



从核心组件到生产部署,全面解析智能体系统架构设计
涵盖单Agent架构、多Agent协作、记忆系统、工具调用、主流框架对比

01 Agent 概述与定义
AI Agent(智能体)是一种能够自主感知环境、进行推理决策、调用工具并执行行动以完成特定目标的人工智能系统。与传统的大语言模型不同,Agent具备持续运行、自主规划、工具使用和从经验中学习的能力。
四大核心能力
| 能力 | 说明 |
|---|---|
| 自主推理 | 能够分解复杂任务,制定执行计划,并在执行过程中动态调整策略 |
| 工具使用 | 通过 Function Calling 机制调用外部 API、数据库、搜索引擎等扩展能力 |
| 记忆系统 | 拥有短期工作记忆和长期记忆,能够记住过往交互和学习到的知识 |
| 循环执行 | 采用"思考-行动-观察"的迭代循环,直至任务完成或达到终止条件 |
一个完整的 Agent 系统不仅仅是一个 LLM 包装器,而是由多个协同工作的模块组成的复杂系统。现代 Agent 架构已经从简单的 ReAct 循环演进到支持图状态编排、多 Agent 协作、持久化记忆的企业级系统。[1]
02 六层系统架构全景
现代生产级 AI Agent 系统普遍采用分层架构设计,每一层都有明确的职责边界。根据业界实践和 AWS 等云厂商的技术栈地图,完整的 Agent 系统可划分为六个核心层次。[2][3]
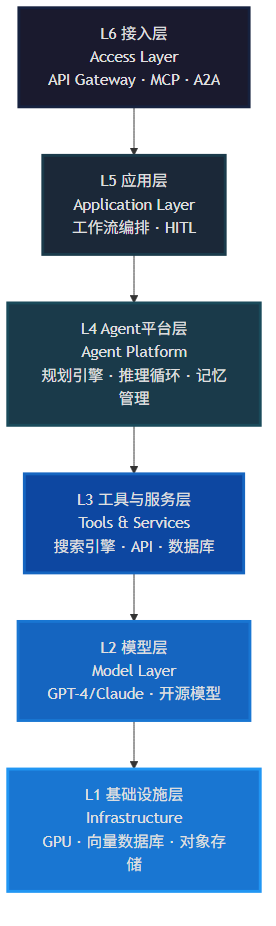
各层职责说明
| 层级 | 名称 | 核心职责 | 关键技术 |
|---|---|---|---|
| L6 | 接入层 | 系统入口,请求路由、认证鉴权与协议适配 | API Gateway, 负载均衡, MCP/A2A适配器, 限流熔断 |
| L5 | 应用层 | 面向用户的交互界面与业务逻辑编排 | 对话界面, 工作流编排, 多Agent协调, HITL |
| L4 | Agent平台层 | Agent的核心运行时与认知引擎 | 规划引擎, 推理循环, 状态管理, 记忆管理, 工具路由 |
| L3 | 工具与服务层 | Agent可调用的外部能力集合 | 搜索引擎, 代码执行, 数据库, 第三方API, 文件系统 |
| L2 | 模型层 | 提供推理能力的基础大语言模型 | GPT-4/Claude, 开源模型, Embedding, 多模态 |
| L1 | 基础设施层 | 底层计算、存储与网络资源 | GPU/CPU集群, 向量数据库, 对象存储, 消息队列 |
架构设计要点:分层架构的核心价值在于关注点分离——每一层只依赖其下方的层,通过清晰的接口进行通信。这种设计使得各层可以独立演进、替换和扩展。例如,可以在不改变 Agent 逻辑的情况下替换底层模型,或者在不影响接入层的情况下增加新的工具。
03 核心组件详解
无论采用哪种具体架构模式,一个功能完整的 Agent 都包含以下核心组件。这些组件协同工作,构成了 Agent 的认知-行动闭环。
Agent 核心组件架构图
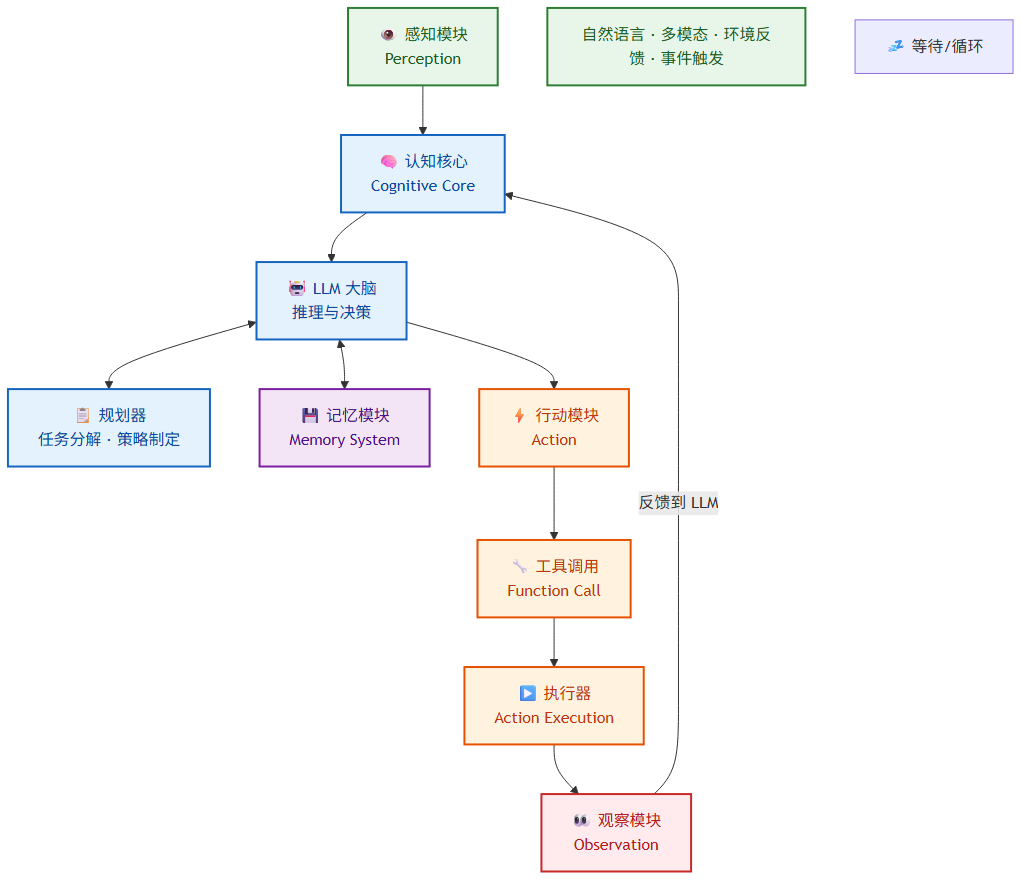
3.1 感知模块 (Perception)
感知模块是 Agent 与外部世界交互的输入接口。它负责接收和预处理来自多种渠道的信息:
- 自然语言输入:用户的文本指令、问题或对话内容
- 多模态输入:图像、音频、视频等非文本信息
- 环境反馈:工具执行结果、API响应、系统状态
- 事件触发:定时任务、Webhook回调、消息队列事件
3.2 大语言模型 (LLM) — 大脑
LLM 是 Agent 的核心决策引擎,承担以下关键职责:
- 理解意图:解析用户输入的真实需求和目标
- 推理思考:分析当前状态,思考下一步应该做什么
- 生成决策:输出结构化的行动指令或自然语言响应
- 反思评估:评估行动结果,判断是否需要调整策略
⚠️ 模型选择考量:并非所有任务都需要最强大的模型。生产系统中常采用模型路由策略:简单的意图分类使用小模型(NLU/SLM),复杂推理使用大模型,工具参数填充使用中等模型。这种分层策略可以显著降低成本同时保持性能。[4]
3.3 规划器 (Planner)
规划器负责将复杂的用户目标分解为可执行的子任务序列。主要的规划策略包括:
| 策略 | 说明 | 特点 |
|---|---|---|
| 单步规划 | ReAct 模式下每一步都重新评估,根据当前观察决定下一步行动 | 灵活但可能缺乏全局视野 |
| 预先规划 | Plan-and-Execute 模式:先制定完整计划,再逐步执行 | 适合目标明确的复杂任务 |
| 动态重规划 | 执行过程中根据反馈不断调整计划 | 结合前两种方式的优点,主流方案 |
3.4 记忆模块 (Memory)
记忆系统赋予 Agent 持续学习和个性化交互的能力,是 Agent 区别于无状态 LLM 调用的关键特征。详细架构见第06章。
3.5 工具调用模块 (Tool Use)
工具是 Agent 超越 LLM 固有能力边界的手段。通过标准化的 Function Calling 接口,Agent 可以与外部世界交互。详细架构见第07章。
3.6 执行器与观察 (Actuator & Observation)
执行器负责实际执行工具调用并将结果返回给 LLM。观察模块则负责格式化工具输出,确保 LLM 能够理解执行结果并据此进行下一步推理。这一"行动-观察"闭环是 Agent 自主性的基础。
04 单Agent架构模式
单个 Agent 的架构设计经历了从简单到复杂的演进过程。不同的架构模式适用于不同复杂度的任务场景。
4.1 ReAct 模式 — 推理与行动交织
ReAct(Reasoning + Acting)是最经典也是最广泛使用的 Agent 架构模式。它的核心思想是让 LLM 交替生成推理轨迹和行动指令,形成"思考→行动→观察"的循环。[5][6]
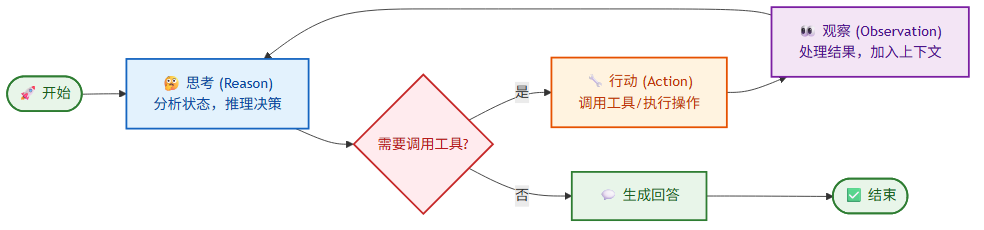
ReAct 循环三步骤:
- 思考 (Reason):LLM 分析当前状态,推理下一步应该做什么
- 行动 (Act):调用工具获取信息或执行操作
- 观察 (Observe):处理工具返回结果,将其加入上下文
| 优势 | 局限 |
|---|---|
| 实现简单,与 LLM 的指令遵循能力高度契合 | 缺乏全局规划,容易陷入"试错循环" |
| 动态适应环境变化,每步可调整策略 | 上下文窗口消耗快,长任务成本高 |
| 推理过程可解释,便于调试 | 复杂任务可能出现"迷失"现象 |
| 无需大量训练数据,基于提示工程即可实现 | 没有内置的错误恢复机制 |
4.2 Reflexion 模式 — 自我反思
Reflexion 在 ReAct 基础上增加了自我反思机制。Agent 在完成一轮行动后,会显式地评估自己的表现,生成语言化的反思反馈,并将其加入后续决策的上下文中。[7]
任务 → 执行轨迹(ReAct循环) → 执行结果 → 反思评估
├─ 失败/可改进 → 生成反思(记录经验教训) → 存入反思记忆 → 重新执行
└─ 成功 → 完成
4.3 Plan-and-Execute 模式 — 先规划后执行
Plan-and-Execute 模式将任务分为两个明确阶段:规划阶段制定完整的步骤计划,执行阶段逐步实施。执行过程中可以触发重规划。[7]
用户目标 → 规划器(生成步骤计划) → 执行器(逐步执行)
├─ 计划需要调整 → 重规划(更新计划) → 回到执行
└─ 所有步骤完成 → 任务完成
4.4 图状态编排 — LangGraph 模式
LangGraph 代表了 Agent 架构的最新演进方向。它将 Agent 的执行流程建模为有向图,节点代表计算步骤(如调用 LLM、执行工具),边代表状态转移条件。[8][9]
┌─────────────────┐
│ Agent 节点 │
Start ──────────→ │ (LLM 推理) │
└────────┬────────┘
│
工具调用?
┌────────┴────────┐
│ 是 │ 否
▼ ▼
┌─────────────┐ End (结束)
│ Tools 节点 │
│ (执行工具) │
└──────┬──────┘
│
└──── 回到 Agent 节点
┌───────────────────────────────────┐
│ 全局共享状态 (State) │
│ · 消息历史 · 记忆数据 │
│ · 执行上下文 │
└───────────────────────────────────┘
✅ LangGraph 核心优势:图状态编排的关键创新在于显式状态管理——所有节点共享一个持久化的状态对象,支持检查点(checkpoint)、恢复执行、时间旅行调试和人工介入。这使得 Agent 从无状态的对话循环进化为有状态的持久化工作流。[10]
4.5 架构模式对比
| 架构模式 | 核心思想 | 适用场景 | 复杂度 | 代表框架 |
|---|---|---|---|---|
| ReAct | 每步推理后立即行动 | 简单问答、工具使用、快速原型 | 低 | LangChain Agents |
| Reflexion | 行动后自我反思改进 | 代码生成、复杂推理、需要迭代优化的任务 | 中 | Reflexion, Shoggoth |
| Plan-and-Execute | 先规划再执行,支持重规划 | 目标明确的多步骤复杂任务 | 中 | BabyAGI, PlanEx |
| 图状态编排 | 有向图 + 持久化状态 | 企业级应用、需要HITL、生产部署 | 高 | LangGraph, LlamaIndex Workflows |
05 多Agent系统架构
当任务复杂度超过单个 Agent 的能力边界时,就需要多个 Agent 协同工作。多 Agent 系统通过能力互补、并行处理、故障隔离来解决单 Agent 无法应对的复杂问题。[7][11]
5.1 核心优势
| 优势 | 说明 |
|---|---|
| 能力互补 | 不同 Agent 专注不同领域(如研究员、程序员、测试员),突破单一模型的能力边界 |
| 效率提升 | 并行处理与任务分解,将复杂任务处理时间从小时级压缩至分钟级 |
| 系统鲁棒性 | Agent 间故障隔离,避免单点故障导致整个系统崩溃 |
5.2 经典协作模式
模式1:Orchestrator-Worker(编排者-工作者)
一个中央编排 Agent 负责任务分解、分配给工作者 Agent、并监督执行。工作者 Agent 之间不直接通信,所有结果汇总到编排者。[11][12]
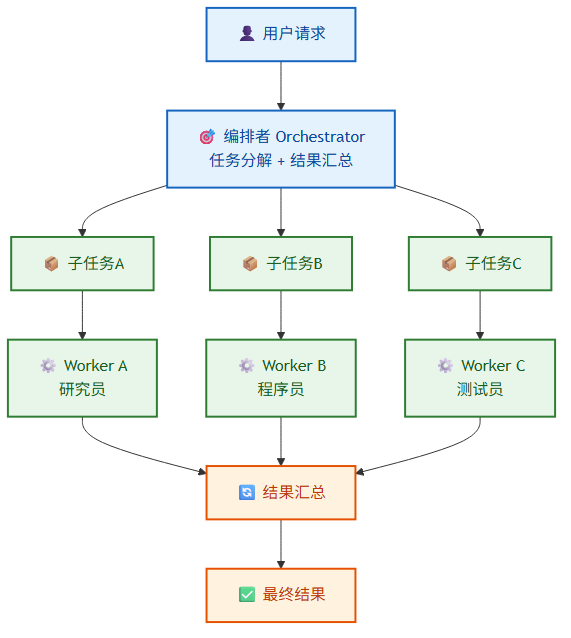
适用场景:任务可并行分解、需要一致性控制、便于调试的场景。这是最常用的多 Agent 模式。
模式2:Hierarchical(层级模式)
Agent 按层级组织,高层 Agent 监督低层 Agent,形成树状指挥结构。每个上级 Agent 管理多个下级 Agent,可以递归分解任务。[11]
┌──────────────────┐
│ 顶层 Agent │
│ (项目经理) │
└────┬────┬────┬───┘
│ │ │
┌──────┘ │ └──────┐
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ 中层Agent │ │ 中层Agent │ │ 中层Agent │
│ (前端组长)│ │ (后端组长)│ │ (测试组长)│
└────┬─────┘ └────┬─────┘ └────┬─────┘
│ │ │
▼ ▼ ▼
开发者Agent 开发者Agent 测试Agent
适用场景:大规模复杂项目,如软件开发团队模拟、企业级业务流程自动化。
模式3:Peer-to-Peer / Debate(对等/辩论模式)
所有 Agent 地位平等,通过消息总线直接通信。典型形式包括多 Agent 辩论、协作写作、群体决策等。[7]
┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
│ Agent 1 │ │ Agent 2 │ │ Agent 3 │ │ Agent 4 │
│ 研究员 │ │ 批评者 │ │ 撰写者 │ │ 审核者 │
└────┬─────┘ └────┬─────┘ └────┬─────┘ └────┬─────┘
│ │ │ │
└────────────────┼────────────────┼────────────────┘
│ │
┌──────┴────────────────┴──────┐
│ 消息总线 (Message Bus) │
│ 共享话题 / 队列 │
└───────────────────────────────┘
适用场景:需要多角度论证的决策场景、创意内容生成、研究报告撰写、代码审查。
模式4:Pipeline(流水线模式)
Agent 按固定顺序排列,每个 Agent 的输出作为下一个 Agent 的输入,形成处理流水线。类似工厂装配线。
需求分析 → 架构设计 → 代码生成 → 测试验证 → 部署发布
Agent Agent Agent Agent Agent
适用场景:内容创作流水线、软件开发流程、数据处理ETL、具有明确阶段划分的重复性任务。
模式5:Router(路由器模式)
使用一个轻量级分类器(NLU或小模型)将用户请求路由到最合适的专门 Agent。当分类置信度低时,升级到更强大的 LLM 处理。[4]
┌──────────────────┐
用户请求 → │ 路由器 (NLU分类) │
└────┬───┬───┬─────┘
│ │ │
┌──────────┘ │ └──────────┐
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│代码Agent │ │搜索Agent │ │写作Agent │
└────┬─────┘ └────┬─────┘ └────┬─────┘
│ │ │
└─────────────┼─────────────┘
▼
低置信度 → 通用LLM兜底处理
│
▼
响应
适用场景:客服系统、多功能助手、成本优化场景(小模型路由 + 大模型兜底)。
5.3 Agent 间通信方式
| 通信方式 | 特点 | 适用模式 |
|---|---|---|
| 直接调用 | 编排者直接调用工作者,同步等待结果 | Orchestrator-Worker |
| 消息总线 | 通过共享队列发布/订阅消息,异步解耦 | Peer-to-Peer, 事件驱动 |
| 共享状态 | 多个 Agent 读写共享内存/黑板 | 协作解决、黑板模式 |
| A2A协议 | Agent-to-Agent 标准化通信协议 | 跨平台 Agent 互操作 |
06 记忆系统架构
记忆系统是 Agent 实现个性化、持续学习和长上下文处理的关键组件。一个设计良好的记忆架构能够让 Agent 从"无状态的对话机器人"进化为"有记忆的智能助手"。[13][14]
6.1 记忆的三层分类
┌─────────────────┐
│ 工作记忆 │ ← 秒~分钟级
│ 当前对话窗口 │
└─────────────────┘
┌───────────────────────┐
│ 短期记忆 │ ← 小时~天级
│ 会话内上下文 │
└───────────────────────┘
┌───────────────────────────────┐
│ 长期记忆 │ ← 天~年级
│ 跨会话知识库 │
└───────────────────────────────┘
6.2 各层记忆详解
工作记忆 (Working Memory)
工作记忆即 LLM 的上下文窗口,存储当前推理过程中需要的所有信息:当前对话消息、思考过程、最近的工具调用结果。这是最快但最有限的记忆形式,受模型最大 token 数限制。[15]
💡 优化策略:工作记忆的管理是 Agent 性能的关键。常用技术包括:消息裁剪(保留最近 N 轮)、摘要压缩(将历史对话压缩为摘要)、相关性过滤(只保留与当前任务相关的信息)。
短期记忆 (Short-term Memory)
短期记忆在单个会话内维护,超出上下文窗口的信息可以通过短期记忆持久化。LangGraph 将其定义为会话范围内的状态,通过 Checkpointer 机制实现会话暂停和恢复。[10][16]
长期记忆 (Long-term Memory)
长期记忆跨会话持久化,存储用户偏好、历史交互、学习到的知识和程序。长期记忆又可细分为:[17]
| 类型 | 说明 | 示例 |
|---|---|---|
| 情景记忆 (Episodic) | 记住过去的具体交互经历 | “用户上次提到他喜欢简洁的回答” |
| 语义记忆 (Semantic) | 存储事实性知识和概念,通过向量检索获取 | 知识库文档、产品信息 |
| 程序记忆 (Procedural) | 记住完成任务的流程和方法 | “如何部署一个Web应用” |
6.3 记忆存储架构
生产级记忆系统采用多存储协作的架构:[13][18]
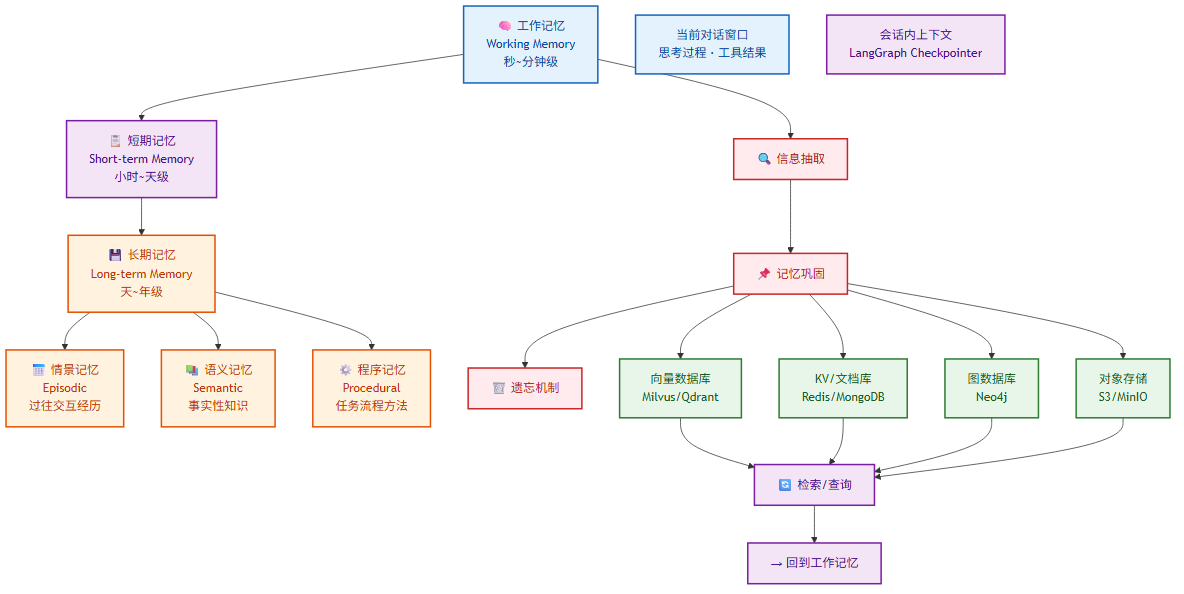
6.4 存储技术选型
| 存储类型 | 数据模型 | 查询方式 | 典型产品 | 存储内容 |
|---|---|---|---|---|
| 向量数据库 | 高维向量 | 语义相似度搜索 | Milvus, Qdrant, Pinecone, Weaviate, pgvector | 非结构化文本、对话历史、知识库文档 |
| KV/文档数据库 | Key-Value / JSON | Key查询 / 条件过滤 | Redis, MongoDB, DynamoDB | 用户配置、会话状态、结构化偏好 |
| 关系数据库 | 表/行 | SQL查询 | PostgreSQL, MySQL | 用户信息、任务记录、操作日志 |
| 图数据库 | 节点+边 | 图遍历/路径查询 | Neo4j, NebulaGraph | 实体关系、知识图谱、社交网络 |
| 对象存储 | 文件/Blob | 路径访问 | S3, MinIO, OSS | 上传文件、生成的文档、媒体资源 |
⚠️ 多Agent系统的记忆共享:在多 Agent 系统中,记忆分为个体记忆和共享记忆两种。个体记忆是每个 Agent 私有的,共享记忆(如团队任务进度、共同发现的事实、协调协议)则允许多个 Agent 读写,是实现协作的关键基础设施。[17]
07 工具调用架构
工具调用(Tool Calling / Function Calling)是 Agent 从"聊天机器人"进化为"行动者"的关键能力。通过工具,Agent 可以获取实时信息、执行计算、操作外部系统。[19][20]
7.1 工具调用基础流程
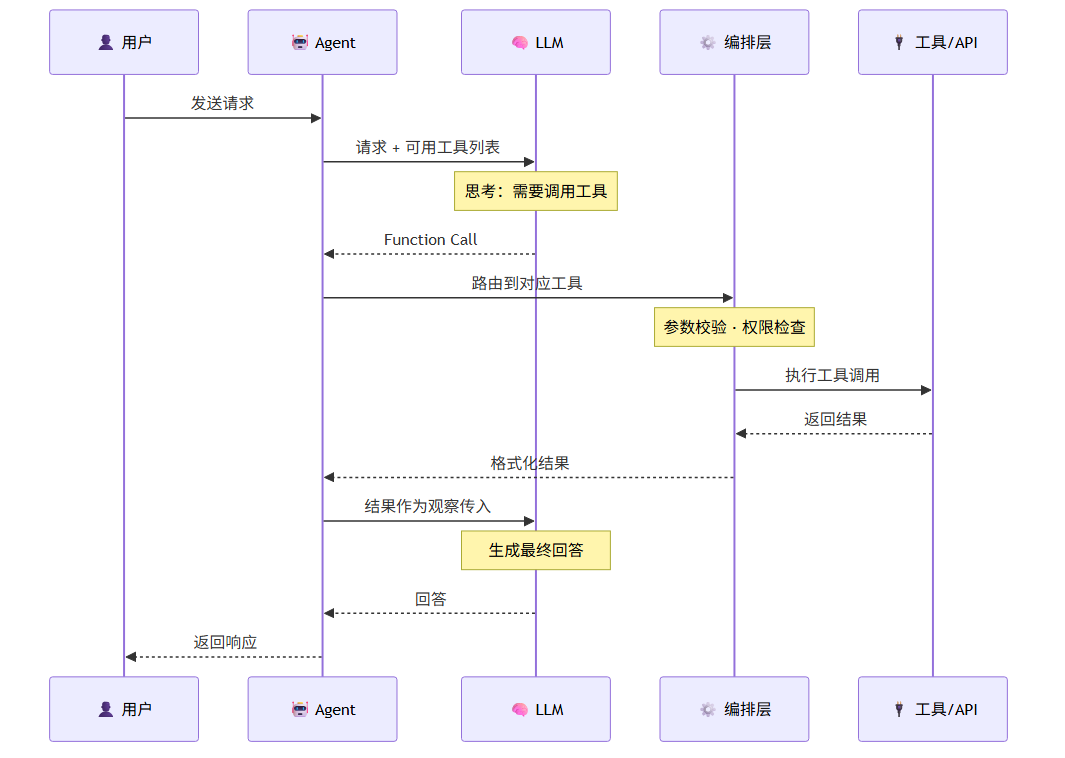
编排层关键职责:参数校验 · 权限检查 · 错误处理 · 超时控制 · 结果格式化 · 日志记录
7.2 Tool Schema 六层设计模型
生产级的工具定义需要完善的 Schema 描述。一个高质量的 Tool Schema 包含六个层次:[19]
| 层级 | 名称 | 说明 | 关键字段 |
|---|---|---|---|
| 1 | 身份标识 | 工具的唯一名称和版本号,用于精确路由 | name, version |
| 2 | 能力描述 | 清晰描述工具的功能、适用场景和边界 | description |
| 3 | 使用说明 | 何时使用该工具、何时不使用、与其他工具的关系 | when_to_use, when_not_to_use |
| 4 | 参数定义 | JSON Schema 定义输入参数的类型、是否必填、枚举值 | parameters (JSON Schema) |
| 5 | 约束规则 | 参数的取值范围、格式要求、依赖关系、权限要求 | constraints, permissions |
| 6 | 示例指引 | 提供 Few-shot 示例,展示正确的调用方式和返回格式 | examples |
Tool Schema 示例:
{
"name": "search_web",
"version": "1.0.0",
"description": "搜索互联网获取实时信息。适用于需要最新数据、新闻、事实查询的场景。",
"when_to_use": "用户询问时事、需要实时数据、查询最新信息时",
"when_not_to_use": "查询历史事件、概念解释、已有知识库能回答的问题",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索关键词",
"minLength": 1,
"maxLength": 200
},
"max_results": {
"type": "integer",
"description": "最大返回结果数",
"default": 5,
"minimum": 1,
"maximum": 20
}
},
"required": ["query"]
},
"constraints": {
"rate_limit": "10 calls/minute",
"timeout": "30s",
"required_permission": "web_search"
},
"examples": [
{
"input": {"query": "2026年AI Agent最新进展", "max_results": 5},
"output": {"results": [{"title": "...", "url": "...", "snippet": "..."}]}
}
]
}
7.3 三种工具调用架构模式
模式A:单轮调用 (Single-turn)
LLM 做一次决策:选择工具并填充参数。应用执行工具,结果返回 LLM 生成最终回答。一次调用,一次结果,一次回答。[21]
用户 → LLM(选择工具+参数) → 执行工具 → LLM(生成回答) → 用户
特点:简洁高效,确定性强,适合单步工具使用场景(如查天气、简单搜索)。OpenAI Function Calling 的原生模式。
模式B:ReAct循环 (Multi-step ReAct)
LLM 可以在一个任务中多次调用工具,每步根据观察结果决定下一步行动。这是目前 Agent 的主流模式。[7]
用户 → LLM → 工具1 → 观察 → LLM → 工具2 → 观察 → ... → LLM(回答) → 用户
特点:灵活强大,支持多步推理和复杂任务,但 token 消耗大,可能陷入循环。
模式C:并行调用 (Parallel Calling)
LLM 一次输出多个独立的工具调用,可以并行执行,显著提升效率。[7]
用户 → LLM → [工具A, 工具B, 工具C] → 并行执行 → 合并结果 → LLM(回答) → 用户
特点:适用于多个独立子任务可同时获取信息的场景(如同时搜索多个关键词、查询多个数据源)。
7.4 MCP:工具协议标准化
Model Context Protocol (MCP) 是正在兴起的工具调用标准化协议,旨在解决工具集成的碎片化问题。MCP 提供统一的工具发现、调用和响应格式,使得工具可以在不同 Agent 框架间复用。
✅ 编排层关键职责:在 LLM 和工具之间,编排层承担着重要的"安全网关"角色:参数校验(防止注入攻击)、权限控制(Agent 只能调用被授权的工具)、超时控制(防止工具挂起)、错误处理(优雅降级而非崩溃)、日志审计(追踪所有工具调用)。这些是生产系统不可或缺的。
08 主流框架对比
2025-2026年,Agent 开发框架生态已经相对成熟。不同框架在设计理念、抽象层次和适用场景上各有侧重。[8]
| 框架 | 核心抽象 | 架构特点 | 记忆支持 | 多Agent | 适用场景 |
|---|---|---|---|---|---|
| LangChain Agents | Chain + Agent | ReAct循环,链式调用,生态丰富 | 基础支持 | 有限支持 | 快速原型、简单应用、工具集成 |
| LangGraph | StateGraph | 图状态编排,持久化检查点,HITL | 短期+长期 | 原生支持 | 企业级生产应用、复杂工作流 |
| LlamaIndex Workflows | Workflow + Event | 事件驱动,基于图,RAG优先 | 强RAG集成 | 支持 | RAG密集型应用、文档处理 |
| AutoGPT | 自主Agent | 完全自主,目标驱动,文件系统访问 | 内置 | 有限 | 开放式任务、实验性探索 |
| CrewAI | Crew + Agent | 角色化多Agent协作,流程编排 | 支持 | 核心特性 | 团队模拟、多角色协作任务 |
| AutoGen | ConversableAgent | 对话驱动的多Agent,人机协作 | 支持 | 核心特性 | 研究、多Agent对话、代码生成 |
| Semantic Kernel | Plugin + Planner | 微软生态,企业级,多语言支持 | 支持 | 支持 | .NET/Java企业应用、微软生态集成 |
框架演进趋势
第一代 (2023) 第二代 (2024) 第三代 (2025-2026)
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐
│ LangChain Agents │ │ AutoGPT/CrewAI │ │ LangGraph/Workflows│
│ · 简单ReAct循环 │ ────→ │ · 多Agent协作 │ ────→ │ · 图状态编排 │
│ · 无状态 │ │ · 自主规划 │ │ · 持久化运行时 │
│ │ │ │ │ · 生产级 │
└──────────────────┘ └──────────────────┘ └──────────────────┘
💡 框架选型建议:对于生产级应用,LangGraph 是当前最成熟的选择,其图状态编排、检查点持久化和人工介入能力都是企业部署所必需的。对于快速原型验证,LangChain Agents 的简单接口可以更快上手。对于多Agent协作场景,CrewAI 和 AutoGen 提供了更高级的抽象。
09 生产部署架构
将 Agent 从原型推向生产需要考虑可观测性、安全性、可扩展性和成本控制。生产级 Agent 部署架构包含以下关键组件。[3][12]
9.1 生产架构总览
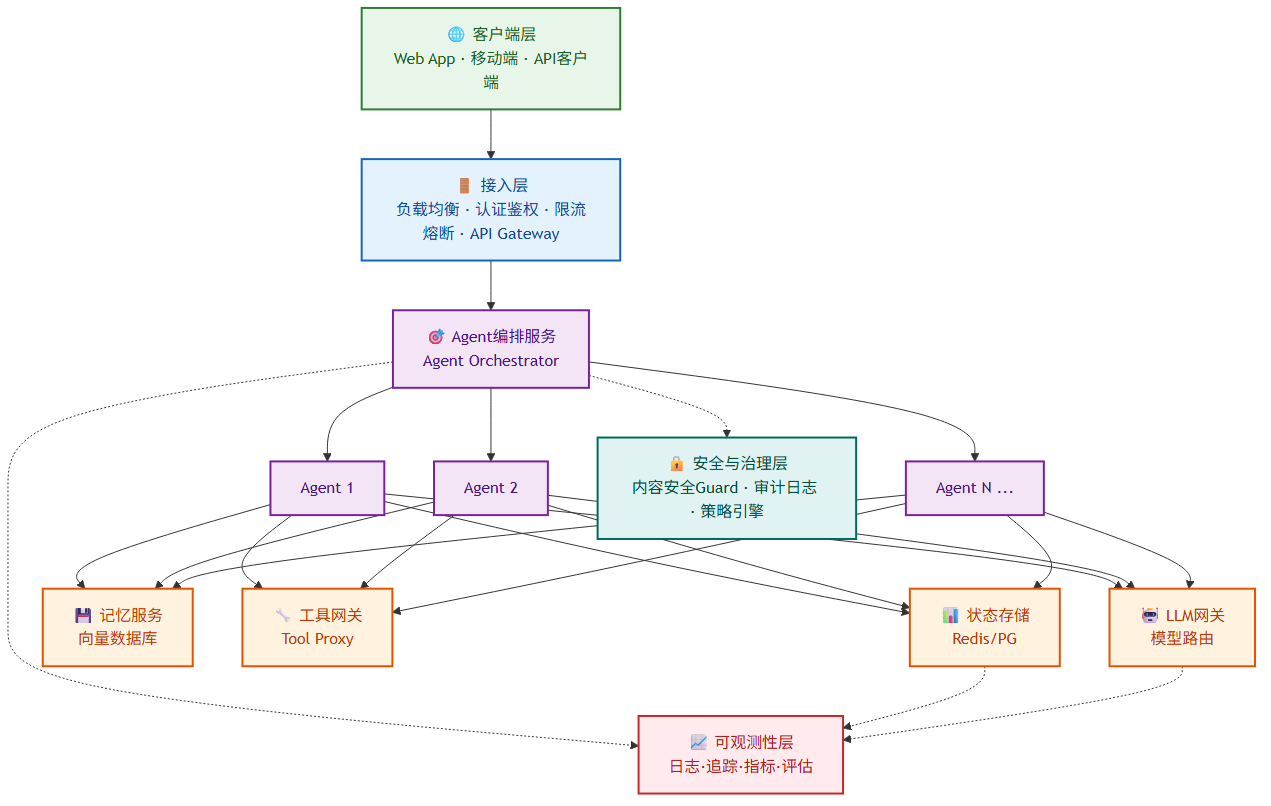
9.2 关键生产组件
| 组件 | 职责 | 说明 |
|---|---|---|
| LLM网关 | 统一管理多模型接入 | 实现模型路由、降级、缓存、成本控制和速率限制。避免应用直接绑定单一模型提供商。 |
| 工具网关 | 代理所有外部工具调用 | 统一处理认证、参数校验、超时重试、熔断降级和访问控制。 |
| 可观测性栈 | 完整的执行追踪 | LangSmith/LangFuse 等工具实现执行追踪、Token用量统计、成本分析和质量评估。 |
| Guardrails | 输入输出过滤 | 防止 prompt 注入、敏感信息泄露和有害内容生成。包括规则引擎和模型双重检查。 |
| 状态持久化 | 会话管理 | 基于 Checkpoint 机制实现会话暂停/恢复、故障转移和时间旅行调试。 |
| 人工介入(HITL) | 关键决策审批 | Agent 可以暂停等待人类输入后继续执行。高风险场景的必要能力。 |
9.3 可扩展性设计
| 扩展维度 | 策略 | 技术方案 |
|---|---|---|
| Agent水平扩展 | 无状态实例 + 外部状态存储 | K8s Deployment + Redis/PostgreSQL 状态后端 |
| LLM调用并发 | 连接池 + 异步队列 + 多模型 | 异步任务队列(Celery/RQ) + 多API Key轮询 |
| 记忆检索 | 向量数据库分片 + 索引优化 | Milvus/Qdrant集群 + HNSW索引 |
| 工具调用 | 工具网关缓存 + 批量调用 | API缓存层 + 并行工具执行 |
10 最佳实践与设计原则
10.1 核心设计原则
原则1:简单优先 (KISS)
从最简单的 ReAct 单 Agent 开始,只有在明确需要时才增加复杂度。多 Agent 不是银弹——很多任务用一个设计良好的单 Agent 就能高效完成。过早引入多 Agent 会增加调试难度和系统复杂度。
原则2:显式优于隐式
Agent 的状态、计划、工具选择应该尽可能显式化。这也是 LangGraph 等图编排框架优于链式调用的原因:显式的状态转移使得系统行为可预测、可调试、可干预。
原则3:防御性设计
永远假设 LLM 可能输出错误格式、选择错误工具或陷入无限循环。系统必须有:
- 参数校验层
- 最大迭代次数限制
- 超时机制
- 降级策略
- 人工介入兜底
原则4:可观测性内建
Agent 系统的调试难度远高于传统软件。从第一天就内建完整的追踪、日志和评估能力,记录每一步的输入输出、思考过程、工具调用和延迟。LangSmith、LangFuse 等工具应作为基础设施而非事后补充。
原则5:成本意识
Agent 应用的成本随迭代次数线性增长。设计时要考虑:
- 模型分层使用(小模型做路由分类,大模型做复杂推理)
- 结果缓存(相同查询不重复调用)
- Token优化(精简提示词、压缩历史)
10.2 常见陷阱与反模式
⚠️ 反模式:过度自主
试图构建"完全自主"的 Agent 而不设边界。生产环境中的 Agent 应该是人机协作的:Agent 负责处理常规情况,关键决策(如发送邮件、修改数据、支付操作)必须经过人类确认。
⚠️ 反模式:工具膨胀
一次性给 Agent 提供几十个工具。LLM 的工具选择能力是有限的,过多工具会导致选择困难和错误调用。应该按需提供工具,或采用分层工具架构(先路由到工具组,再选择具体工具)。
⚠️ 反模式:忽略评估
没有系统化的评估体系就迭代 Agent。Agent 的非确定性使得传统软件测试方法不完全适用。需要建立:基准测试集、输出质量评分、成功率追踪、回归测试机制。
⚠️ 反模式:上下文爆炸
不加控制地往上下文窗口塞入信息。长上下文不仅成本高,还会导致"中间迷失"现象——LLM 容易遗忘上下文中段的信息。应该主动管理上下文:相关信息注入、历史摘要、滑动窗口。
10.3 推荐技术栈 (2026)
| 组件 | 推荐选型 | 备选 |
|---|---|---|
| Agent框架 | LangGraph | LlamaIndex Workflows, CrewAI |
| LLM | GPT-4o / Claude 3.5 Sonnet | DeepSeek-V3, Qwen2.5 (开源) |
| 向量数据库 | Milvus / Qdrant | Pinecone (云), pgvector (小规模) |
| 状态存储 | PostgreSQL + Redis | DynamoDB (AWS生态) |
| 可观测性 | LangSmith / LangFuse | Phoenix, Helicone |
| 部署 | Kubernetes + Docker | Serverless (轻量级场景) |
| 消息队列 | RabbitMQ / Redis Streams | Kafka (高吞吐场景) |
总结
AI Agent 架构设计正在快速走向成熟。从2023年的简单 ReAct 循环,到2025-2026年以图状态编排为核心、持久化记忆为基础、多Agent协作为扩展、生产级可观测性为保障的企业级架构,Agent 技术栈已经准备好支撑真正的业务价值落地。
架构设计的核心始终是:明确目标、控制复杂度、保障可靠性、持续迭代优化。
参考来源
[1] 凤凰网科技, 对话亚马逊云科技G2:当Agent拐点已至,平台中立是最大底气. AWS AI五层技术栈概述. https://finance.ifeng.com/c/8uH2vtwlCmJ
[2] SecurA AI, The Architecture of Intelligence: A Framework for Understanding AI Agent Systems. Agent分层架构模型. https://www.securaai.com/_files/ugd/a3fe6d_9680e4f8083f43848df60cbbcbe7a252.pdf
[3] CSDN, 2026年AI Agent智能体开发实战:从架构设计到生产部署的完整指南. 六层架构设计. https://blog.csdn.net/shaobingj126/article/details/161368617
[4] Microsoft, Multi-Agent Patterns Reference. NLU路由器模式等多Agent模式参考. https://microsoft.github.io/multi-agent-reference-architecture/docs/reference-architecture/Patterns.html
[5] Rustic AI, ReAct Agent Design: Loop-based vs Message-based. ReAct两种实现架构对比. https://rustic-ai.github.io/rustic-ai/design/react-agent-design/
[6] n8n Blog, ReAct Agent: Architecture, Implementation, and Tradeoffs. ReAct工具层和工作记忆分析. https://blog.n8n.io/react-agent/
[7] arXiv, The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey. Agent架构综述和并行工具调用. https://arxiv.org/pdf/2404.11584
[8] TechRxiv, LangChain vs. LangGraph vs. LangSmith: Taxonomies of Agentic AI Toolchains. LangGraph共享状态管理分析. https://www.techrxiv.org/doi/pdf/10.36227/techrxiv.175695645.52670060/v1
[9] LangChain Blog, Building LangGraph: Designing an Agent Runtime from first principles. 检查点机制和Human-in-the-loop设计. https://www.langchain.com/blog/building-langgraph
[10] LangGraph Documentation, Memory. 短期和长期记忆官方文档. https://langchain-ai.github.io/langgraph/agents/memory/
[11] WJAETS, Moving from monolithic to microservices architecture for multi-agent systems. Orchestrator-Worker和Hierarchical模式. https://journalwjaets.com/sites/default/files/fulltext_pdf/WJAETS-2025-0480.pdf
[12] Maxim AI, Building Production-Ready Multi-Agent Systems: Architecture Patterns and Operational Best Practices. 多Agent生产最佳实践. https://www.getmaxim.ai/articles/best-practices-for-building-production-ready-multi-agent-systems/
[13] AI Void, Understanding AI Agent Memory Systems: A Practical Guide. 向量数据库和记忆系统实践. https://media.aivoid.dev/pdfs/understanding-ai-agent-memory-systems-a-practical-guide_20260504175832.pdf
[14] Mem0, LangGraph Tutorial: How to Build Smarter AI Agents with Memory. 持久化记忆对Agent性能的提升. https://mem0.ai/blog/langgraph-tutorial-build-advanced-ai-agents
[15] Salesforce, ReAct Agent: The Ultimate Guide to the Reason and Act Framework for LLMs. LLM作为大脑和记忆管理. https://www.salesforce.com/ap/agentforce/ai-agents/react-agents/
[16] LangChain Blog, Building LangGraph: Designing an Agent Runtime from first principles. 检查点机制设计. https://www.langchain.com/blog/building-langgraph
[17] AWS, Building persistent memory for multi-agent AI systems with Amazon S3 Vectors. 个体记忆与共享多Agent记忆. https://aws.amazon.com/blogs/storage/building-persistent-memory-for-multi-agent-ai-systems-with-amazon-s3-vectors/
[18] Milvus, LangChain 1.0 and Milvus: How to Build Production-Ready Agents with Real Long-Term Memory. Milvus作为长期记忆层. https://milvus.io/ru/blog/langchain-and-milvus-build-production-ready-agents-with-real-long-term-memory.md
[19] CSDN, AI Agent的Function Calling架构设计与实战解析. Tool Schema六层设计模型. https://blog.csdn.net/csdn122345/article/details/161204132
[20] Spice AI, What is LLM Tool Calling?. 工具调用交互流程定义. https://spice.ai/learn/llm-tool-calling
[21] DevPath, LLM Tool Calling Architectures for AI Agents. 三种工具调用架构模式. https://www.devpath.com/courses/generative-ai-system-design/llm-tool-calling-architectures-for-ai-agents
评论区