室温 ≥ 18℃ 视为达标)
INSERT INTO heat_catalog.ads.room_temp_compliance
SELECT
date(event_time) AS stat_date,
station_id,
count(*) AS total_records,
count(CASE WHEN room_temp >= 18.0 THEN 1 END) AS compliant_records,
round(count(CASE WHEN room_temp >= 18.0 THEN 1 END) * 100.0 / count(*), 2) AS compliance_rate,
avg(room_temp) AS avg_room_temp
FROM heat_catalog.ods.room_temp_raw
WHERE date(event_time) = date_sub(current_date(), 1)
GROUP BY date(event_time), station_id;
6.5 表维护操作详解
表维护是 Spark 最不可替代的职责。Flink 流写积累的小文件、过期快照、孤儿文件,都需要 Spark 定期清理。
操作一:小文件合并(rewrite_data_files)
两种策略。bin-pack 是简单合并,不改变数据顺序;Z-order 按多列重排,提升多维查询的 Data Skipping 命中率。
-- bin-pack 合并(默认策略,速度快)
CALL system.rewrite_data_files(
table => 'heat_catalog.ods.scada_metric_raw',
options => map(
'target-file-size-bytes', '134217728', -- 128MB
'min-input-files', '5', -- 至少 5 个小文件才合并
'min-file-size-bytes', '10485760' -- 小于 10MB 视为小文件
)
);
-- Z-order 重排(按 station_id + event_time 联合排序)
CALL system.rewrite_data_files(
table => 'heat_catalog.ods.scada_metric_raw',
options => map(
'strategy', 'sort',
'sort-order', 'zorder(station_id, event_time)',
'target-file-size-bytes', '134217728'
)
);
Z-order 把多列值映射到空间填充曲线,使同时按 station_id 和 event_time 过滤的查询能跳过更多文件。对供热"查某站某天数据"这类典型查询,Z-order 后 Data Skipping 命中率可从 60% 提升到 95%。
操作二:快照过期(expire_snapshots)
每次 Flink checkpoint 产生一个快照,时间久了快照和对应的历史数据文件会占用大量空间。过期旧快照释放存储:
-- 过期 30 天前的快照(保留最近 30 天用于 Time Travel 回溯)
CALL system.expire_snapshots(
table => 'heat_catalog.ods.scada_metric_raw',
older_than => TIMESTAMP '2026-05-28 00:00:00',
retain_last => 10 -- 至少保留最近 10 个快照
);
操作三:孤儿文件清理(remove_orphan_files)
失败写入、compaction 前的旧文件不被任何快照引用,成为孤儿文件。定期清理:
CALL system.remove_orphan_files(
table => 'heat_catalog.ods.scada_metric_raw',
older_than => TIMESTAMP '2026-06-26 00:00:00' -- 只删 24 小时前的,避免删到正在写的
);
操作四:manifest 合并(rewrite_manifests)
频繁写入导致 manifest 文件碎片化,查询时要读大量 manifest。合并 manifest 提升查询规划速度:
CALL system.rewrite_manifests('heat_catalog.ods.scada_metric_raw');
6.6 表维护调度方案
把上述操作编排成每日定时任务,凌晨低峰期执行:
#!/bin/bash
# /opt/heat/jobs/daily_maintenance.sh — 每天凌晨 2 点执行
TODAY=$(date +%Y-%m-%d)
YESTERDAY=$(date -d "yesterday" +%Y-%m-%d)
THIRTY_DAYS_AGO=$(date -d "30 days ago" +%Y-%m-%d)
spark-sql --master yarn --name "iceberg-maintenance" <<EOF
-- 1. 合并前天及更早的冷分区小文件(Z-order)
CALL system.rewrite_data_files(
table => 'heat_catalog.ods.scada_metric_raw',
options => map('strategy','sort','sort-order','zorder(station_id, event_time)')
);
-- 2. DWS/DWD 层 bin-pack 合并
CALL system.rewrite_data_files('heat_catalog.dwd.station_metric_wide');
CALL system.rewrite_data_files('heat_catalog.dws.station_energy_daily');
-- 3. 过期 30 天前的快照
CALL system.expire_snapshots('heat_catalog.ods.scada_metric_raw',
TIMESTAMP '${THIRTY_DAYS_AGO} 00:00:00', 10);
-- 4. 清理孤儿文件(24 小时前)
CALL system.remove_orphan_files(table => 'heat_catalog.ods.scada_metric_raw',
older_than => TIMESTAMP '${YESTERDAY} 00:00:00');
-- 5. 合并 manifest
CALL system.rewrite_manifests('heat_catalog.ods.scada_metric_raw');
EOF
用 crontab 每天凌晨 2 点调度:0 2 * * * /opt/heat/jobs/daily_maintenance.sh。
6.7 监控表健康度
Iceberg 提供元数据表,用于监控表健康度:
-- 查看快照历史
SELECT snapshot_id, committed_at, operation, summary
FROM heat_catalog.ods.scada_metric_raw.snapshots
ORDER BY committed_at DESC LIMIT 10;
-- 查看数据文件分布(识别小文件问题)
SELECT
count(*) AS file_count,
avg(file_size_in_bytes) AS avg_size_mb,
max(file_size_in_bytes) AS max_size_mb,
min(file_size_in_bytes) AS min_size_mb
FROM heat_catalog.ods.scada_metric_raw.files
WHERE partition.event_time_day = '${YESTERDAY}';
-- 查看分区数据量
SELECT partition.event_time_day, file_count, record_count, total_data_file_size_in_bytes
FROM heat_catalog.ods.scada_metric_raw.partitions
ORDER BY partition.event_time_day DESC LIMIT 7;
当 avg_size_mb 明显小于 128MB 时,说明小文件问题严重,需触发 compaction。
七、Doris 查询服务详解
Doris 是整个架构面向业务的"门面"。它本身不存湖里的明细数据,而是通过 Multi-Catalog 直接读取 MinIO 上的 Iceberg 表,再辅以物化视图和本地缓存把查询性能拉到交互式水平。
7.1 Doris 集群规划
中型供热企业建议 3 节点 Doris 集群(1 FE + 3 BE 或 3 FE+BE 混合),每节点 16C/64G/1TB SSD。FE 负责元数据和查询解析,BE 负责数据存储和计算。BE 的本地 SSD 用作 Iceberg 数据的查询缓存。
7.2 创建 Iceberg Catalog
-- 创建 Iceberg Catalog(REST Catalog + MinIO)
CREATE CATALOG iceberg PROPERTIES (
'type' = 'iceberg',
'iceberg.catalog.type' = 'rest',
'warehouse' = 's3://warehouse/',
'uri' = 'http://rest:8181',
's3.access_key' = 'heat_admin',
's3.secret_key' = '<密码>',
's3.endpoint' = 'http://minio:9000',
's3.region' = 'us-east-1'
);
-- 验证:列出 Iceberg 中的数据库和表
SWITCH iceberg;
SHOW DATABASES; -- 应看到 ods, dwd, dws, ads, dim
USE ods;
SHOW TABLES; -- 应看到 scada_metric_raw 等
创建后,Doris 能像查内表一样查 Iceberg 表,数据仍在 MinIO,不搬迁。这是"湖仓一体"最直接的体现——湖是仓的存储,仓是湖的查询加速器。
7.3 直接查询 Iceberg 表
-- 切回 internal catalog 做跨源查询
SWITCH internal;
-- 查询 Iceberg 湖中的 DWS 日表(直读,无加速)
SELECT station_id, stat_date, avg_supply_temp, daily_heat_gj
FROM iceberg.dws.station_energy_daily
WHERE stat_date = '2026-01-15'
ORDER BY daily_heat_gj DESC
LIMIT 20;
首次查询会从 MinIO 拉取 Parquet 文件到 BE 本地缓存(LRU),后续查询命中缓存。直读 Iceberg 适合低频的探索性查询,高频查询需要物化视图加速。
7.4 物化视图:透明加速
直读 Iceberg 解决了"能不能查",但实时监控大屏每秒刷新、能耗报表秒级响应,需要物化视图把热点查询结果预计算并缓存到 Doris 内部高性能列存。
创建物化视图(基于 Iceberg 湖表):
-- 物化视图:换热站实时温度(从 ODS 直读加速)
CREATE MATERIALIZED VIEW mv_station_realtime_temp
DISTRIBUTED BY HASH(station_id) BUCKETS 16
REFRESH ASYNC EVERY 1 MINUTE -- 每分钟刷新
PROPERTIES (
'replication_num' = '2'
)
AS
SELECT
station_id,
event_time,
primary_supply_temp,
primary_return_temp,
primary_pressure,
primary_flow
FROM iceberg.dwd.station_metric_wide
WHERE event_time >= now() - INTERVAL '1' HOUR; -- 只缓存最近 1 小时
物化视图:能耗日表汇总(从 DWS 加速):
CREATE MATERIALIZED VIEW mv_energy_daily_topn
DISTRIBUTED BY HASH(stat_date) BUCKETS 3
REFRESH ASYNC EVERY 1 HOUR -- 每小时刷新
PROPERTIES ('replication_num' = '2')
AS
SELECT
stat_date,
station_id,
avg_supply_temp,
daily_heat_gj,
data_completeness,
-- 单方能耗(GJ/㎡,需关联维度表)
daily_heat_gj / area_heated AS unit_heat_consumption
FROM iceberg.dws.station_energy_daily d
JOIN internal.dim.dim_station s ON d.station_id = s.station_id
WHERE stat_date >= date_trunc(now(), 'month'); -- 本月数据
透明改写:业务侧无需改 SQL,Doris 优化器自动判断查询能否命中物化视图。原始查询:
SELECT station_id, avg_supply_temp
FROM iceberg.dwd.station_metric_wide
WHERE event_time >= now() - INTERVAL '30' MINUTE;
优化器自动改写为查询 mv_station_realtime_temp,性能从秒级降到毫秒级。在 1TB TPCDS(Iceberg)基准上,Doris 99 个查询总运行时间仅为 Trino 的 1/3。
7.5 物化视图刷新策略
| 策略 | 语法 | 适用场景 |
|---|---|---|
| 定时全量刷新 | REFRESH ASYNC EVERY 1 HOUR |
数据量小、全量重算成本低 |
| 定时增量刷新 | REFRESH ASYNC EVERY 5 MINUTE + 分区过滤 |
大表按时间分区,只刷新新分区 |
| 手动触发 | REFRESH MATERIALIZED VIEW mv_name |
一次性补数据 |
增量刷新是关键——物化视图定义中的 WHERE event_time >= now() - INTERVAL '1' HOUR 让 Doris 只刷新最近一小时的新数据,而非全量重算。
7.6 联邦查询
Doris 作为统一 SQL 引擎,可建多个 Catalog,跨源 JOIN。维度表(用户档案、设备台账、气象)留在 MySQL,明细时序进湖,查询时按需关联:
-- 创建 MySQL Catalog(维度数据源)
CREATE CATALOG mysql_dim PROPERTIES (
'type' = 'jdbc',
'user' = 'readonly',
'password' = '<密码>',
'jdbc_url' = 'jdbc:mysql://mysql:3306/heat_dim',
'driver_url' = 'mysql-connector-java-8.0.30.jar',
'driver_class' = 'com.mysql.cj.jdbc.Driver'
);
-- 跨源 JOIN:湖中运行数据 + MySQL 用户档案
SELECT
s.station_id,
u.customer_name,
u.building_name,
s.avg_supply_temp,
s.daily_heat_gj
FROM iceberg.dws.station_energy_daily s
JOIN mysql_dim.heat_customer u ON s.station_id = u.bind_station
WHERE s.stat_date = current_date()
ORDER BY s.daily_heat_gj DESC;
这种联邦能力让供热平台无需把所有数据都搬到湖里——维度表频繁变更且数据量小,留在业务库更合适;明细时序数据量大且只追加,进湖更划算。
7.7 数据写回 Iceberg
Doris 也可直接在 Iceberg 中建表写数据,配合 Job Scheduler 定时加工入库,形成湖仓处理闭环:
-- 在 Iceberg 中建表
CREATE TABLE iceberg.ads.load_forecast_result (
forecast_date DATE,
station_id STRING,
predicted_load_gj DOUBLE,
confidence DOUBLE,
model_version STRING,
forecast_time TIMESTAMP
) PARTITIONED BY (days(forecast_date));
-- 把 Doris 内部计算的结果写回 Iceberg
INSERT INTO iceberg.ads.load_forecast_result
SELECT
date_add(current_date(), 1) AS forecast_date,
station_id,
predicted_load_gj,
confidence,
'v2.1' AS model_version,
current_timestamp() AS forecast_time
FROM internal.ads.load_forecast_model_output
WHERE forecast_date = date_add(current_date(), 1);
7.8 Doris 版本与 Iceberg SDK 对应
Doris 不同版本绑定的 Iceberg SDK 不同,直接影响对 Iceberg 特性的支持:
| Doris 版本 | Iceberg SDK | 关键支持 |
|---|---|---|
| 2.1 | 1.6.1 | Iceberg V1/V2 表查询、Position/Equality Delete |
| 3.0 | 1.6.1 | 同 2.1,稳定性增强 |
| 3.1 | 1.9.1 | 原生支持 Iceberg Branches/Tags、系统表 |
| 4.0 | 1.9.1 | Deletion Vector(4.1.0+) |
7.9 查询性能优化建议
- 本地缓存:BE 的
file_cache_path配置 SSD 缓存目录,容量建议为热数据量的 10%~20%。首次查询从 MinIO 拉取,后续命中本地缓存。 - 限制扫描量:对 Iceberg 外表查询务必带分区过滤条件(
WHERE event_time >= ...),否则会全表扫描。 - 物化视图覆盖热点:监控大屏、日报表等高频查询建物化视图,探索性查询直读 Iceberg。
- 资源隔离:用 Doris 资源组(Resource Group)把交互式查询和批加工隔离,避免批作业影响大屏响应。
八、供热数据建模与存储设计
8.1 数据规模参考
下表是几家代表性供热企业的规模,可作为容量规划参考:
| 企业 | 换热站数量(座) | 供热用户(万户) | 备注 |
|---|---|---|---|
| 济南能源 | 4,536 | 258 | 44 处热源、132 台锅炉,管网 11958 公里 |
| 威海热电 | 1,700 | 89.6 | 近 5 采暖季 8.4 亿条历史数据,3.3 万栋楼 |
| 洛阳热力 | — | 45 | 实际 3800 万㎡,入网 6150 万㎡,957 个小区 |
| 国家电投河北 | 470 | 30 | 3911 万㎡,1.4 万台室温采集装置 |
一家覆盖三千万平米、四五百座换热站、三四十万用户的中型供热企业,每个采暖季(约 4 个月)产生数十亿条时序记录。按分钟级采集、每条记录若干浮点指标,单采暖季明细数据压缩后约几十 GB 到上百 GB;留存五年,湖中明细层规模在 TB 级。
8.2 数据分层设计
所有层都落在 Iceberg 表中,按数仓经典分层组织:
| 分层 | 内容 | 来源 / 加工 | 典型表 |
|---|---|---|---|
| ODS | 原始时序与业务明细 | Flink 从 Kafka 实时写入 | scada_metric_raw、heat_meter_raw、room_temp_raw |
| DWD | 清洗标准化明细(宽表) | Spark 批 ETL | station_metric_wide、heat_meter_clean |
| DWS | 轻度聚合汇总(站日/用户月) | Spark 批 ETL | station_energy_daily、customer_heat_monthly |
| ADS | 面向应用指标 | Spark/Doris 加工 | room_temp_compliance、load_forecast_result |
| DIM | 维度表 | 业务库 CDC / 手工维护 | dim_station、dim_customer、dim_weather |
8.3 ODS 层表 DDL(SCADA 时序)
CREATE TABLE heat_catalog.ods.scada_metric_raw (
station_id STRING, -- 换热站编号
device_id STRING, -- 设备编号
metric_code STRING, -- 指标码: PRIMARY_SUPPLY_T/PRIMARY_RETURN_T/...
metric_value DOUBLE, -- 采集值(野值置 NULL)
quality INT, -- 数据质量位掩码
event_time TIMESTAMP(6), -- 采集时间(事件时间)
ingest_time TIMESTAMP(6) -- 入湖时间
)
PARTITIONED BY (days(event_time), bucket(16, station_id))
TBLPROPERTIES (
'write.format.default' = 'parquet',
'write.parquet.compression-codec' = 'zstd',
'write.target-file-size-bytes' = '134217728', -- 128MB
'write.metadata.metrics.default' = 'full', -- 完整列统计
'format-version' = '2' -- V2 表,支持行级删除
);
设计要点:
- 双级分区:
days(event_time)方便按日裁剪与生命周期管理;bucket(16, station_id)哈希分桶,避免单时间分区下所有站点数据挤进少数大文件,同时让按站点的查询能进一步裁剪。 - 隐藏分区:用户查询只写
WHERE event_time BETWEEN ... AND station_id = ...,Iceberg 自动推导分区值做裁剪,无需感知物理分区结构。 - format-version=2:启用 Iceberg V2 表,支持行级删除(Position Delete / Equality Delete),便于后续 upsert 修正。
- metrics=full:在 manifest 中记录每列完整 min/max/null_count,最大化 Data Skipping 效果。
8.4 DWS 层表 DDL(能耗日表)
CREATE TABLE heat_catalog.dws.station_energy_daily (
station_id STRING,
stat_date DATE,
avg_supply_temp DOUBLE,
avg_return_temp DOUBLE,
avg_temp_diff DOUBLE,
min_supply_temp DOUBLE,
max_supply_temp DOUBLE,
avg_flow DOUBLE,
daily_flow_volume DOUBLE, -- 日累计流量(L)
daily_heat_gj DOUBLE, -- 日供热量(GJ)
running_hours INT, -- 运行时长
data_completeness DOUBLE, -- 数据完整率
etl_time TIMESTAMP(6)
)
PARTITIONED BY (days(stat_date))
TBLPROPERTIES (
'write.parquet.compression-codec' = 'zstd',
'write.target-file-size-bytes' = '134217728',
'format-version' = '2'
);
8.5 分区演进
供热有明显的采暖季周期,跨季数据量差异巨大。采暖季内按天分区足够,但跨年历史数据想改成按月分区以减少元数据膨胀。Iceberg 分区演进让新旧方案共存,无需重写历史数据:
-- 历史数据增加月分区(新数据仍按天,历史数据按月共存)
ALTER TABLE heat_catalog.ods.scada_metric_raw
ADD PARTITION FIELD months(event_time);
查询计划自动按快照分割——旧快照的数据用天分区裁剪,新快照的数据用月分区裁剪。这种"零停机演进"对供热 7×24 小时运行的业务至关重要。
8.6 生命周期管理
不同分层保留不同时长,平衡存储成本与回溯需求:
| 分层 | 保留时长 | 过期策略 |
|---|---|---|
| ODS | 1 年(明细) | 每月 expire_snapshots + 删除 1 年前分区 |
| DWD | 2 年 | 每月删除 2 年前分区 |
| DWS | 5 年 | 每年归档 5 年前数据到冷存储 |
| ADS | 3 年 | 每年清理 |
| DIM | 永久 | 维度表小,不清理 |
-- 删除 1 年前的 ODS 分区
ALTER TABLE heat_catalog.ods.scada_metric_raw
DROP PARTITION FIELD days(event_time);
-- 或用 Spark 批量删除旧分区数据
DELETE FROM heat_catalog.ods.scada_metric_raw
WHERE event_time < TIMESTAMP '2025-01-01 00:00:00';
九、端到端流程串讲
把前面各节拼起来,按时间线走一遍一个完整的数据周期。
9.1 实时链路(持续运行)
- 换热站 PLC 按分钟级轮询传感器,经 4G 推送到 SCADA 前置机。
- 前置机把数据标准化为 JSON,通过 Kafka Producer 推送到
heat.scada.station_metrictopic(24 分区)。 - Flink 作业消费 Kafka,反序列化为 RowData,执行清洗 UDF(去野值、质量标记)。
- Watermark 策略
BoundedOutOfOrderness(30s)处理乱序数据。 - Iceberg Sink 按
write.distribution-mode=hash把数据按分区键分布到各 task,每个 task 持续写入 Parquet 文件到 MinIO。 - 每 5 分钟一次 checkpoint:sink 把本周期写入的文件作为新快照提交到 Iceberg metadata,数据对 Doris 可见。
- Doris 通过 Iceberg Catalog 实时看到新快照,监控大屏查询最新数据。
9.2 离线链路(每日定时)
- 凌晨 2 点,Spark 作业启动,从 ODS 读取前一天数据。
- 执行 ODS→DWD 转换(长表转宽表,补充质量标记),写入 DWD 层。
- 执行 DWD→DWS 聚合(站日粒度能耗指标),写入 DWS 层。
- 执行表维护:Z-order 合并前天冷分区小文件、过期 30 天前快照、清理孤儿文件、合并 manifest。
- 周末/月末执行 DWS→ADS 加工,生成达标率、负荷预测结果。
9.3 查询服务(按需)
- 实时监控大屏:查询物化视图
mv_station_realtime_temp(每分钟刷新),毫秒级响应。 - 能耗分析报表:查询 DWS 日表,直读 Iceberg 或命中物化视图
mv_energy_daily_topn。 - 负荷预测:读 ADS 预测结果表,Doris 内部模型计算后写回 Iceberg。
- 维度关联:联邦查询 Iceberg 湖表 + MySQL 维表,无需数据搬迁。
9.4 实时与离线的边界
实时链路只负责把数据尽快、准确地落到 ODS 层,不做重计算;离线链路负责把 ODS 加工成有业务意义的 DWS/ADS,并维护表的健康度。Doris 不搬运数据,只加速查询。三者各司其职,是这套架构能同时满足"实时"和"全局分析"的根本。
十、版本选型与兼容性
这套多组件架构最大的工程风险是版本错配。下表是 2026 年生产环境推荐的版本组合:
| 组件 | 推荐版本 | 对应 Iceberg | 关键说明 |
|---|---|---|---|
| MinIO | 最新 RELEASE | — | 纯本地部署,S3FileIO 对接 |
| Apache Iceberg | 1.5.x / 1.6.x | — | 与 Doris 2.1 SDK 对齐 |
| Flink | 1.19 / 1.20 | 1.5+(iceberg-flink-runtime-1.19) | DataStream + Dynamic Sink |
| Spark | 3.5 | 1.5+(iceberg-spark-runtime-3.5_2.12) | 批 ETL + 表维护 |
| Doris | 2.1.x(稳) | 1.6.1 | Multi-Catalog + 物化视图 |
求稳组合:Doris 2.1 + Iceberg 1.5.0 + Flink 1.19 + Spark 3.5,经过大量生产验证,社区资料最全。
追新组合:Doris 3.1 + Iceberg 1.10 + Flink 2.1(Dynamic Sink)+ Spark 4.0,能享受自动 Schema 演进、多表 fan-out、Iceberg Branches/Tags 等新特性,但需承担早期版本磨合成本。供热行业对稳定性要求高,建议首期上稳,二期再迭代。
十一、运维治理与落地步骤
11.1 表健康度治理
Iceberg 表会随时间积累三类"债务":小文件、旧快照、孤儿文件。每天凌晨由 Spark 跑一遍维护脚本(见 6.6 节)。用元数据表监控健康度(见 6.7 节),当 avg_size_mb 明显小于 128MB 时触发额外 compaction。
11.2 流写与 compaction 的协调
Flink 持续写热分区,Spark compaction 必须只动冷分区,否则触发 commit 冲突。落地时把"流写水位线"显式记录下来(如写入一张元数据表),compaction 任务只处理水位线之前 1 到 2 个周期的分区。供热数据按天分区,当天分区是热分区,compaction 只处理昨天及之前。
11.3 Schema 演进管控
供热设备字段增减频繁,自动 Schema 演进方便但容易失控。建议在 Schema Registry 启用 FULL_TRANSITIVE 兼容性规则,禁止破坏性变更(删列、改类型)。所有 schema 变更留痕,便于回溯。
11.4 落地三步走
第一步:打底。搭好 MinIO + REST Catalog + Iceberg 存储底座,跑通 Spark 读写一张表的闭环。验证存储层可靠性。
第二步:通流。接入 Kafka + Flink 实时入湖一条链路(先选 SCADA 时序),打通 ODS 层。Doris 接 Iceberg Catalog 做直读验证。验证实时写入与查询闭环。
第三步:成体系。补齐 DWD/DWS/ADS 分层、物化视图、表维护调度、联邦查询。把能耗分析、负荷预测等业务场景逐个挂上去。
每一步对应一个可验收里程碑:存储闭环、流查闭环、业务闭环。供热业务有天然的非采暖季窗口——每年 4 到 10 月系统负载低、可停机窗口多,是新功能验证与版本升级的最佳时机。把重大变更排在非采暖季,采暖季只做监控与必要修复,是行业里普遍遵循的节奏。
回看整条路径,供热行业的湖仓一体化落地,本质上是用"对象存储 + 开放表格式"这层抽象,把过去散落在关系库、时序库、文件系统里的供热数据收敛成一份可被多引擎共享的资产。MinIO 解决低成本留存,Iceberg 解决表语义与事务,Flink 解决实时入湖,Spark 解决批加工与表维护,Doris 解决交互式查询与业务服务。五者各司其职,共同构成一个能同时扛住秒级写入与五年回溯、实时监控与全局分析的本地数据底座。
参考资料
[^1]: 中国城镇供热协会,T/PPZL 029—2024《城市智慧供热技术规范》。规定数据采集频率、精度、延迟与存储期限等权威技术参数。 https://m.book118.com/html/2026/0403/7164022053011066.shtm
[^2]: 行业分析与企业案例汇编,智慧供热平台现状与数据规模。含益和热力、威海热电、国家电投河北公司等企业数据量级与性能对比。 https://jishuzhan.net/article/1986605119983648769
[^3]: MinIO 官方博客,The Definitive Guide to Lakehouse Architecture with Iceberg and AIStor。MinIO + Iceberg 湖仓架构、S3FileIO、REST Catalog 最佳实践。 https://www.min.io/blog/the-definitive-guide-to-lakehouse-architecture-with-iceberg-and-aistor
[^4]: Streaming Lakehouse Architectures with Kafka, Iceberg and Flink。Flink + Iceberg exactly-once 语义与乐观并发控制原理。 https://ijareeie.com/upload/2023/november/13_Streaming Lakehouse Architectures with Apache Kafka, Apache Iceberg, and Flink Achieving Exactly-Once Semantics and Sub-Second Latency in Unified Batch-Stream Pipelines.pdf
[^5]: Apache Doris 官方文档,湖仓一体概述(2.1)。Multi-Catalog、物化视图透明改写、联邦查询、TPCDS 性能对比。 https://doris.apache.org/zh-CN/docs/2.1/lakehouse/lakehouse-overview/
[^6]: MinIO 官方博客,Building Modern Data Architectures with Iceberg, Tabular and MinIO。S3FileIO 与 Hadoop file-io 对比及配置要点。 https://www.min.io/blog/modern-data-architectures-with-iceberg-and-tabular
[^7]: Real-Time Lakehouse Patterns with Apache Flink and Iceberg(2026-05)。Dynamic Iceberg Sink、checkpoint、compaction 与冷分区铁律。 https://iceberglakehouse.com/posts/2026-05-24-real-time-lakehouse-flink/
[^8]: Apache Spark and Apache Iceberg。Spark 读写 Iceberg、rewrite_data_files、Z-order、表维护存储过程语法。 https://iceberglakehouse.com/iceberg/spark-apache-iceberg/
[^9]: Apache Iceberg 官方,Multi-Engine Support。Spark/Flink/Hive 版本生命周期与 Iceberg runtime jar 对应矩阵。 https://apache.github.io/iceberg/multi-engine-support/
[^10]: Apache Doris 官方文档,Iceberg Catalog(2.1)。Doris 对接 MinIO/HMS/REST 的配置、功能矩阵与 SDK 版本对应。 https://doris.apache.org/zh-CN/docs/2.1/lakehouse/catalogs/iceberg-catalog/
[^11]: Dremio 博客,What’s New in Apache Iceberg 1.10.0。Iceberg 1.10 对 Spark 4.0 与 Flink 2.0 的新增支持。 https://www.dremio.com/blog/whats-new-in-apache-iceberg-1-10-0-and-what-comes-next/
评论区