



基于 Apache Flink 2.2.0(2025 年 12 月发布的最新稳定版)撰写,覆盖 2.x 系列核心特性与生产实践。

一、认识 Flink:实时计算的新时代
Apache Flink 是一个开源的流式处理框架,用于对无界和有界数据流进行有状态计算。它把"流"当作数据处理的基本抽象——批处理只是流处理的一个特例(有界流)。这种流批一体的设计,让 Flink 在实时数仓、实时风控、监控告警、机器学习特征工程等场景中成为主流选择。
Flink 1.0 时代奠定了"有状态流处理"的基础,实现了端到端 exactly-once 语义。2025 年 3 月发布的 Flink 2.0.0 是九年来首次大版本升级,标志着 Flink 进入云原生与 AI 融合的新阶段。随后 2.1.0(2025 年 7 月)引入 AI 模型管理与实时推理,2.2.0(2025 年 12 月)进一步加入向量检索、增强物化表与 Delta Join,使 Flink 从单纯的流处理引擎演进为统一的 Data + AI 平台。
Flink 2.x 解决了上一代的几个核心痛点:云原生环境下本地磁盘受限、大状态作业扩缩容慢、Checkpoint 长尾、流批开发割裂,以及 AI 推理难以直接嵌入实时管道。
为什么选择 Flink
与其他流处理系统相比,Flink 的差异化优势集中在四点:
- 真正的流式语义:逐条事件处理,亚秒级延迟,而非微批处理。
- 强大的状态管理:内置 Keyed State、算子状态,配合 Checkpoint 实现精确一次语义。
- 流批一体:同一套 API 和引擎同时处理实时流与离线批,降低开发与维护成本。
- AI 原生集成:2.x 系列直接在 SQL/Table API 中调用大模型推理与向量检索,打通实时数据到实时智能的链路。
二、核心概念与架构
在动手写代码之前,先理解 Flink 的几个关键概念,这会决定你后续阅读官方文档和排查问题的效率。
2.1 流与转换
Flink 程序的本质是:从一个或多个数据源(Source)读取数据流,经过一系列转换算子(Transformation)处理,最后写入数据汇(Sink)。每个转换把一个或多个 DataStream 变成新的 DataStream,形成一张有向无环图(DAG)。
一个 Flink 作业的代码结构几乎都是同一个套路:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 1. 读取数据源
DataStream<String> source = env.fromSource(...);
// 2. 数据转换
DataStream<String> result = source
.map(...)
.keyBy(...)
.process(...);
// 3. 写入数据汇
result.sinkTo(...);
// 4. 提交执行
env.execute("MyFlinkJob");
2.2 并行度与算子链
数据流被分成多个分区(Partition),每个算子有若干**并行子任务(Subtask)**处理对应分区。数据在算子之间通过几种方式分发:
| 分发策略 | 说明 |
|---|---|
| forward | 一对一传递,上下游并行度相同 |
| hash | 按 key 分区,keyBy 使用的策略 |
| rebalance | 轮询均匀分配 |
| broadcast | 广播到所有下游 |
| shuffle | 随机分配 |
为了减少线程切换和序列化开销,并行度相同且无重分区的相邻算子会被链接成**算子链(Operator Chaining)**运行在同一个线程里。这是 Flink 提升吞吐的重要优化。
2.3 运行时架构
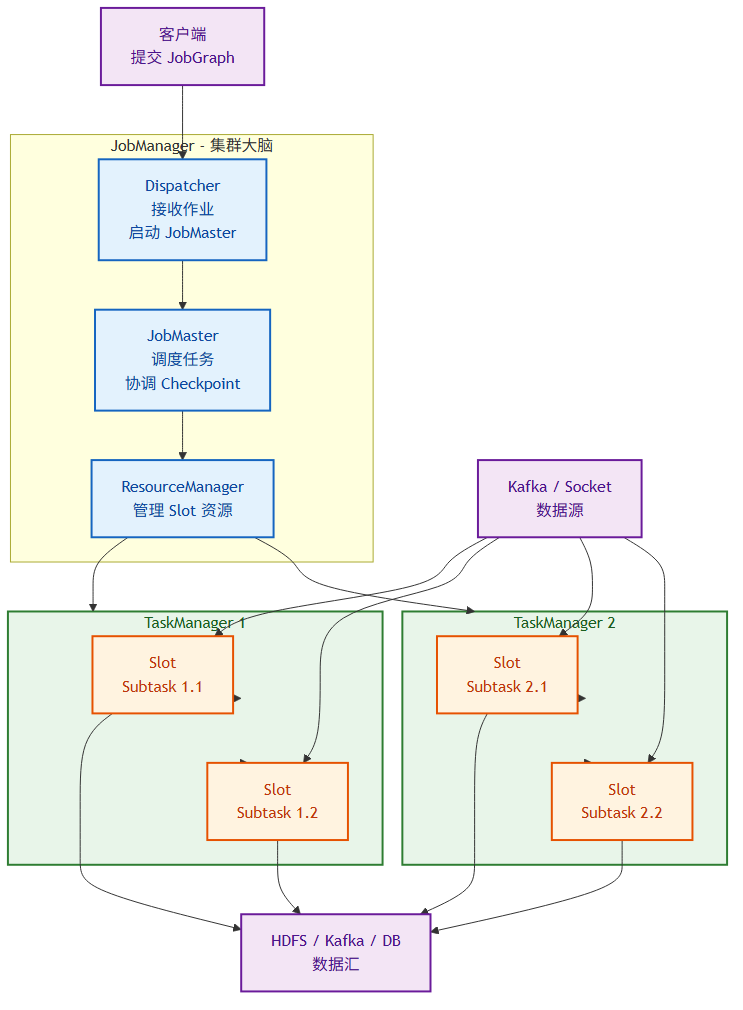
一个 Flink 集群在运行时由两类进程组成:
- JobManager:集群的"大脑",负责调度任务、协调 Checkpoint、故障恢复。包含 Dispatcher、ResourceManager 和 JobMaster 三个组件。
- TaskManager:实际执行工作的"工人",每个 TaskManager 拥有若干 Slot,每个 Slot 跑一个任务槽。TaskManager 之间通过数据传输层交换数据。
2.4 时间与水位线
时间语义是流处理区别于批处理的核心。Flink 支持三种时间:
- 事件时间(Event Time):数据本身携带的发生时间,结果确定性最高,是生产首选。
- 处理时间(Processing Time):算子处理数据的机器时间,延迟最低但不稳定。
- 摄入时间(Ingestion Time):数据进入 Flink 的时间,介于两者之间。
水位线(Watermark) 是事件时间的进度信号,告诉算子"不会再有早于这个时间的事件到来"。水位线由 Source 或算子生成,从上游向下游传播。它是窗口触发和迟到数据处理的关键机制。

三、环境搭建与第一个作业
3.1 准备工作
Flink 2.2 需要 Java 11 或 Java 17(推荐 17)。先确认环境:
java -version
# openjdk version "17.0.x"
3.2 下载与本地启动
从官网下载最新的二进制包(当前为 2.2.0 或 2.2.1):
# 下载并解压
tar -xzf flink-2.2.0-bin-scala_2.12.tgz
cd flink-2.2.0
启动一个本地集群:
./bin/start-cluster.sh
# 启动后访问 http://localhost:8081 查看 Web UI
停止集群:
./bin/stop-cluster.sh
3.3 创建 Maven 项目
官方提供 Maven 原型快速生成项目骨架:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=2.2.0
或者用快速启动脚本一键创建:
curl https://flink.apache.org/q/quickstart.sh | bash -s 2.2.0
生成的项目核心依赖如下(pom.xml 片段):
<properties>
<flink.version>2.2.0</flink.version>
<scala.binary.version>_2.12</scala.binary.version>
<java.version>11</java.version>
</properties>
<dependencies>
<!-- DataStream API -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- 客户端(本地执行与提交) -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- Kafka 连接器示例(需打进 fat jar) -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
核心说明:Flink API 依赖用
provided作用域,因为集群已提供这些库;连接器和第三方依赖才打进 fat jar。
3.4 第一个作业:词频统计
下面是一个完整的 DataStream 作业,从 socket 读取文本并统计词频:
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class WordCount {
public static void main(String[] args) throws Exception {
// 创建执行环境
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 从 socket 读取文本流
DataStream<String> text = env.socketTextStream("localhost", 9999);
// 拆词、分组、计数
DataStream<Tuple2<String, Integer>> counts = text
// 过滤空行
.filter(line -> !line.isEmpty())
// 按空格拆分,每个词映射为 (word, 1)
.flatMap((line, out) -> {
for (String word : line.toLowerCase().split("\\s+")) {
out.collect(Tuple2.of(word, 1));
}
})
.returns(Tuple2.class)
// 按单词分组(keyBy 的第一个字段)
.keyBy(value -> value.f0)
// 滚动求和
.sum(1);
counts.print();
env.execute("Socket WordCount");
}
}
运行方式:
# 终端 1:启动 socket 服务
nc -lk 9999
# 终端 2:运行作业(IDE 直接运行 main 方法即可)
# 然后在终端 1 输入文字,观察终端 2 输出
3.5 打包与提交
# 打包
mvn clean package
# 提交到本地集群
./bin/flink run target/your-job-0.1.jar
# 或通过 Web UI 上传 jar 提交
查看运行中的作业与取消:
./bin/flink list # 列出作业
./bin/flink cancel <jobId> # 取消作业
四、DataStream API 详解
DataStream API 是 Flink 最底层、最灵活的 API,适合需要精细控制(如自定义状态、定时器、复杂事件处理)的场景。
4.1 数据源(Source)
Flink 2.x 推荐使用新版 Source API(基于 Source 接口和 SourceFunction 已废弃)。常用数据源:
// 从集合创建(测试用)
DataStream<Event> events = env.fromCollection(eventList);
// 从文件创建(有界流,批模式)
DataStream<String> lines = env.readTextFile("file:///path/to/file");
// 从 Kafka 创建(最常用的实时源)
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("localhost:9092")
.setTopics("input-topic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(
kafkaSource,
WatermarkStrategy.noWatermarks(),
"kafka-source"
);
4.2 常用转换算子
| 算子 | 作用 | 示例 |
|---|---|---|
map |
一对一转换 | .map(s -> s.toUpperCase()) |
flatMap |
一对多转换 | .flatMap(...) |
filter |
过滤 | .filter(s -> s.length() > 0) |
keyBy |
按键分区 | .keyBy(e -> e.userId) |
reduce |
归约聚合 | .reduce((a, b) -> a.merge(b)) |
process |
最灵活的处理 | .process(new MyProcessFunction()) |
union |
合并多个流 | stream1.union(stream2) |
connect |
连接两个不同类型流 | stream1.connect(stream2) |
4.3 Keyed State:有状态计算的核心
keyBy 之后的算子可以访问键控状态(Keyed State),状态会随 Checkpoint 持久化,故障后自动恢复。Flink 提供几种状态原语:
public class CountAverage extends KeyedProcessFunction<String, Tuple2<String, Long>, Double> {
// 值状态:保存单个值
private ValueState<Long> countState;
// 列表状态:保存一组值
private ListState<Long> valuesState;
// 映射状态:键值对
private MapState<String, Long> mapState;
// 归约状态:自动归约
private ReducingState<Long> sumState;
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Long> countDesc =
new ValueStateDescriptor<>("count", Long.class);
countState = getRuntimeContext().getState(countDesc);
ListStateDescriptor<Long> valuesDesc =
new ListStateDescriptor<>("values", Long.class);
valuesState = getRuntimeContext().getListState(valuesDesc);
}
@Override
public void processElement(
Tuple2<String, Long> value,
Context ctx,
Collector<Double> out) throws Exception {
long count = countState.value() == null ? 0 : countState.value();
count++;
countState.update(count);
valuesState.add(value.f1);
// 计算平均值
long sum = 0;
for (Long v : valuesState.get()) {
sum += v;
}
out.collect((double) sum / count);
}
}
4.4 ProcessFunction 与定时器
ProcessFunction 是 DataStream API 中功能最强大的算子,可以访问状态、定时器、侧流输出。定时器是事件驱动应用(如超时检测、会话窗口)的关键工具:
public class TimeoutAlert extends KeyedProcessFunction<String, Order, Alert> {
private ValueState<Long> timerState;
@Override
public void open(Configuration cfg) {
timerState = getRuntimeContext().getState(
new ValueStateDescriptor<>("timer", Long.class));
}
@Override
public void processElement(Order order, Context ctx, Collector<Alert> out)
throws Exception {
// 注册一个 5 分钟后的定时器(基于事件时间)
long timeout = ctx.timestamp() + 5 * 60 * 1000L;
ctx.timerService().registerEventTimeTimer(timeout);
timerState.update(timeout);
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<Alert> out)
throws Exception {
// 定时器触发,说明 5 分钟内没有后续事件,发出告警
out.collect(new Alert(ctx.getCurrentKey(), "timeout"));
}
}
4.5 分流与合流
// 侧流输出:把不符合条件的数据分流到旁路
OutputTag<Order> lateTag = new OutputTag<Order>("late-orders"){};
SingleOutputStreamOperator<Order> mainStream = orders.process(
new ProcessFunction<Order, Order>() {
@Override
public void processElement(Order order, Context ctx, Collector<Order> out) {
if (order.isLate()) {
ctx.output(lateTag, order); // 发到侧流
} else {
out.collect(order); // 留在主流
}
}
});
// 获取侧流
DataStream<Order> lateStream = mainStream.getSideOutput(lateTag);
五、Table API 与 SQL 编程
Table API 与 SQL 是 Flink 的声明式 API,也是 2.x 系列功能演进的主战场。对大多数业务开发,SQL 是最高效的入口。
5.1 创建表环境
import org.apache.flink.table.api.*;
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode() // 或 inBatchMode()
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
5.2 用连接器定义表
通过 CREATE TABLE DDL 把外部系统映射成表:
-- 定义 Kafka 源表
CREATE TABLE orders (
order_id STRING,
user_id BIGINT,
amount DECIMAL(10, 2),
order_time TIMESTAMP(3),
-- 用 WATERMARK 定义事件时间和水位线策略
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'orders',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'order-group',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
-- 定义 MySQL 结果表
CREATE TABLE order_stats (
user_id BIGINT,
total_amt DECIMAL(10, 2),
cnt BIGINT,
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/report',
'table-name' = 'order_stats',
'username' = 'root',
'password' = 'pwd'
);
5.3 连续查询
流式 SQL 中的查询是连续查询——随着新数据到来不断更新结果:
-- 实时统计每个用户的订单总额和订单数
INSERT INTO order_stats
SELECT
user_id,
SUM(amount) AS total_amt,
COUNT(*) AS cnt
FROM orders
GROUP BY user_id;
5.4 DataStream 与 Table 互转
两个 API 可以混合使用,发挥各自优势:
// Table API 查询
Table resultTable = tEnv.sqlQuery(
"SELECT user_id, SUM(amount) FROM orders GROUP BY user_id");
// Table 转 DataStream(结果流是 changelog)
DataStream<Row> changelogStream = tEnv
.toChangelogStream(resultTable);
// DataStream 转 Table
tEnv.createTemporaryView("my_stream", dataStream);
六、时间语义与窗口
窗口是把无界流切分成有界片段以便聚合的机制。理解窗口的关键在于先理解时间语义和水位线。
6.1 生成水位线
DataStream<Event> withTimestamps = env
.fromSource(kafkaSource,
WatermarkStrategy
.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner((event, ts) -> event.getTimestamp()),
"kafka-source");
forBoundedOutOfOrderness 表示允许 5 秒的乱序,水位线 = 最大观察时间 - 5 秒。
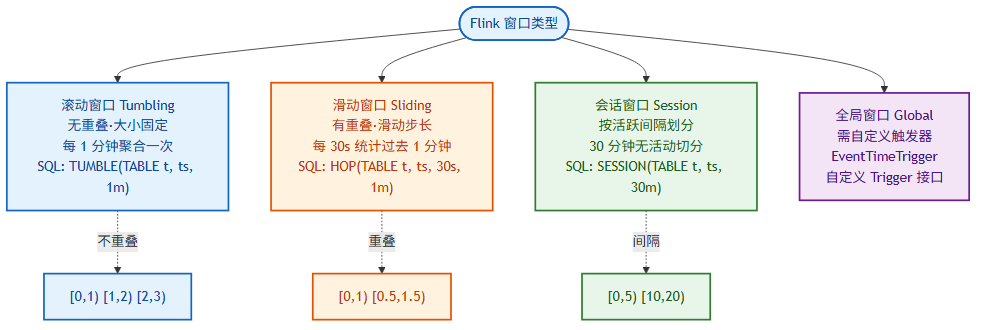
6.2 窗口类型
| 窗口类型 | 特点 | 触发方式 |
|---|---|---|
| 滚动窗口(Tumbling) | 不重叠、不间隔、大小固定 | 按固定时间 |
| 滑动窗口(Sliding) | 可重叠,有滑动步长 | 按步长 |
| 会话窗口(Session) | 按活跃间隔自动划分,大小不固定 | 活动间隙超时 |
| 全局窗口 | 需自定义触发器 | 自定义 Trigger |
6.3 窗口 SQL 示例
-- 滚动窗口:每 1 分钟统计一次订单量
SELECT
window_start,
window_end,
COUNT(*) AS order_cnt,
SUM(amount) AS total
FROM TABLE(
TUMBLE(TABLE orders, DESCRIPTOR(order_time), INTERVAL '1' MINUTE)
)
GROUP BY window_start, window_end;
-- 滑动窗口:每 30 秒统计过去 1 分钟的数据
SELECT
window_start, window_end, user_id, SUM(amount)
FROM TABLE(
HOP(TABLE orders, DESCRIPTOR(order_time),
INTERVAL '30' SECOND, INTERVAL '1' MINUTE)
)
GROUP BY window_start, window_end, user_id;
-- 会话窗口:30 分钟无活动则切分会话
SELECT
window_start, window_end, user_id, COUNT(*)
FROM TABLE(
SESSION(TABLE orders, DESCRIPTOR(order_time), INTERVAL '30' MINUTE)
)
GROUP BY window_start, window_end, user_id;
6.4 迟到数据处理
水位线保证大部分事件被正确归入窗口,但仍可能有迟到事件。Flink 提供两层兜底:
- allowedLateness:允许窗口在关闭后的一段时间内继续接收迟到数据并更新结果。
- side output:把超过允许迟到时间的事件送到侧流,单独处理。
DataStream<...> result = input
.keyBy(e -> e.key)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.allowedLateness(Time.seconds(10)) // 允许 10 秒迟到
.sideOutputLateData(lateTag) // 更迟的送到侧流
.sum("amount");
七、状态管理与容错机制
状态管理是 Flink 区别于普通流处理框架的核心竞争力,也是生产运维中最需要关注的环节。
7.1 状态后端(State Backend)
状态后端决定运行时状态如何存储、如何做快照。Flink 2.x 提供三种:
| 状态后端 | 存储位置 | 适用场景 | 特点 |
|---|---|---|---|
| HashMapStateBackend | JVM 堆内存 | 小状态、高吞吐 | 访问最快,受内存限制,GC 压力大 |
| EmbeddedRocksDBStateBackend | TaskManager 本地磁盘 | 大状态、长窗口 | 状态可扩展到磁盘,支持增量 Checkpoint,读写需序列化 |
| ForStStateBackend | 远程分布式文件系统 + 本地缓存 | 云原生、超大状态、弹性伸缩 | 2.0 引入,存算分离,Checkpoint 轻量快速 |
配置方式(flink-conf.yaml):
# 状态后端类型
state.backend.type: rocksdb
# Checkpoint 存储目录
execution.checkpointing.dir: hdfs://namenode:40010/flink/checkpoints
# 开启增量 Checkpoint(仅 RocksDB/ForSt 支持)
execution.checkpointing.incremental: true
代码级配置:
Configuration config = new Configuration();
config.set(StateBackendOptions.STATE_BACKEND, "rocksdb");
env.configure(config);
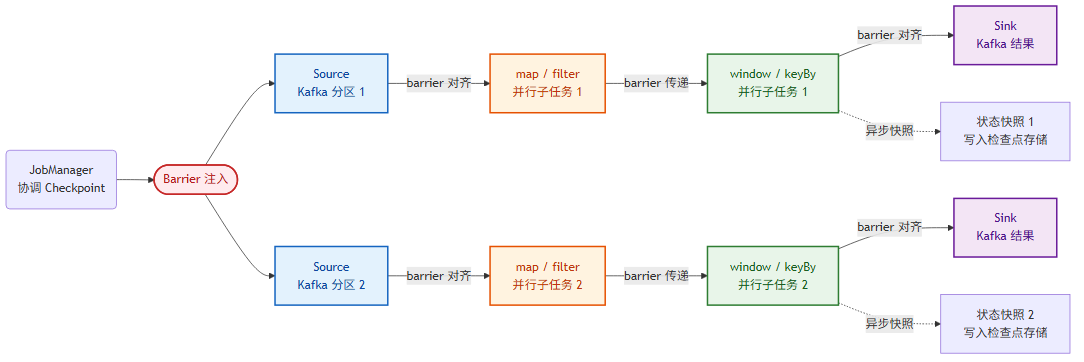
7.2 Checkpoint:故障恢复的基石
Checkpoint 是 Flink 实现容错的核心机制。它基于 Chandy-Lamport 算法,通过向数据流注入屏障(Barrier),让所有算子异步地对自己的状态做快照。
开启 Checkpoint:
env.enableCheckpointing(60_000); // 每 60 秒一次
// 更精细的配置
CheckpointConfig config = env.getCheckpointConfig();
config.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
config.setMinPauseBetweenCheckpoints(30_000); // 两次 checkpoint 间隔
config.setCheckpointTimeout(600_000); // 超时时间
config.setMaxConcurrentCheckpoints(1); // 最大并发数
config.setExternalizedCheckpointCleanup(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
关键调优点:
- 对齐方式:默认 barrier 对齐保证 exactly-once,但反压时会阻塞。可开启 unaligned checkpoint 缓解反压下的 Checkpoint 超时。
- 增量 Checkpoint:大状态作业强烈建议开启,只上传变化部分,显著降低 Checkpoint 耗时。
- buffer debloating:自动调整网络缓冲区大小,减少对齐时间。
# 开启 unaligned checkpoint(反压场景)
execution.checkpointing.unaligned.enabled: true
# 开启 buffer debloating
execution.buffer-debloat.enabled: true
7.3 Savepoint:有状态升级与迁移
Savepoint 是手动触发的、与 Checkpoint 格式兼容的全量快照,主要用于:
- 版本升级与应用变更(改了逻辑后从 savepoint 恢复,保留状态)。
- 作业迁移(A 集群迁到 B 集群)。
- 作业暂停后恢复。
# 触发 savepoint
./bin/flink savepoint <jobId> hdfs:///savepoints/
# 从 savepoint 恢复(取消并重启)
./bin/flink run -s hdfs:///savepoints/savepoint-xxxx -c MyApp job.jar
# 从 savepoint 恢复并允许丢弃状态(有状态算子删除时)
./bin/flink run -s hdfs:///savepoints/savepoint-xxxx --allowNonRestoredState ...
从 Flink 1.13 起统一了 savepoint 的二进制格式,支持跨状态后端恢复(如从 HashMap 切到 RocksDB)。
7.4 ForSt:Flink 2.0 的云原生状态后端
ForSt(“For Streaming”)是 2.0 引入的革命性状态后端,把状态主存储放到分布式文件系统(HDFS、S3),TaskManager 本地磁盘只做缓存,实现存算分离:
- 突破本地盘容量限制:状态规模不再受单机磁盘约束。
- 快速扩缩容:状态在远端,扩缩容时无需搬迁海量本地数据。
- 轻量 Checkpoint:SST 文件已在远端,Checkpoint 只需记录元数据。
配合异步执行模型(table.exec.async-state.enabled),把状态访问与计算解耦,用并行 I/O 掩盖远程访问延迟。在 Nexmark 基准测试中,重 I/O 的状态查询吞吐达到本地存储方案的 75%~120%。
ForSt 目前仍处于演进阶段,使用前需评估其限制(暂不支持 canonical savepoint、full snapshot、changelog 等),并做好灰度与回滚预案。
八、连接器生态
连接器让 Flink 与外部系统集成。常用连接器按数据流向分为 Source(读)和 Sink(写)。
8.1 常用连接器一览
| 连接器 | 类型 | 说明 |
|---|---|---|
| Kafka | Source / Sink | 最主流的消息队列,支持 exactly-once |
| JDBC | Sink | 写入 MySQL、PostgreSQL 等关系库 |
| Paimon | Source / Sink | 流式湖仓存储格式,2.x 深度集成 |
| filesystem | Source / Sink | 读写本地/HDFS 文件,支持分区 |
| Elasticsearch | Sink | 写入 ES 做实时检索 |
| CDC | Source | MySQL/Postgres 变更数据捕获 |
| Doris / StarRocks | Sink | 写入 OLAP 引擎 |
8.2 Kafka Source 与 Sink 完整示例
-- Source:读取 Kafka
CREATE TABLE kafka_source (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '3' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'kafka:9092',
'properties.group.id' = 'behavior-group',
'scan.startup.mode' = 'group-offsets',
'format' = 'json'
);
-- Sink:写入 Kafka
CREATE TABLE kafka_sink (
`window_end` TIMESTAMP(3),
`behavior` STRING,
`cnt` BIGINT
) WITH (
'connector' = 'kafka',
'topic' = 'behavior_stats',
'properties.bootstrap.servers' = 'kafka:9092',
'format' = 'json'
);
-- 管道:实时统计每分钟各行为的次数
INSERT INTO kafka_sink
SELECT
window_end, behavior, COUNT(*) AS cnt
FROM TABLE(
TUMBLE(TABLE kafka_source, DESCRIPTOR(ts), INTERVAL '1' MINUTE)
)
GROUP BY window_end, behavior;
8.3 MySQL CDC 实时同步
CDC(Change Data Capture)把数据库的 binlog 当作流,实现实时数据同步:
CREATE TABLE products (
id INT,
name STRING,
description STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'mysql-host',
'port' = '3306',
'username' = 'flinkuser',
'password' = 'pwd',
'database-name' = 'inventory',
'table-name' = 'products'
);
CDC 表会产生 changelog 流(INSERT/UPDATE/DELETE),可以直接参与 join 和聚合。
8.4 与 Apache Paimon 的湖仓集成
Paimon 是 Flink 2.x 流式湖仓架构的核心伙伴。Flink 既把数据写入 Paimon 表(批或流),又可以把 Paimon 表作为维表做 lookup join:
-- 创建 Paimon 表
CREATE TABLE paimon_orders (
order_id BIGINT,
user_id BIGINT,
amount DECIMAL(10, 2),
dt STRING,
PRIMARY KEY (order_id, dt) NOT ENFORCED
) WITH (
'connector' = 'paimon',
'warehouse' = 's3://my-bucket/warehouse',
'path' = 'orders'
);
-- 实时写入
INSERT INTO paimon_orders
SELECT order_id, user_id, amount, DATE_FORMAT(order_time, 'yyyy-MM-dd')
FROM kafka_source;
九、Flink 2.x 新特性深度解析
这一章聚焦 2.x 系列相对 1.x 的关键变化,理解它们才能用好最新版。
9.1 解耦状态管理(Flink 2.0)
这是 2.0 最重要的架构升级。传统架构下状态绑定在 TaskManager 本地磁盘,带来三个云原生痛点:容器化后本地盘受限、Compaction 导致资源尖峰、大状态扩缩容和恢复慢。
ForSt 把状态主存储搬到分布式文件系统,配合异步执行模型(让状态 I/O 与计算重叠执行),实现存算分离。在 Nexmark 基准测试中,重 I/O 状态查询吞吐达到本地方案的 75%~120%,小状态查询性能差距不超过 10%。
9.2 物化表 Materialized Tables(Flink 2.0)
物化表是 2.0 引入的新表类型,目标是统一流批开发体验。用户只需声明数据新鲜度(FRESHNESS)和查询,引擎自动推导表结构并生成刷新管道:
CREATE MATERIALIZED TABLE daily_sales
PARTITIONED BY (dt)
FRESHNESS = INTERVAL '1' HOUR
AS SELECT
dt,
product_id,
SUM(amount) AS total
FROM orders
GROUP BY dt, product_id;
2.2 进一步优化:FRESHNESS 变为可选(可从上游表推断),支持 DISTRIBUTED BY 分桶,提供 MaterializedTableEnricher 扩展点让厂商实现智能默认逻辑。Paimon 是首个也是唯一支持的 catalog。
9.3 实时 AI:ML_PREDICT 与 VECTOR_SEARCH
这是 Flink 从"数据引擎"迈向"Data + AI 平台"的标志。
ML_PREDICT(2.1 引入,2.2 增强 Table API 支持)在 SQL 中直接调用大模型推理。先用 CREATE MODEL 注册模型,再用 ML_PREDICT 函数调用:
-- 注册 OpenAI 模型
CREATE MODEL `translator`
INPUT (text STRING)
OUTPUT (response STRING)
WITH (
'provider' = 'openai',
'endpoint' = 'https://api.openai.com/v1/chat/completions',
'api-key' = 'sk-xxx',
'model' = 'gpt-4o',
'system-prompt' = 'translate to Chinese'
);
-- 在流式查询中实时调用模型
SELECT * FROM ML_PREDICT(
TABLE input_logs,
MODEL translator,
DESCRIPTOR(text),
MAP['async', 'true', 'timeout', '100s']
);
async 选项启用异步调用,避免模型推理延迟阻塞整个管道。
VECTOR_SEARCH(2.2 引入)支持流式向量相似度检索,构建实时 RAG(检索增强生成)场景:
SELECT * FROM
input_table,
LATERAL VECTOR_SEARCH(
TABLE vector_table,
input_table.query_vector,
DESCRIPTOR(index_column),
10,
MAP['async', 'true', 'timeout', '100s']
);
Table API(Java)也支持模型推理:
// 创建模型
tEnv.createModel("my_model",
ModelDescriptor.forProvider("openai")
.inputSchema(Schema.newBuilder().column("input", DataTypes.STRING()).build())
.outputSchema(Schema.newBuilder().column("output", DataTypes.STRING()).build())
.option("model", "gpt-4.1")
.option("api-key", "sk-xxx")
.build());
// 执行推理(支持异步)
Model model = tEnv.fromModel("my_model");
Table result = model.predict(myTable, ColumnList.of("text"),
Map.of("async", "true"));
9.4 VARIANT 类型与半结构化数据处理(Flink 2.1)
VARIANT 类型用于高效处理 JSON 等半结构化数据,支持存储任意结构并保留字段类型信息,比 ROW 类型更灵活:
CREATE TABLE raw_events (
id INT,
payload VARIANT -- 直接存储动态 JSON
) WITH ('connector' = 'paimon', ...);
-- 用 PARSE_JSON 把字符串转为 VARIANT
INSERT INTO raw_events
SELECT id, PARSE_JSON(json_str) FROM kafka_source;
9.5 Process Table Functions(Flink 2.1)
PTF 让 SQL 也能访问 Flink 的托管状态、事件时间、定时器和表变更日志,把 DataStream API 的能力下放到 SQL 层:
public static class GreetingWithMemory extends ProcessTableFunction<String> {
public static class CountState { public long counter = 0L; }
public void eval(@StateHint CountState state,
@ArgumentHint(SET_SEMANTIC_TABLE) Row input) {
state.counter++;
collect("Hello " + input.getFieldAs("name")
+ ", your " + state.counter + " time?");
}
}
SQL 中调用:
SELECT * FROM GreetingWithMemory(TABLE Names PARTITION BY name)
9.6 Delta Join 与 Multi Join(2.1 引入,2.2 增强)
传统流式 Join 要为每张表维护大状态,是资源消耗和稳定性问题的重灾区。
Delta Join 用双向 lookup 替代状态维护,直接复用源表数据,大幅降低状态规模。2.2 增强了可优化的 SQL 模式:支持消费无 DELETE 操作的 CDC 源、支持投影和过滤、支持缓存以减少外部存储请求。目前配合 Apache Fluss(孵化中)作为源表效果最佳。
Multi Join 把多个级联的 INNER/LEFT Join 合并到单个算子,只存原始输入记录而非中间结果,实现"零中间状态"。开启方式:
SET 'table.optimizer.multi-join.enabled' = 'true';
9.7 运行时与连接器增强(2.2)
- 均衡任务调度:在 TaskManager 间均衡任务负载,减少作业瓶颈。
- SinkUpsertMaterializer V2:重写乱序 changelog 整理算子,解决了旧版本在某些场景下性能指数级退化的问题。
- Scan Source 限流:新增 RateLimiter 接口,避免拉取过快压垮外部系统(如 MySQL CDC)。
- 均衡 Split 分配:SplitEnumerator 获得分片运行时分布信息,可均匀分配,缓解 Kafka 等连接器的数据倾斜。
- Savepoint 连接器(2.1):用 SQL 直接查询 checkpoint/savepoint 中的 keyed state,方便排查和验证状态。
十、部署与运维
10.1 部署模式
Flink 支持多种部署模式,适配不同场景:
| 模式 | 特点 | 适用场景 |
|---|---|---|
| Application 模式 | 每个作业一个集群,main 方法在集群运行 | 生产推荐,隔离性好 |
| Session 模式 | 多个作业共享一个长跑集群 | 开发测试、短作业 |
| Per-Job 模式 | 每个作业独立集群(已在 2.x 弃用) | 已不推荐 |
底层资源管理器支持 Standalone、YARN、Kubernetes。云原生场景下 Kubernetes + Flink Kubernetes Operator 是主流方案。
10.2 Kubernetes Operator 部署
Flink Kubernetes Operator 以声明式方式管理 Flink 作业的生命周期,支持自动保存点、故障恢复、版本升级。安装(以 1.14.0 为例):
helm repo add flink-operator \
https://downloads.apache.org/flink/flink-kubernetes-operator-1.14.0/
helm install flink-operator flink-operator/flink-kubernetes-operator
声明式定义作业(FlinkDeployment CRD):
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: my-flink-job
spec:
image: flink:2.2.0
flinkVersion: v2_2
flinkConfiguration:
state.backend.type: rocksdb
execution.checkpointing.interval: 60s
execution.checkpointing.dir: s3://my-bucket/checkpoints
serviceAccount: flink
jobManager:
resource:
memory: "2048m"
cpu: 1
taskManager:
resource:
memory: "4096m"
cpu: 2
job:
jarURI: local:///opt/flink/usrlib/my-job.jar
parallelism: 4
entryClass: com.example.MyFlinkJob
state: running
Operator 2.2 兼容版本还引入了 Kubernetes 原生 Conditions、Logback 日志支持、内置 metric reporter 等增强。
10.3 高可用配置
生产环境必须配置高可用(HA),防止 JobManager 单点故障。基于 ZooKeeper 的 HA 配置:
high-availability.type: zookeeper
high-availability.zookeeper.quorum: zk1:2181,zk2:2181,zk3:2181
high-availability.zookeeper.path.root: /flink
high-availability.storageDir: hdfs:///flink/ha/
10.4 监控与指标
Flink 内置丰富的指标体系,可通过 Prometheus + Grafana 可视化。关键监控项:
- Checkpoint:完成率、耗时、对齐时间、checkpointed data size(注意增量模式下显示的是 delta)。
- 反压:各算子的 backPressure 状态。
- 水位线:2.1 新增 split 级水位线指标(currentWatermark、activeTimeMsPerSecond 等)。
- 状态:状态大小、RocksDB 内存使用。
开启 Prometheus reporter:
metrics.reporter.prom.class: org.apache.flink.metrics.prometheus.PrometheusReporter
metrics.reporter.prom.port: 9999
十一、性能调优实战
11.1 资源配置
合理分配 TaskManager 内存是性能基础。Flink 把 TaskManager 总内存(taskmanager.memory.process.size)划分为几块:
- Framework / Task Heap:JVM 堆,框架与用户代码。
- Managed Memory:托管内存,给 RocksDB、排序、缓存用。
- Network:网络缓冲区,用于 shuffle。
- Off-heap / Metaspace:JVM 元空间与堆外。
使用 RocksDB 时,Managed Memory 至少留 1GB,并开启托管模式让 Flink 统一管控 RocksDB 内存:
state.backend.rocksdb.memory.managed: true
state.backend.rocksdb.memory.write-buffer-ratio: 0.5
state.backend.rocksdb.memory.high-prio-pool-ratio: 0.1
不要把 high-prio-pool-ratio 设为 0,否则 index/filters 会与 data blocks 争抢 cache,性能急剧下降。
11.2 反压治理
反压表现为下游处理不过来导致上游阻塞。排查步骤:
- Web UI 查看各算子的 BackPressure 状态(High/Medium/Low)。
- 定位到最末端处于 High 的算子,它是瓶颈源。
- 常见原因:外部 I/O 慢(数据库、Kafka)、状态过大导致 Checkpoint 卡顿、数据倾斜。
缓解手段:
- 提高瓶颈算子并行度。
- 异步 I/O(
AsyncFunction)避免阻塞主线程。 - 开启 unaligned checkpoint 与 buffer debloating 减少 Checkpoint 对反压的放大。
11.3 数据倾斜
数据倾斜是流处理最常见的性能杀手。识别:Web UI 中某些 subtask 处理量远高于其他。应对策略:
- 打散 key:先给 key 加随机后缀分散,聚合后再二次聚合。
- LocalGlobal 优化:SQL 中开启两阶段聚合,先本地预聚合再全局聚合。
-- 自动开启 local-global 两阶段聚合
SET 'table.optimizer.agg-phase-strategy' = 'AUTO';
- MiniBatch 聚合:开启微批聚合,减少状态访问次数。
SET 'table.exec.mini-batch.enabled' = 'true';
SET 'table.exec.mini-batch.allow-latency' = '5s';
SET 'table.exec.mini-batch.size' = '5000';
11.4 SQL 优化项汇总
| 配置项 | 作用 |
|---|---|
table.exec.async-lookup.output-mode = ALLOW_UNORDERED |
异步 lookup join 允许乱序输出,提升吞吐(2.1 起对更新流也生效) |
table.optimizer.multi-join.enabled = true |
合并多个级联 join,降低状态 |
table.exec.async-state.enabled = true |
开启异步状态访问(配合 ForSt) |
table.exec.mini-batch.* |
微批聚合,减少状态读写 |
table.optimizer.agg-phase-strategy = AUTO |
两阶段聚合应对倾斜 |
十二、实战案例:实时数仓与实时风控
把前面学的知识串起来,看两个典型场景。
12.1 实时数仓(Lambda/Kappa 架构)
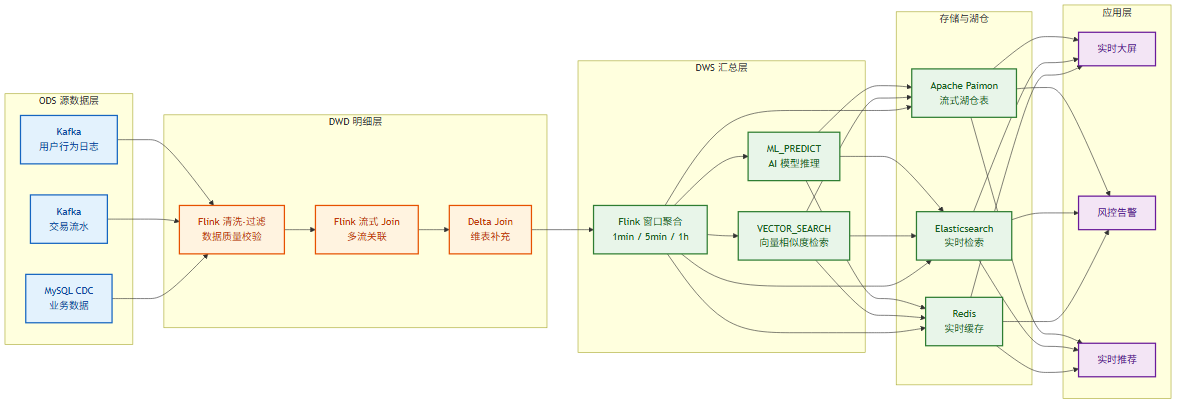
经典实时数仓链路:Kafka(ODS)→ Flink 清洗聚合(DWD/DWS)→ Paimon(湖仓)→ 下游 OLAP/查询。
-- ODS:原始日志从 Kafka 读入
CREATE TABLE ods_logs (
log_id STRING,
user_id BIGINT,
event STRING,
properties STRING,
ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH ('connector' = 'kafka', ...);
-- DWS:每分钟按事件类型聚合
CREATE TABLE dws_event_min (
window_end TIMESTAMP(3),
event STRING,
user_cnt BIGINT,
event_cnt BIGINT
) WITH ('connector' = 'paimon', 'warehouse' = 's3://wh/dws', ...);
INSERT INTO dws_event_min
SELECT
window_end,
event,
COUNT(DISTINCT user_id) AS user_cnt,
COUNT(*) AS event_cnt
FROM TABLE(
TUMBLE(TABLE ods_logs, DESCRIPTOR(ts), INTERVAL '1' MINUTE)
)
GROUP BY window_end, event;
配合 2.x 的 Delta Join,维表关联可以直接复用 Paimon 表数据而无需维护大状态,显著降低资源消耗。
12.2 实时风控:异常检测 + AI 判定
结合 2.x 的 AI 能力,构建"实时特征 + 模型判定"风控:
-- 1. 实时计算用户近 5 分钟交易频率
CREATE TABLE user_txn_freq (
user_id BIGINT,
window_end TIMESTAMP(3),
txn_cnt BIGINT,
total_amount DECIMAL(10,2)
) WITH ('connector' = 'kafka', ...);
INSERT INTO user_txn_freq
SELECT user_id, window_end, COUNT(*), SUM(amount)
FROM TABLE(
TUMBLE(TABLE transactions, DESCRIPTOR(txn_time), INTERVAL '5' MINUTE)
)
GROUP BY user_id, window_end;
-- 2. 用大模型对高频交易做风险研判
CREATE MODEL risk_model
INPUT (desc STRING)
OUTPUT (risk_level STRING)
WITH (
'provider' = 'openai',
'model' = 'gpt-4o',
'system-prompt' = '判断该交易行为的风险等级:低/中/高',
'api-key' = 'sk-xxx'
);
-- 3. 把可疑交易描述喂给模型,实时输出风险等级
SELECT * FROM ML_PREDICT(
TABLE (
SELECT CONCAT('用户', CAST(user_id AS STRING),
'5分钟内交易', CAST(txn_cnt AS STRING),
'笔,金额', CAST(total_amount AS STRING)) AS desc
FROM user_txn_freq WHERE txn_cnt > 10
),
MODEL risk_model,
DESCRIPTOR(desc),
MAP['async', 'true', 'timeout', '30s']
);
异步推理保证模型延迟不会拖垮整个实时管道。
十三、学习路径与进阶建议
13.1 分阶段学习路径

入门阶段(1-2 周)
- 跑通本地集群与 WordCount 作业,理解 Source/Transform/Sink 结构。
- 用 SQL Connector 连接 Kafka,写出第一个连续查询。
- 理解时间语义与水位线,区分事件时间与处理时间。
进阶阶段(2-4 周)
- 掌握 Keyed State 的几种原语,写一个有状态 ProcessFunction。
- 理解 Checkpoint 原理,会配置状态后端与增量 Checkpoint。
- 学习窗口的三种类型,处理迟到数据与侧流输出。
精通阶段(持续)
- 深入研究 2.x 的解耦状态架构,在云原生环境实践 ForSt。
- 把 AI 能力(ML_PREDICT、VECTOR_SEARCH)融入业务管道。
- 掌握反压、倾斜、Checkpoint 长尾等生产问题的诊断与调优。
- 熟悉 Kubernetes Operator 部署与高可用运维。
13.2 关键能力自检
到精通阶段,你应该能独立完成:
- 根据状态规模和延迟要求选型状态后端(HashMap / RocksDB / ForSt)。
- 设计满足 exactly-once 的端到端管道(Source + Checkpoint + Sink)。
- 用 Delta Join / Multi Join 优化大状态 Join 作业。
- 用物化表统一流批数据管道,降低开发与运维成本。
- 在 SQL 中嵌入大模型推理,构建实时智能应用。
13.3 持续跟进
Flink 2.x 仍处于快速演进期,AI 能力和解耦架构都在持续增强。建议关注:
- 官方博客与发布说明(每个版本的 FLIP 列表是了解设计动机的最佳入口)。
- Apache Fluss 项目(孵化中),它是 Delta Join 的配套流式存储。
- Paimon 社区,流式湖仓格式的演进与 Flink 深度协同。
Flink 2.x 把流处理的门槛进一步降低:物化表让你不必深究流批差异,解耦状态让大状态作业在云上跑得更稳,ML_PREDICT 和 VECTOR_SEARCH 让实时数据直接驱动智能决策。掌握这套技术栈,意味着你具备了构建下一代实时数据与 AI 基础设施的能力。
评论区