



🎯 本教程适合谁?
- 想用大模型做产品但被推理速度/成本困扰的开发者
- 想理解大模型推理引擎原理的 AI 学习者
- 需要将 LLM 部署到生产环境的技术团队
📖 前置知识(不必须,但有帮助)
- 了解 Python 基础语法
- 对大语言模型(如 ChatGPT)有基本认识
- 了解 GPU 和显存的基本概念
1. 开篇:vLLM 是什么?为什么你需要它?
1.1 一个生活中的例子
想象你开了一家奶茶店:
- 传统方式(HuggingFace Transformers):每来一位客人,你从和面、煮珍珠开始从头做一杯奶茶。虽然每一杯都是"现做",但效率极低,客人一多就排长队。
- vLLM 方式:你提前准备好茶底、煮好珍珠,客人点单时只需组装即可。而且你还能同时做多杯,互不干扰。
💡 一句话总结:vLLM 让大模型"做奶茶"的效率提升了 10~100 倍,而且完全不改变奶茶的味道(模型精度无损)。
1.2 什么是 vLLM
vLLM(发音:/viː el el em/,全称 virtual LLM)是由加州大学伯克利分校、斯坦福大学和加州大学圣迭戈分校联合开发的高性能大语言模型推理和服务引擎。
用更直白的话说:
- 大模型推理引擎 = 让大模型"跑起来"的发动机
- 传统引擎(如 HuggingFace Transformers)显存管理很粗糙,浪费严重
- vLLM 发明了一套全新的内存管理方法(PagedAttention),把 GPU 显存用到了极致
1.3 核心优势(为什么选它)
| 特性 | 一句话解释 | 能帮你解决什么问题 |
|---|---|---|
| 超高吞吐量 | 比传统方式快 10~100 倍 | 同样的 GPU,服务更多用户,成本更低 |
| PagedAttention | 像操作系统管理内存一样管理显存 | 显存利用率从 40% 飙升到 95%+ |
| 连续批处理 | 不等上一批全跑完,新请求随时插入 | 排队时间大幅缩短,GPU 不闲置 |
| OpenAI 兼容 API | API 接口和 OpenAI 一模一样 | 现有代码一行不用改,直接切换 |
| 多硬件支持 | NVIDIA、AMD、Intel 都行 | 不被某一家硬件绑定 |
| 丰富模型支持 | Llama、Qwen、ChatGLM、Baichuan… | 主流模型开箱即用 |
1.4 什么时候用 vLLM?(适用场景)
| 场景 | 举个例子 | 为什么 vLLM 适合 |
|---|---|---|
| 🏢 高并发 API 服务 | 给 1000 个用户同时提供 AI 聊天 | 显存高效利用 → 能同时处理更多请求 |
| 📊 离线批量推理 | 一天处理 100 万条客服记录 | 吞吐量高 → 同样的时间处理更多数据 |
| ☁️ 多租户服务 | SaaS 平台给不同公司提供 AI 能力 | 支持 LoRA 动态切换,一套服务多个模型 |
| 📱 边缘部署 | 在 8GB 显存的消费级显卡上跑 | 量化 + 高效缓存,资源受限也能跑 |
2. 核心原理:PagedAttention — 大模型的"内存革命"

🎯 学习目标:理解 PagedAttention 为什么是 vLLM 的核心创新,以及它是如何让推理速度飞跃的。
📖 前置知识:了解大模型推理中"KV 缓存"是什么(下面会通俗解释)。
2.1 先搞懂:大模型推理时,显存在干什么?
要理解 PagedAttention 有多牛,得先知道传统方式有多"笨"。
什么是 KV 缓存?
大模型生成文本是一个"逐字造句"的过程:
用户问:"中国的首都是什么?"
模型内心活动:
第1步:看到问题 → 生成 "北"
第2步:看到问题 + "北" → 生成 "京"
第3步:看到问题 + "北京" → 生成 "是"
第4步:看到问题 + "北京是" → 生成 "中"
...
你发现了吗?每走一步,它都要把之前说过的话"再看一遍"。这就好比你写文章时,每写一个字都要重读一遍全文——太浪费了!
KV 缓存就是用来解决这个问题的"小抄":模型把之前算过的结果存起来,下一步直接查小抄,不用重新算。
🤔 KV 是什么?
- K(Key) 和 V(Value) 是 Transformer 注意力机制中的两个矩阵
- 你可以简单理解为:K 是"关键词索引",V 是"关键词对应的内容"
- 它们合在一起就是模型的"短期记忆"
2.2 传统方式的问题:就像一个混乱的图书馆
想象一个图书馆,每个读者(请求)有一张固定大小的书桌(连续内存空间):
传统分配方式:
读者A(短请求,只看1本书)→ 分到一张 4人桌 → ❌ 浪费3个座位
读者B(长请求,要看10本书)→ 分到一张 4人桌 → ❌ 座位不够,坐不下
读者C(中等请求)→ 分到一张 4人桌 → 📍 刚好够用
读者A走了 → 他的4人桌空出来了 → 但因为大小固定
新来的读者D(需要3个座位)坐不进去 → ❌ 碎片浪费
这就是传统 KV 缓存的三大痛点:
| 问题 | 图书馆类比 | 技术后果 |
|---|---|---|
| 🧩 内存碎片 | 桌子大小不一,人走了桌子碎一地 | 明明有空闲内存,但都凑不齐一整块 |
| 📉 内存浪费 | 给每人一张大桌子,大部分空着 | 实际利用率只有 20%~40% |
| 🚫 吞吐量低 | 图书馆座位有限,浪费一个就少服务一个人 | 同一时间能处理的请求数受限 |
2.3 PagedAttention 的创新:像操作系统管理内存一样管理显存
操作系统(Linux/Windows)管理电脑内存时,用的是**分页(Paging)**技术——把内存切成 4KB 的小块,程序要用哪块就用哪块,不要求连续。
PagedAttention 把这个思想搬到了 GPU 显存里:
📦 KV 缓存被切成统一大小的"块"(Block),每块默认存 16 个 token
传统方式(连续分配):
读者A: [████████████] ← 一整张连续的大桌子
读者B: [████████] ← 另一张连续的大桌子
空闲: [░░░░░░░░░░] ← 碎片,谁也塞不进去
✨ PagedAttention(分页管理):
读者A: [块3][块7][块1][块9] ← 物理上不连续,但逻辑上是连续的
读者B: [块5][块2] ← 灵活分配,按需取用
物理显存分布:
[块3][块5][块7][块1][块2][块9] ← 所有块整整齐齐,没有碎片!
三个关键角色
| 概念 | 图书馆类比 | 技术含义 |
|---|---|---|
| KV Block(块) | 图书馆的一个标准座位(固定大小) | 默认存 16 个 token 的 KV 缓存,所有块大小一样 |
| Block Table(块表) | 每个读者的座位地图(“你的座位在 3 排 5 号、2 排 7 号…”) | 记录一个请求的逻辑块对应哪些物理块 |
| Block Manager(块管理器) | 图书馆的管理员(统筹分配座位) | 全局管理所有物理块的分配与释放 |
2.4 为什么说这是革命性的?
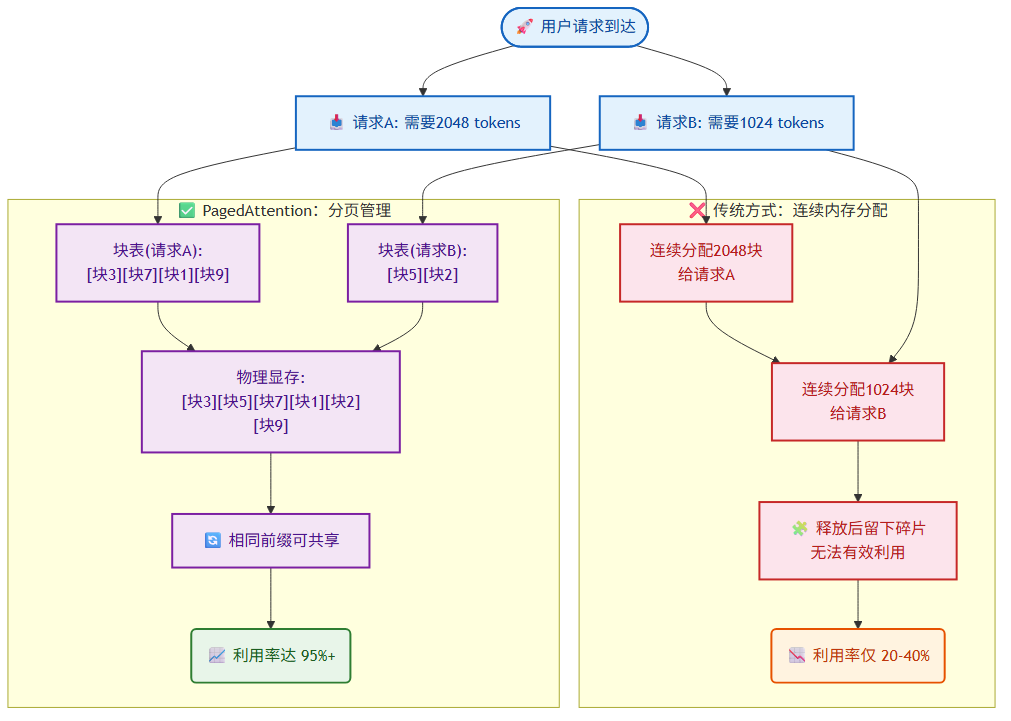
传统方式 PagedAttention
────────── ──────────────
内存利用率 30% 内存利用率 95%+ ← 几乎用满!
碎片化严重 几乎零碎片 ← 所有块一样大
固定分配 按需分配 ← 用多少分多少
不可共享 支持共享 ← 相同前缀可共用
额外福利:前缀共享(Prefix Caching)
这是 PagedAttention 的一个"彩蛋"功能。
场景:假设 100 个用户同时问:“请用 Python 写一个快速排序算法…”
- 传统方式:100 个请求各自存一份"请用 Python 写一个快速排序算法…"的 KV 缓存
- vLLM 方式:只存一份,100 个请求共享!省了 99% 的显存!
💡 一句话总结 PagedAttention:
就像把图书馆里不固定的"大桌子"换成了统一的"小格子座位"——座位利用率更高、读者能灵活占座、管理员调度也更轻松。
3. 环境准备与安装 — 5 分钟让 vLLM 跑起来
🎯 学习目标:在你的机器上成功安装 vLLM 并跑通第一个示例。
📖 前置知识:熟悉终端命令行基础操作。
3.1 你的机器够用吗?(系统要求)
安装前先检查一下你的环境。别担心,即使配置不高,也能用小模型跑起来!
| 组件 | ⚡ 最低要求(能跑就行) | 🚀 推荐配置(爽快体验) |
|---|---|---|
| 操作系统 | Linux (Ubuntu 20.04+) 或 WSL2 | Ubuntu 22.04 LTS |
| Python | 3.9 | 3.10~3.12 |
| GPU (NVIDIA) | CUDA 12.1+,显存 8GB+(如 RTX 3070) | A100/H100,显存 40GB+ |
| CPU | 4 核 | 16 核以上 |
| 内存 | 16GB | 64GB 以上 |
💡 没有 GPU 怎么办?
- 可以用 CPU 模式(速度慢但能学习):安装
pip install vllm-cpu- 也可以用 Google Colab 免费 GPU 体验(T4 显卡,够用!)
- 或者用 AutoDL/恒源云 等平台租用 GPU,按小时计费
检查你的 CUDA 版本
# 打开终端,输入:
nvidia-smi
# 查看输出顶部的 "CUDA Version" 字段
# 如果是 12.1 或更高,就满足要求!
# 如果是 11.x,需要先升级 CUDA
⚠️ 新手注意:
nvidia-smi显示的 CUDA 版本是驱动支持的最高版本,不一定是当前使用的版本。想确认实际版本:nvcc --version。
3.2 四种安装方式,选哪个?
| 方式 | 难度 | 推荐场景 | 一句话评价 |
|---|---|---|---|
| 🥇 pip 安装 | ⭐ | 大多数人 | 最简单,一行命令搞定 |
| 🥈 uv 安装 | ⭐⭐ | 追求速度的开发者 | pip 的"涡轮增压版",快 10 倍 |
| 🥉 Docker | ⭐⭐ | 生产环境 | 开箱即用,隔离性好 |
| 🏅 源码编译 | ⭐⭐⭐⭐⭐ | 开发者/研究 | 定制化最高,但对新手不友好 |
方式一:pip 安装(⭐ 强烈推荐)
这是最常用的方式,适合 99% 的场景。
# 【第一步】创建虚拟环境(强烈建议!避免和系统 Python 打架)
# 用 Python 自带的 venv 模块创建一个干净的"小房间"
python -m venv vllm-env
# 进入这个"小房间"(Windows 用 vllm-env\Scripts\activate)
source vllm-env/bin/activate
# 【第二步】安装 vLLM
# 注意:pip 会自动检测你的 CUDA 版本并下载匹配的预编译包
pip install vllm
# 【第三步】验证安装成功
python -c "import vllm; print(f'vLLM 版本: {vllm.__version__}')"
# 如果打印出版本号(如 0.7.0),就成功了!🎉
💡 为什么需要虚拟环境?
想象你的电脑是一个大房间,所有 Python 包(库)都乱堆在一起。装 A 项目要 version 1.0,装 B 项目要 version 2.0,就会打架!
虚拟环境就是给每个项目一个独立的"小房间",互不干扰。
方式二:使用 uv 安装(🚀 速度更快)
uv 是一个用 Rust 写的 Python 包管理器,安装速度比 pip 快 10~100 倍。
# 【第一步】安装 uv(如果还没装)
curl -LsSf https://astral.sh/uv/install.sh | sh
# 【第二步】创建虚拟环境并安装
uv venv myenv --python 3.12 --seed # --seed 表示同时安装 pip
source myenv/bin/activate
# 【第三步】安装 vLLM(感受下速度差异!)
uv pip install vllm
方式三:Docker 部署(🐳 生产环境推荐)
Docker 就像给 vLLM 装进一个集装箱——环境完全隔离,拿到哪都能跑。
# 【第一步】拉取官方镜像(类似下载一个"vLLM 系统镜像")
docker pull vllm/vllm-openai:latest
# 【第二步】运行容器
# --gpus all : 给容器分配所有 GPU
# -p 8000:8000 : 把容器内的 8000 端口映射到本机
# --model ... : 指定要加载的模型
docker run --gpus all -p 8000:8000 \
vllm/vllm-openai:latest \
--model Qwen/Qwen2.5-1.5B-Instruct
# 现在打开浏览器访问 http://localhost:8000/docs 就能看到 API 文档了!
⚠️ Docker 注意事项:
- 需要提前安装 Docker 和 NVIDIA Container Toolkit
- 如果拉取镜像慢,可以配置 Docker 国内镜像加速
方式四:从源码安装(🔧 开发者专用)
只有以下情况才需要这样做:
- 你想修改 vLLM 源码
- 你的硬件/系统比较特殊,预编译包不支持
- 你想体验最新(未发布)的功能
# 克隆完整的 vLLM 源码仓库到本地
git clone https://github.com/vllm-project/vllm.git
cd vllm
# 以"可编辑模式"安装(-e),这样修改源码后无需重新安装
pip install -e .
⚠️ 源码编译对新手不友好!编译过程可能遇到各种系统依赖问题,除非你知道自己在做什么,否则建议优先使用 pip 安装。
3.3 🎯 验证安装:跑通你的第一个 vLLM 程序
安装完成后,我们来写一个最简单的测试程序,确保一切正常工作。
创建测试文件
新建一个文件 test_vllm.py,写入以下代码:
from vllm import LLM, SamplingParams
# ===========================================
# 第一步:加载模型
# ===========================================
# LLM 是 vLLM 的核心类,负责管理模型和推理
# 这里我们用 Qwen2.5-1.5B(15 亿参数的小模型),
# 8GB 显存的显卡就能运行!
print("🔄 正在加载模型...(第一次会下载,请耐心等待)")
llm = LLM(model="Qwen/Qwen2.5-1.5B-Instruct")
# ===========================================
# 第二步:配置生成参数
# ===========================================
# SamplingParams 控制模型如何"选择下一个词"
sampling_params = SamplingParams(
temperature=0.8, # 🌡️ 温度:控制随机性(0=稳定保守,1=天马行空)
top_p=0.95, # 🎯 核采样:只从概率最高的前 95% 的词中选择
max_tokens=100, # 📏 最多生成 100 个 token(约 70 个汉字)
)
# ===========================================
# 第三步:让它说句话
# ===========================================
outputs = llm.generate("你好,请介绍一下自己。", sampling_params)
# ===========================================
# 第四步:看结果
# ===========================================
for output in outputs:
prompt = output.prompt # 输入的内容
generated = output.outputs[0].text # 模型生成的内容
print(f"\n📝 输入: {prompt}")
print(f"✨ 输出: {generated}")
print(f"🔢 生成了 {len(output.outputs[0].token_ids)} 个 token")
运行测试
# 确保在虚拟环境中
python test_vllm.py
预期输出(类似这样):
🔄 正在加载模型...(第一次会下载,请耐心等待)
(这里会显示模型下载进度条,取决于你的网速)
📝 输入: 你好,请介绍一下自己。
✨ 输出: 你好!我是 Qwen,一个由阿里云开发的大语言模型...
🔢 生成了 85 个 token
🎉 看到输出了吗?恭喜你,vLLM 已经成功跑起来了!
⚠️ 第一次运行会慢一些,因为需要下载模型文件(约 1~3GB)。之后运行会直接从缓存加载,快很多。
💡 如果显存不够:可以把模型换成更小的,如
Qwen/Qwen2.5-0.5B-Instruct(5 亿参数,4GB 显存就够)。
4. 快速入门 — 上手实战
🎯 学习目标:学会用 vLLM 做离线推理和启动 API 服务,并调用它。
📖 前置知识:完成了第 3 章的安装,基础 Python 知识。
4.1 📦 离线批量推理 — 一次跑多个任务
"离线推理"就是不需要实时响应的场景,比如:一次性处理 1 万条客服记录、批量生成文章摘要。
基础用法(单条输入 → 单条输出)
from vllm import LLM, SamplingParams
# ===========================================
# 1. 加载模型
# ===========================================
# 这里用 7B 模型(70 亿参数),需要约 16GB 显存
# 如果显存不够,可以换成 "Qwen/Qwen2.5-1.5B-Instruct"
llm = LLM(
model="Qwen/Qwen2.5-7B-Instruct",
# trust_remote_code=True 的作用:
# 有些模型的代码不在 HuggingFace 标准库中,需要加载模型自带的代码
# 安全提示:只在信任的模型来源使用
trust_remote_code=True,
# tensor_parallel_size=1 表示只用 1 张 GPU
# 如果有多张 GPU 可以设为 2、4...(详见第 5.4 节)
tensor_parallel_size=1,
)
# ===========================================
# 2. 配置采样参数(控制模型怎么"说话")
# ===========================================
# 每个参数的作用,下面都给你讲透了
sampling_params = SamplingParams(
# 🌡️ temperature(温度):0~2 之间的数
# 0 = 每次选概率最高的词 → 稳定但机械
# 0.7 = 偶尔选概率低的词 → 有创意但不离谱
# 1.0+ = 经常选冷门词 → 天马行空,可能胡说八道
temperature=0.7,
# 🎯 top_p(核采样阈值):0~1 之间的数
# 只保留概率加起来达到 top_p 的候选词
# 0.9 表示:从概率最高的词里选,直到累计概率到 90%
# 作用是砍掉概率极低的"离谱选项"
top_p=0.9,
# 📏 max_tokens:最多生成多少个 token
# 注意:一个中文汉字 ≈ 1~2 个 token
# 设太小 → 话没说完就断了;设太大 → 可能啰嗦
max_tokens=512,
# 🔄 frequency_penalty(频率惩罚):-2~2
# 正数 → 避免重复用同一个词(说过的词扣分)
# 0 → 不干预
# 负数 → 鼓励重复(写诗时可能有用)
frequency_penalty=0.0,
# 🔄 presence_penalty(存在惩罚):-2~2
# 和 frequency_penalty 类似,但更狠——只要出现过的词都扣分
# 鼓励模型聊新话题,而不是反复说同一个词
presence_penalty=0.0,
# ⏹️ stop:遇到这些词就停止生成
# 像句号一样,告诉模型"话说到这里就够了"
stop=["<|endoftext|>"],
)
# ===========================================
# 3. 批量输入 — 一次喂多个问题
# ===========================================
# vLLM 会自动把这些问题"打包"处理,比一个一个跑快很多
prompts = [
"请解释什么是机器学习?用简单的话说。",
"写一首关于春天的诗,四行就行。",
"用 Python 实现一个快速排序算法,加上注释。",
]
print(f"🚀 开始处理 {len(prompts)} 个请求...")
outputs = llm.generate(prompts, sampling_params)
print("✅ 全部处理完成!\n")
# ===========================================
# 4. 处理输出结果
# ===========================================
for i, output in enumerate(outputs):
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"━━━ 请求 {i+1} ━━━")
print(f"📝 输入: {prompt[:50]}...") # 只显示前 50 个字符
print(f"✨ 输出: {generated_text[:200]}...") # 只显示前 200 个字符
print(f"📊 Token 数: {len(output.outputs[0].token_ids)}")
print()
💡 为什么批量推理比单个循环快?
就像去食堂打饭:一个一个去(单条处理)需要来回跑很多趟;一次性把所有人的饭卡收齐(批量处理),食堂阿姨一次搞定,效率翻倍。vLLM 的连续批处理技术还能让新请求"插队"到正在处理的批次中,GPU 一刻也不闲着。
🚀 进阶用法:流式异步推理(Streaming + Async)
适合需要实时显示生成过程的场景,比如 AI 聊天对话框里的"打字效果"。
import asyncio
from vllm import AsyncLLMEngine, SamplingParams
from vllm.engine.arg_utils import AsyncEngineArgs
async def main():
# 配置引擎参数(和离线模式类似,但用 AsyncEngineArgs)
engine_args = AsyncEngineArgs(
model="Qwen/Qwen2.5-7B-Instruct",
tensor_parallel_size=1,
)
# 创建异步引擎
# 异步 = 不阻塞主线程,可以同时处理其他事情
engine = AsyncLLMEngine.from_engine_args(engine_args)
# 采样参数(和之前一样)
sampling_params = SamplingParams(max_tokens=256, temperature=0.8)
# 发送请求(需要给每个请求一个唯一 ID)
request_id = "request-001"
results_generator = engine.generate(
"请介绍一下深度学习的发展历史,用 3 个阶段来说。",
sampling_params,
request_id
)
# 🔄 流式获取结果
# async for 表示"来一个处理一个",不等全部生成完
print("🤖 模型正在思考...")
async for request_output in results_generator:
if len(request_output.outputs) > 0:
# 每次拿到最新的已生成文本
text = request_output.outputs[0].text
# \r 让光标回到行首,实现"原地刷新"的打字效果
print(f"\r生成中: {text}", end="", flush=True)
print("\n✅ 生成完成!")
# Python 3.7+ 的异步入口
asyncio.run(main())
💡 同步 vs 异步?
- 同步(同步阻塞):你点外卖,一直盯着手机等,不干别的事 → 简单但浪费
- 异步(异步非阻塞):你点完外卖,边看电视边等,外卖到了再取 → 高效
- 流式:外卖小哥送一勺汤你就喝一勺,不用等整份饭做好 → 用户体验好
4.2 🌐 启动 API 服务 — 让模型"在线接单"
离线模式适合批量处理,但如果你要做网站/App 的后端,需要模型像 Web 服务一样"随时待命"。这时候就用 API 模式。
方式一:命令行启动(简单直接)
# 一行命令启动一个完整的 OpenAI 兼容 API 服务
vllm serve Qwen/Qwen2.5-7B-Instruct \
--host 0.0.0.0 \ # 监听所有网络接口(0.0.0.0 = 允许外部访问)
--port 8000 \ # 服务端口(类似 Web 服务器的 80 端口)
--api-key your-api-key \ # API 密钥(防止未授权访问)
--served-model-name qwen-7b \ # 对外显示的模型名(可以随便起名)
--max-model-len 4096 \ # 最大上下文长度(越长越耗显存)
--gpu-memory-utilization 0.9 # GPU 显存利用率(0.9 = 90%)
启动后你会看到类似这样的输出:
INFO: Started server process [12345]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
🎉 现在你的模型就"在线"了!访问
http://localhost:8000/docs可以看到自动生成的 API 文档页面。
方式二:Python 脚本启动(更灵活)
适合需要和 Python 代码深度集成的场景。
# server.py
from vllm.entrypoints.openai.api_server import run
import uvicorn
if __name__ == "__main__":
uvicorn.run(
"vllm.entrypoints.openai.api_server:app", # Flask/FastAPI 风格的路由
host="0.0.0.0",
port=8000,
log_level="info",
)
# 运行方式
python server.py
# 可以加命令行参数覆盖默认配置
vllm serve Qwen/Qwen2.5-7B-Instruct --port 8000
4.3 📞 调用 API 服务 — 像用 OpenAI 一样用 vLLM
vLLM 的 API 完全兼容 OpenAI 的接口格式,这意味着:
🔄 “如果你会用 OpenAI 的 API,那你已经会了 vLLM 的 API”
唯一的区别:把
https://api.openai.com/v1换成http://localhost:8000/v1。
使用 curl 测试(命令行)
# 【测试 1】列出可用模型(相当于"菜单")
curl http://localhost:8000/v1/models \
-H "Authorization: Bearer your-api-key"
# 预期返回:
# {
# "data": [
# {"id": "qwen-7b", "object": "model", ...}
# ]
# }
# 【测试 2】聊天补全(核心功能)
# 注意:stream=true 表示启用流式输出
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your-api-key" \
-d '{
"model": "qwen-7b",
"messages": [
{"role": "system", "content": "你是一个 helpful 的助手。"},
{"role": "user", "content": "什么是大语言模型?"}
],
"temperature": 0.7,
"max_tokens": 512,
"stream": true
}'
# 流式输出时会看到 data: {"choices":[{"delta":{"content":"大"}}]}
# data: {"choices":[{"delta":{"content":"语言"}}]}
# ... 一个字一个字地返回
使用 OpenAI Python SDK(开发最常用)
这是在实际项目中最常用的方式,代码和调用 OpenAI 几乎一模一样:
from openai import OpenAI
# ===========================================
# 初始化客户端
# ===========================================
# 唯一的区别:把 api_base 换成你的 vLLM 服务地址
# 其他代码完全不用改!
client = OpenAI(
base_url="http://localhost:8000/v1", # 👈 vLLM 的服务地址
api_key="your-api-key" # 👈 你设置的 API 密钥
)
# ===========================================
# 聊天补全(非流式)
# ===========================================
response = client.chat.completions.create(
model="qwen-7b",
messages=[
{"role": "system", "content": "你是一个专业的技术顾问。"},
{"role": "user", "content": "解释一下 PagedAttention 的工作原理,用大白话说。"}
],
temperature=0.7,
max_tokens=1024,
# stream=False 表示等全部生成完再返回
)
print(response.choices[0].message.content)
# ===========================================
# 流式版本(适合聊天 UI)
# ===========================================
response = client.chat.completions.create(
model="qwen-7b",
messages=[
{"role": "system", "content": "你是一个专业的 AI 助手。"},
{"role": "user", "content": "用 Python 实现一个二分查找。"}
],
temperature=0.7,
max_tokens=1024,
stream=True, # 👈 启用流式输出
)
# 逐块接收生成的内容,实现"打字机效果"
print("🤖: ", end="", flush=True)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # 最后换行
💡 迁移现有 OpenAI 项目的秘诀:
# 旧代码(调用 OpenAI) client = OpenAI(api_key="sk-xxx") # 新代码(调用 vLLM)—— 只需要改两行! client = OpenAI( base_url="http://localhost:8000/v1", # 改这行 api_key="your-api-key" # 改这行 ) # 其他代码完全不用动!✅
5. 核心功能详解 — 让你的 vLLM 更强大
🎯 学习目标:掌握 vLLM 的高级功能,包括模型压缩、多卡推理、多模态等,应对各种实战场景。
📖 前置知识:完成了第 4 章的基础实践。
5.1 🗜️ 量化(Quantization)— 给模型"瘦身"
为什么要量化?
想象你有一张超清照片(4K,50MB),但你的手机内存只剩 10MB 了。怎么办?
- 不处理:照片存不进去 ❌
- 压缩成 JPEG(类似量化):画质稍微降低一点,但文件变成 2MB ✅
量化就是给模型"压缩":
| 原始状态 | 量化后 | 效果 |
|---|---|---|
| 参数用 FP32(32 位浮点数)存 | 用 INT4(4 位整数)存 | 体积缩小 8 倍! |
| 一个参数占 4 字节 | 一个参数占 0.5 字节 | 显存需求大幅降低 |
效果:模型变小了 → 可以放进更小的显存 → 省 GPU 钱!
三种量化方式对比
| 量化方式 | 显存节省 | 速度变化 | 精度影响 | 硬件要求 |
|---|---|---|---|---|
| AWQ(精度优先) | ~50% | +10~20% | 极小 | 任何 NVIDIA GPU |
| GPTQ(平衡) | ~50% | +10~20% | 较小 | 任何 NVIDIA GPU |
| FP8(速度优先) | ~50% | +20~30% | 极小 | H100/H200 等新卡 |
💡 怎么选?
- 显存紧张(如 RTX 3060 12GB 跑 7B 模型)→ AWQ/INT4,省 75% 显存
- 精度敏感(如医疗、法律场景)→ FP8 或 AWQ,精度损失最小
- 追求速度(H100 用户)→ FP8,还附赠速度提升
使用量化模型
# AWQ 量化(最常用,精度损失小)
# 注意:需要下载专门的 AWQ 版本模型(以 -AWQ 结尾)
vllm serve TheBloke/Qwen2.5-7B-Instruct-AWQ \
--quantization awq \
--max-model-len 8192
# GPTQ 量化
vllm serve TheBloke/Qwen2.5-7B-Instruct-GPTQ \
--quantization gptq \
--max-model-len 8192
# FP8 量化(需要 H100/H200 等支持 FP8 的 GPU)
vllm serve Qwen/Qwen2.5-7B-Instruct \
--quantization fp8 \
--max-model-len 8192
量化效果对比表
| 量化方式 | 显存占用 | 推理速度 | 精度损失 | 适用场景 |
|---|---|---|---|---|
| FP16/BF16(不量化) | 100% | 基准(1x) | 无 | 追求最高精度,显存充足 |
| INT8 (AWQ/GPTQ) | ~50% | +10~20% | 极小 | 通用场景,平衡选择 |
| INT4 (AWQ) | ~25% | +30~50% | 较小 | 显存受限的消费级显卡 |
| FP8 | ~50% | +20~30% | 极小 | H100+ 新显卡专属优化 |
⚠️ 量化注意事项:
- 不是所有模型都有量化版本,需要去 HuggingFace 搜索
-AWQ或-GPTQ后缀的模型- 量化后的模型不能再微调(但可以用 LoRA 适配器微调,见下一节)
5.2 🎛️ LoRA 适配器支持 — 一套模型,多个"人设"
什么是 LoRA?
LoRA(Low-Rank Adaptation,低秩适配)是一种高效的模型微调技术。
场景:你有一个通用的基座模型(如 Qwen2.5-7B),你想让它同时具备三种能力:
- 当法律顾问 → 知道法条和判例
- 当代码助手 → 精通各种编程语言
- 当文学作家 → 能写诗和小说
传统方案:训练三个独立的模型 → 需要 3 份显存 ❌
LoRA 方案:只训练三个小的"适配器"(每个只有几 MB),共享同一个基座模型 → 切换只需加载适配器 ✅
# 启动时启用 LoRA 支持
vllm serve Qwen/Qwen2.5-7B-Instruct \
--enable-lora \ # 开启 LoRA 功能
--max-loras 5 \ # 最多同时加载 5 个 LoRA 适配器
--max-lora-rank 64 \ # LoRA 的秩(越大适配能力越强,也越耗显存)
--lora-extra-vocab-size 256 # 如果 LoRA 引入了新词,需要预留空间
Python 中使用 LoRA
from vllm import LLM, SamplingParams
from vllm.lora.request import LoRARequest
# 加载基座模型,同时启用 LoRA
llm = LLM(
model="Qwen/Qwen2.5-7B-Instruct",
enable_lora=True,
max_loras=4, # 最多 4 个适配器同时驻留内存
)
sampling_params = SamplingParams(max_tokens=256, temperature=0.7)
# 切换不同的 LoRA 适配器,得到不同的"人设"回复
# 每个 LoRA 适配器是一个很小的文件(通常 10~100 MB)
outputs = llm.generate(
["请写一个产品营销文案。(用营销专家的语气)"],
sampling_params,
lora_request=LoRARequest(
lora_name="marketing-lora", # 适配器名称
lora_int_id=1, # 适配器 ID
lora_path="./lora-marketing" # 适配器文件路径
)
)
💡 什么时候用 LoRA?
- 需要让同一个模型服务多个垂直领域(法律、医疗、金融…)
- 想在基座模型上快速定制风格或知识
- 显存有限,不想为每个任务都部署一个完整模型
5.3 👁️ 多模态支持 — 让模型"看懂"图片
vLLM 0.4+ 版本开始支持视觉语言模型(VLM),也就是不仅能理解文字,还能理解图片。
启动多模态服务
vllm serve Qwen/Qwen2-VL-7B-Instruct \
--trust-remote-code \
--max-model-len 8192 \
--limit-mm-per-prompt image=4 \ # 每个请求最多 4 张图片
--gpu-memory-utilization 0.9
调用多模态 API
from openai import OpenAI
import base64
client = OpenAI(base_url="http://localhost:8000/v1", api_key="token-abc123")
# 辅助函数:把图片文件转成 base64 编码(图片的"文本表示")
def encode_image(image_path):
"""读取图片文件,返回 base64 编码的字符串"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# 读取你的图片
base64_image = encode_image("example.jpg")
response = client.chat.completions.create(
model="Qwen/Qwen2-VL-7B-Instruct",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "请描述这张图片的内容。"},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}
# data:image/jpeg;base64, 表示这是一张内嵌的 JPEG 图片
}
]
}
],
max_tokens=512
)
print(response.choices[0].message.content)
⚠️ 多模态注意事项:
- 目前只支持图片输入,不支持视频或音频
- 图片会占用额外的显存(每张图片约 ~1GB 显存)
- 需要选择支持多模态的模型(如 Qwen2-VL、LLaVA、InternVL)
5.4 🔗 张量并行(多卡推理)— 用多张 GPU 跑大模型
为什么需要多卡?
想象你要搬一个800 斤的沙发(大模型如 72B):
- 你一个人(1 张 GPU)根本搬不动 ❌
- 4 个人(4 张 GPU)一起抬,每个人只承担 200 斤 ✅
张量并行就是把模型切成多份,每张 GPU 负责一份,协同工作。
# 用 2 张 GPU 跑一个 72B 模型
vllm serve Qwen/Qwen2.5-72B-Instruct \
--tensor-parallel-size 2 \ # 2 张 GPU 并行
--max-model-len 4096
# 用 4 张 GPU(指定使用哪几张)
CUDA_VISIBLE_DEVICES=0,1,2,3 vllm serve Qwen/Qwen2.5-72B-Instruct \
--tensor-parallel-size 4 # 4 张 GPU 并行
💡 CUDA_VISIBLE_DEVICES:控制"哪些 GPU 对程序可见"。
- 不加这个参数:默认使用所有 GPU
CUDA_VISIBLE_DEVICES=0,1:只使用 GPU 0 和 GPU 1- 这在你和别人共用服务器时特别有用
5.5 ⚡ 前缀缓存(Prefix Caching)— 相同的开头只算一次
场景:100 个用户同时问:“请用 Python 实现一个冒泡排序算法,加上详细的注释”
- 传统的做法:每个请求都重新计算"请用 Python 实现…"这一段 → 浪费 100 次计算
- 前缀缓存:只计算一次,100 个请求共享计算结果 → 省了 99% 的计算量!
llm = LLM(
model="Qwen/Qwen2.5-7B-Instruct",
enable_prefix_caching=True, # 启用前缀缓存
max_num_seqs=256, # 最多同时处理 256 个请求
)
💡 特别适合这些场景:
- 所有请求共享同一个 System Prompt(系统提示词)
- 聊天机器人有固定的"开场白"
- 多轮对话中,历史消息越长,缓存效果越明显
6. 性能优化指南 — 把 GPU 的每一分钱用到极致
🎯 学习目标:学会通过各种参数调优,让你的 vLLM 服务跑得更快、占得更少、延迟更低。
🧠 优化哲学:在性能优化中,你通常需要在三个维度间做权衡:
🚀 高吞吐量(每秒处理更多请求) ↑ | 你可能需要牺牲一个来换取另一个 🎯 低延迟(每个请求响应更快) ←→ 💾 低显存(用更少的 GPU 内存)
6.1 💾 显存优化 — 内存不够?这几招最管用
调整 GPU 内存利用率
# 提高显存利用率(默认 0.9 = 90%,可适当调高到 0.95)
vllm serve Qwen/Qwen2.5-7B-Instruct \
--gpu-memory-utilization 0.95
⚠️ 注意:就像行李箱塞太满会爆开一样,
gpu-memory-utilization设置过高可能导致 OOM(Out of Memory) 错误。建议从 0.9 开始逐步调到 0.95、0.98,每次测试一下稳定性。
调整 KV 缓存参数
vllm serve Qwen/Qwen2.5-7B-Instruct \
--max-num-seqs 128 \ # 最大并发序列数(同时处理多少个请求)
--max-num-batched-tokens 8192 \ # 最大批处理 token 数(批次大小上限)
--block-size 16 # KV 块大小(默认 16 个 token 一块)
💡 这些参数怎么调?
max-num-seqs:显存大 → 调高;显存小 → 调低max-num-batched-tokens:越大吞吐越高,但首 token 延迟也越大block-size:保持默认 16 就好,除非你特别清楚在做什么
使用量化(效果最显著)
参考 5.1 量化支持,一个 AWQ 量化能让 7B 模型的显存需求从 16GB 降到 8GB。
# 显存不够时的"救命三连":
vllm serve Qwen/Qwen2.5-7B-Instruct \
--quantization awq \ # 1. 量化
--gpu-memory-utilization 0.8 \ # 2. 降低显存占用率
--max-model-len 2048 # 3. 缩短上下文长度
6.2 🚀 吞吐量优化 — 同样的 GPU,服务更多人
连续批处理参数调优
vLLM 最核心的优化手段就是连续批处理(Continuous Batching)。可以想象成一个"流水线":
vllm serve Qwen/Qwen2.5-7B-Instruct \
--max-num-seqs 256 \ # 增加并发数(让流水线更满)
--max-num-batched-tokens 16384 \ # 增大批处理大小(一次处理更多 token)
--scheduling-policy fcfs \ # 调度策略(fcfs=先来先服务,priority=优先级)
--enable-chunked-prefill \ # 启用分块预填充(把大请求切成小块,减少等待)
--prefill-chunk-size 2048 # 预填充块大小
💡 分块预填充(Chunked Prefill) 是什么意思?
传统方式:请求 A(很长)来了 → GPU 先全力处理 A → 请求 B(很短)在排队干等
分块预填充:请求 A 切碎 → GPU 处理 A 的一块 → 切换到 B(响应飞快)→ 再切回 A效果:短请求不用等长请求处理完,用户体验更好!
启用 CUDA 图(默认开启)
# vLLM 默认启用 CUDA 图,能显著提升性能
# 只有在调试时才需要禁用它:
vllm serve Qwen/Qwen2.5-7B-Instruct \
--enforce-eager # 禁用 CUDA 图(调试用,生产环境不建议)
🤔 CUDA 图是什么?
想象你每天上班走同一条路:
- 正常方式:每天都要重新导航、看红绿灯(每次重新计算)
- CUDA 图:录一次导航路线,以后每天都用同一个录播(缓存计算图)
省去了每次重新"规划路线"的时间!
6.3 🎯 延迟优化 — 让用户感觉"秒回"
降低首 token 延迟(TTFT — Time To First Token)
TTFT 是用户最直接的体验指标:从发送请求到收到第一个字的时间。
# 延迟优化配置(牺牲部分吞吐量,换取更快的首字响应)
vllm serve Qwen/Qwen2.5-7B-Instruct \
--max-num-seqs 32 \ # 减少并发数(更少请求排队)
--max-num-batched-tokens 4096 \ # 减小批处理大小(每批少处理一些)
--enable-prefix-caching # 启用前缀缓存(相同开头不重算)
💡 吞吐量 vs 延迟的权衡:
- 🚀 高吞吐(
max-num-seqs=256):每秒处理更多请求,但单个用户可能等 2 秒才收到第一个字- ⚡ 低延迟(
max-num-seqs=32):用户秒回(0.3 秒出第一个字),但单位时间处理的总请求数减少- 怎么选? 聊天机器人 → 低延迟优先;批量数据处理 → 高吞吐优先
分块预填充(再次强调)
vllm serve Qwen/Qwen2.5-7B-Instruct \
--enable-chunked-prefill \
--prefill-chunk-size 1024 # 块越小,延迟越低,但吞吐也越低
6.4 📊 性能监控 — 你的 GPU 到底在干什么?
查看服务状态
# 查看可用的模型列表
curl http://localhost:8000/v1/models
# 查看 Prometheus 指标(vLLM 内置了详细的性能指标)
curl http://localhost:8000/metrics
# 常用指标的说明(输出很多,关注这几个):
# - vllm:num_requests_running → 正在处理的请求数
# - vllm:num_requests_waiting → 等待中的请求数(这个持续>0说明超载了)
# - vllm:gpu_cache_usage_perc → GPU 缓存使用率
💡 生产环境建议:把
/metrics接入 Prometheus + Grafana,做成可视化监控面板。
性能基准测试
import time
from vllm import LLM, SamplingParams
def benchmark(model_name, num_prompts=10):
"""
简单的性能测试函数,帮你量化 vLLM 的性能
参数:
model_name: 模型名称
num_prompts: 测试用的请求数量
"""
llm = LLM(model=model_name)
sampling_params = SamplingParams(max_tokens=256, temperature=1.0)
# 生成测试用的 prompts(相同的 prompt,方便对比)
prompts = ["写一篇关于人工智能的文章。" for _ in range(num_prompts)]
# 预热(第一次加载可能包含冷启动开销,不算在正式成绩里)
print("🔥 预热中...")
llm.generate(["预热"], sampling_params)
print("✅ 预热完成,开始正式测试\n")
# 正式测试
start_time = time.time()
outputs = llm.generate(prompts, sampling_params)
end_time = time.time()
# 统计结果
total_tokens = sum(len(output.outputs[0].token_ids) for output in outputs)
elapsed = end_time - start_time
throughput = total_tokens / elapsed
print(f"📊 测试结果")
print(f"━━━━━━━━━━━━━━━━━━━━")
print(f" 模型: {model_name}")
print(f" 请求数: {num_prompts}")
print(f" 总生成 token 数: {total_tokens}")
print(f" 总耗时: {elapsed:.2f}s")
print(f" 吞吐量: {throughput:.2f} tokens/s")
print(f" 平均每请求耗时: {elapsed/num_prompts:.2f}s")
print(f"━━━━━━━━━━━━━━━━━━━━")
# 运行测试
benchmark("Qwen/Qwen2.5-7B-Instruct")
7. 生产部署实践 — 把 vLLM 真正跑在线上
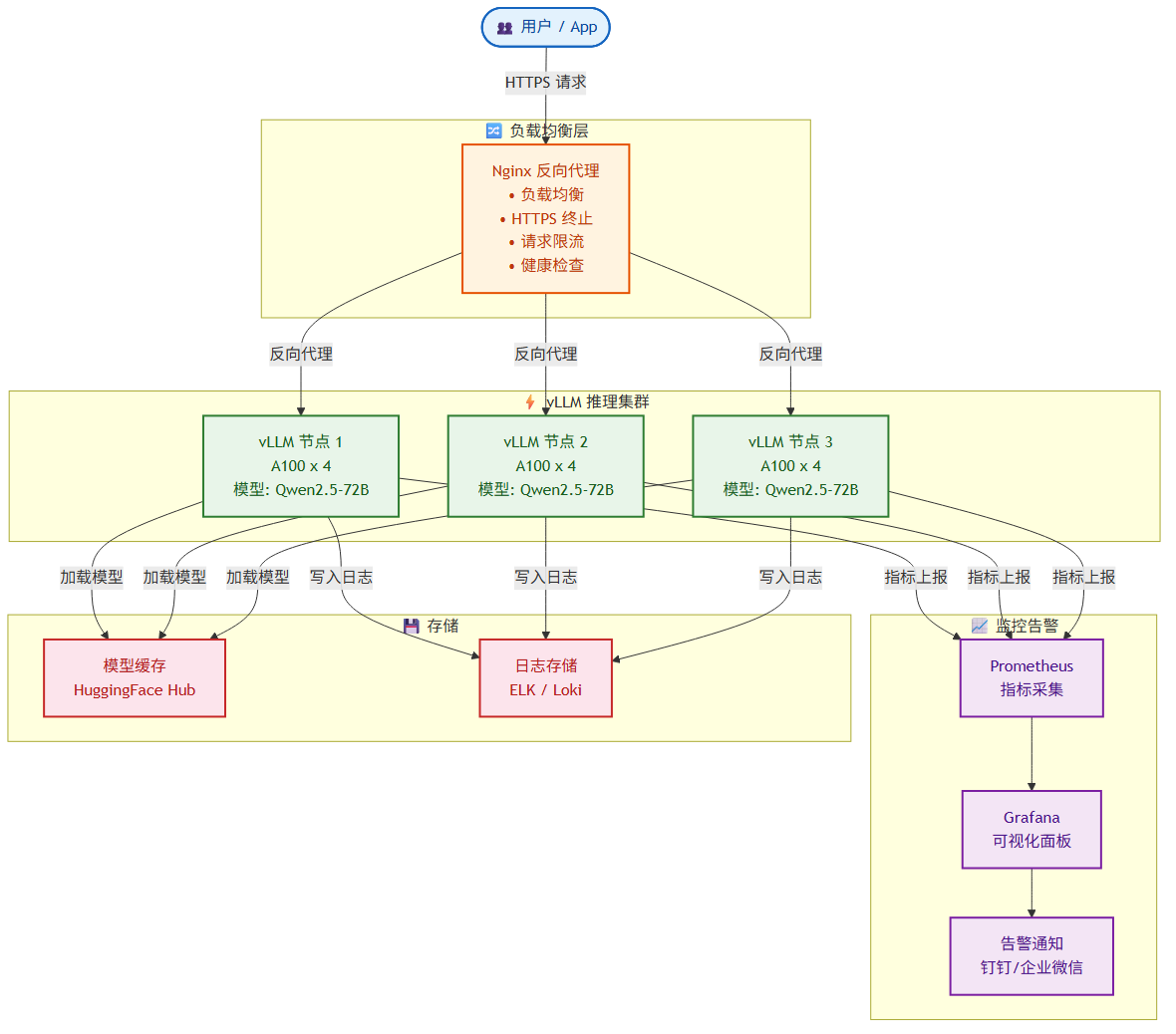
🎯 学习目标:学会将 vLLM 部署到生产环境的完整方案:包括配置调优、容器化、负载均衡、监控告警和安全防护。
⚠️ 前置提醒:生产环境和开发环境是两码事。开发环境追求"能跑就行",生产环境追求"稳如泰山"。
7.1 🏭 生产环境配置建议
单机部署配置(针对不同规模)
配置一:小规模(单卡 24GB,如 RTX 4090)
vllm serve Qwen/Qwen2.5-7B-Instruct \
--gpu-memory-utilization 0.92 \
--max-model-len 4096 \
--max-num-seqs 64 \
--max-num-batched-tokens 8192 \
--api-key your-production-key \
--served-model-name qwen-7b \
--host 0.0.0.0 \
--port 8000 \
--enable-prefix-caching \
--trust-remote-code
配置二:中大规模(4 卡 A100 80GB)
vllm serve Qwen/Qwen2.5-72B-Instruct \
--tensor-parallel-size 4 \ # 4 张 GPU 并行
--max-model-len 8192 \ # 支持长上下文
--gpu-memory-utilization 0.93 \ # 稍高一点的显存利用率
--max-num-seqs 128 \ # 同时处理 128 个请求
--max-num-batched-tokens 16384 \ # 大批次吞吐更高
--api-key your-production-key \
--served-model-name qwen-72b \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-code \
--enable-prefix-caching # 如果 System Prompt 都一样,省很多算力
💡 生产环境参数调优口诀:
显存不够 → 量化 + 降 max-model-len 吞吐不够 → 升 max-num-seqs + max-num-batched-tokens 延迟太高 → 降 max-num-seqs + 开 chunked-prefill 怕出问题 → 降 gpu-memory-utilization 留余量
使用 Docker Compose(推荐的生产部署方式)
Docker Compose 让整个服务变成"一键启动",环境完全可复现。
# docker-compose.yml
version: '3.8'
services:
vllm:
# 使用官方镜像,省去环境配置的麻烦
image: vllm/vllm-openai:latest
runtime: nvidia # 启用 NVIDIA GPU 支持
ports:
- "8000:8000" # 映射端口
environment:
- NVIDIA_VISIBLE_DEVICES=all # 让容器看到所有 GPU
volumes:
# 挂载模型缓存目录,避免每次重启都要重新下载模型
- ./models:/root/.cache/huggingface/hub
command: >
--model Qwen/Qwen2.5-7B-Instruct
--host 0.0.0.0
--port 8000
--api-key your-api-key
--served-model-name qwen-7b
--max-model-len 8192
--gpu-memory-utilization 0.9
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all # 分配所有 GPU
capabilities: [gpu]
# 自动重启策略:除非手动停止,否则挂了自动重启
restart: unless-stopped
# 日志大小限制,防止日志撑爆磁盘
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "3"
启动服务:
# 启动(-d 表示后台运行)
docker-compose up -d
# 查看日志
docker-compose logs -f
# 停止服务
docker-compose down
7.2 🔄 高可用部署 — 一个挂了,另一个顶上
当流量大到单机扛不住时,就需要水平扩展——多台机器(或集群)一起提供服务。
架构示意
┌──────────────┐
│ Nginx │ ← 负载均衡器(流量入口)
│ (反向代理) │
└──────┬───────┘
│
┌──────────────┼──────────────┐
│ │ │
┌───────▼───────┐ ┌───▼────────┐ ┌───▼────────┐
│ vLLM 节点 1 │ │ vLLM 节点 2 │ │ vLLM 节点 3 │
│ (A100 x 4) │ │ (A100 x 4) │ │ (A100 x 4) │
└───────────────┘ └────────────┘ └────────────┘
Nginx 负载均衡配置
# nginx.conf
http {
# 定义一组后端 vLLM 服务节点
upstream vllm_backends {
# 支持加权轮询:server vllm-1:8000 weight=3;
server vllm-1:8000;
server vllm-2:8000;
server vllm-3:8000;
}
server {
listen 80;
location /v1/ {
proxy_pass http://vllm_backends;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
# 流式响应需要:禁用缓冲,否则 SSE 会卡住
proxy_buffering off;
proxy_cache off;
# 超时设置(大模型推理可能超过 60 秒)
proxy_read_timeout 300s; # 5 分钟超时
proxy_connect_timeout 30s;
}
# 健康检查端点
location /health {
proxy_pass http://vllm_backends/health;
access_log off;
}
}
}
⚠️ 关键注意点:Nginx 的
proxy_buffering off是必须的!如果开启缓冲,流式输出的 SSE(Server-Sent Events)数据会被 Nginx 攒够一整块才返回,用户的"打字机效果"就变成了"等半天刷一下全出来"。
7.3 📈 监控与告警 — 出了事第一时间知道
生产环境最怕的是:出问题了没人知道。一套好的监控体系能让你"先于用户发现问题"。
集成 Prometheus + Grafana
# 启动 vLLM 服务并暴露指标端口(默认 8000 上就有 /metrics)
vllm serve Qwen/Qwen2.5-7B-Instruct \
--port 8000
# 指标端点:http://localhost:8000/metrics
Prometheus 配置(采集 vLLM 指标):
# prometheus.yml
scrape_configs:
- job_name: 'vllm'
scrape_interval: 15s # 每 15 秒采集一次
static_configs:
- targets: ['localhost:8000'] # vLLM 服务地址
关键监控指标解读
| 指标 | 含义 | 告警建议 | 如果告警了… |
|---|---|---|---|
vllm:num_requests_running |
正在处理的请求数 | > 最大并发的 85% | 扩容节点或限制并发 |
vllm:num_requests_waiting |
排队的请求数 | 持续 > 0 超过 10 秒 | 说明处理能力不足,需要扩容 |
vllm:gpu_cache_usage_perc |
GPU 缓存使用率 | > 90% | 接近 OOM,考虑降负载 |
vllm:e2e_request_latency_seconds |
端到端延迟(P99) | P99 > 5秒 | 检查模型或网络瓶颈 |
vllm:prompt_tokens_total |
输入 token 总数 | 突增 | 可能有异常流量 |
vllm:generation_tokens_total |
生成 token 总数 | 突降 | 服务可能出问题了 |
💡 Grafana 仪表盘:可以用 这个社区模板 快速搭建可视化面板,一目了然。
7.4 🛡️ 安全配置 — 别让你的模型裸奔
API Key 认证(最基本的安全措施)
# 设置 API Key,所有请求必须携带此 Key
vllm serve Qwen/Qwen2.5-7B-Instruct \
--api-key your-secure-api-key-here
# 调用时需要带 Authorization 头
curl http://localhost:8000/v1/chat/completions \
-H "Authorization: Bearer your-secure-api-key-here" \
-d '{"model":"qwen-7b", "messages":[{"role":"user","content":"Hello"}]}'
网络安全
# 场景一:仅允许内网访问(最安全)
vllm serve Qwen/Qwen2.5-7B-Instruct \
--host 127.0.0.1 \ # 只监听本地回环地址
--port 8000
# 然后通过 Nginx 反代对外暴露,由 Nginx 负责 HTTPS 和认证
# 场景二:配合反向代理实现 HTTPS
# 在 Nginx 层配置 SSL 证书,vLLM 本身不需要处理加密
请求限流(防止接口被刷)
在 Nginx 反向代理层配置:
# 定义限流区域:每个 IP 限速 10 请求/秒
limit_req_zone $binary_remote_addr zone=vllm:10m rate=10r/s;
server {
location /v1/ {
# burst=20:允许瞬间突增 20 个请求
# nodelay:不延迟,超过限制直接返回 503
limit_req zone=vllm burst=20 nodelay;
proxy_pass http://vllm_backends;
}
}
💡 安全最佳实践清单 ✅
- [ ] 设置
--api-key(基本中的基本)- [ ] 不把 vLLM 直接暴露在公网(用 Nginx 反代)
- [ ] 配置 HTTPS(用 Let’s Encrypt 免费证书)
- [ ] 设置请求限流(防 DDoS/刷接口)
- [ ] 监控异常流量(突然的大量请求可能是攻击)
- [ ] 定期更新 vLLM 版本(修复已知漏洞)
8. 🐛 常见问题与排错 — 遇到问题别慌
下面整理了最常遇到的 10 个问题,按类型分类,遇到时快速查找即可。
8.1 安装问题
问题 1:CUDA 版本不兼容
报错:
Unsupported platform, please use CUDA, ROCm, or CPU.
原因:你的 CUDA 版本低于 vLLM 的要求(12.1)。
解决步骤:
# ① 先检查当前 CUDA 版本
nvidia-smi # 查看 CUDA Version(驱动支持的最高版本)
nvcc --version # 查看当前使用的 CUDA 版本
# ② 如果 CUDA < 12.1,有两种选择:
# 方案 A:升级 CUDA(推荐)
# 去 NVIDIA 官网下载 CUDA 12.1+
# 方案 B:用 Docker(更省事,不用折腾环境)
docker pull vllm/vllm-openai:latest
💡 最容易忽视的点:
nvidia-smi和nvcc --version显示的版本可能不同!前者是驱动支持的最高版本,后者是实际使用的版本。要以nvcc为准。
问题 2:源码编译失败
报错:
fatal error: cblas.h: No such file or directory
原因:缺少系统级依赖库。
解决:
# Ubuntu/Debian 系统
sudo apt update
sudo apt install libopenblas-dev
# CentOS/RHEL 系统
sudo dnf install openblas-devel
💡 再次建议:除非有特殊需求,否则用
pip install vllm是最省心的方式,不用和系统依赖打交道。
8.2 💥 显存不足(OOM)
问题 3:启动时报 CUDA out of memory
报错:
CUDA out of memory. Tried to allocate 512.00 MiB
根本原因:模型太大,显存太小。
四种解决方案(从最有效到最温和):
① 缩短上下文长度(最有效)
# 默认 max-model-len 通常为 8192 或 32768
# 降低到 2048 可以省 50~70% 的 KV 缓存显存
vllm serve Qwen/Qwen2.5-7B-Instruct \
--max-model-len 2048
② 使用量化模型
# 换成 AWQ 量化版本,显存直接减半
vllm serve TheBloke/Qwen2.5-7B-Instruct-AWQ \
--quantization awq
③ 降低 GPU 内存利用率
# 默认 0.9(用 90% 显存),降到 0.7 留更多余量
vllm serve Qwen/Qwen2.5-7B-Instruct \
--gpu-memory-utilization 0.7
④ 减少并发数
# 默认 max-num-seqs=256,降到 32 减少 KV 缓存占用
vllm serve Qwen/Qwen2.5-7B-Instruct \
--max-num-seqs 32
💡 显存计算公式(粗略):
7B 模型(FP16)≈ 14 GB 显存(模型权重) + 每个 token 的 KV 缓存 ≈ 2 MB + 余量 ≈ 2 GB所以 7B 模型 + 4096 上下文 ≈ 14 + 4096×2MB + 2 ≈ 24 GB → 需要 24GB+ 的显卡
8.3 ⚡ 性能问题
问题 4:吞吐量远低于预期
症状:每秒生成的 token 数很少,GPU 利用率不高。
排查步骤:
① 先看 GPU 利用率:
nvidia-smi
# 关键看:GPU-Util(利用率)和 Memory(显存使用)
# 如果 GPU-Util < 80%,说明 GPU 没吃饱
② 调整批处理参数(让 GPU 吃得更饱):
vllm serve Qwen/Qwen2.5-7B-Instruct \
--max-num-seqs 256 \ # 增加并发数
--max-num-batched-tokens 16384 # 增大批次大小
③ 启用前缀缓存(如果 System Prompt 相同):
vllm serve Qwen/Qwen2.5-7B-Instruct \
--enable-prefix-caching
问题 5:首 token 延迟(TTFT)过高
症状:用户发完消息,等 3~5 秒才看到第一个字回复。
原因:并发太高或输入太长,"排队"等太久了。
解决方案:
# 减少并发 + 启用分块预填充
vllm serve Qwen/Qwen2.5-7B-Instruct \
--max-num-seqs 16 \ # 减少排队人数
--enable-chunked-prefill \ # 允许小请求插队
--prefill-chunk-size 1024 # 切得更碎,插队更灵活
💡 TTFT 优化思路:
- 核心矛盾:短请求不想等长请求处理完
- 分块预填充(Chunked Prefill)= 把长任务切碎,让短请求见缝插针
8.4 🔧 服务问题
问题 6:端口被占用
报错:
Address already in use
解决:
# ① 找到谁占用了端口
lsof -i :8000
# 或
netstat -tulpn | grep :8000
# ② 选择:杀掉进程 或 换端口
kill -9 <PID> # 杀掉占用进程
vllm serve Qwen/Qwen2.5-7B-Instruct --port 8001 # 或换个端口
问题 7:服务启动后立即退出
症状:vllm serve 启动后几秒钟就自动退出,没有明显报错。
排查步骤:
① 开启详细日志,看具体错误:
export VLLM_LOGGING_LEVEL=DEBUG
vllm serve Qwen/Qwen2.5-7B-Instruct
# 日志会详细到每个步骤的加载过程
② 检查模型文件是否完整:
# 有时候下载中断导致模型文件损坏
# 删除缓存,重新下载
rm -rf ~/.cache/huggingface/hub/models--Qwen--Qwen2.5-7B-Instruct
# 重新启动(会自动下载)
vllm serve Qwen/Qwen2.5-7B-Instruct
8.5 🧪 调试技巧
启用详细日志
# ① 最常用:查看 vLLM 的详细运行日志
export VLLM_LOGGING_LEVEL=DEBUG
# ② CUDA 内核调试(如果怀疑 GPU 计算有问题)
# 让 CUDA 操作变成同步的(方便定位出错点,但速度慢很多)
export CUDA_LAUNCH_BLOCKING=1
# ③ 函数调用追踪(会大幅降低性能,仅调试用)
export VLLM_TRACE_FUNCTION=1
检查多卡通信(NCCL)
如果使用多卡(tensor-parallel-size > 1)时遇到问题:
export NCCL_DEBUG=TRACE # 打印 NCCL 通信日志
export NCCL_DEBUG_SUBSYS=ALL # 打印所有子系统的调试信息
# 然后重新运行 vllm serve,观察 NCCL 相关的输出
💡 NCCL 常见问题:
- 多卡通信超时 → 检查 GPU 之间的 NVLink 连接
- 找不到网卡 → 设置
export NCCL_SOCKET_IFNAME=eth0- 进程挂了 → 检查
ulimit -n(文件描述符限制)
9. 🚀 进阶话题 — 走向高手之路
🎯 学习目标:了解 vLLM 的高级用法和生态全景,成为一名"不止会用,还懂原理"的 vLLM 开发者。
9.1 🧩 自定义模型支持
如果你的模型不在官方支持列表中(这种情况比较少,因为 vLLM 支持 90%+ 的主流模型),有两种方式加载:
方式一:使用 trust_remote_code(最简单)
大多数模型在 HuggingFace 上发布时会自带模型代码。trust_remote_code=True 告诉 vLLM:“用模型自带的代码来加载我”。
llm = LLM(
model="your-custom-model", # HuggingFace 上的模型名
trust_remote_code=True, # 信任并使用模型自带的加载代码
)
⚠️ 安全提示:
trust_remote_code=True意味着执行模型发布者的代码。只在你信任的模型来源(如知名机构发布的模型)使用此选项。
方式二:注册自定义模型(开发者用)
如果你有自己的模型架构,想深度集成到 vLLM 中:
from vllm import ModelRegistry
from vllm.model_executor.models import YourCustomModel
# 把你的模型注册到 vLLM 的模型注册表中
ModelRegistry.register_model("YourCustomModel", YourCustomModel)
# 然后就可以像使用内建模型一样使用了
llm = LLM(model="your-model-path")
9.2 🔌 插件生态
vLLM 有一个活跃的插件生态,可以扩展各种能力:
| 插件 | 作用 | 适合谁 |
|---|---|---|
| vllm-flash-attn | 用 FlashAttention 加速注意力计算 | 追求极致推理速度 |
| vllm-gguf | 支持 GGUF 格式模型(llama.cpp 生态) | 想把 gguf 模型跑在 vLLM 上 |
| vllm-tensorrt-llm | 使用 NVIDIA TensorRT-LLM 后端 | 深度使用 NVIDIA 生态的用户 |
# 安装示例
pip install vllm-flash-attn
9.3 📊 与其他推理框架对比
一句话总结各家特点:
vLLM → 吞吐量之王,生产首选(⭐ 本教程的主角)
SGLang → vLLM 的最强对手,结构化生成更强
Ollama → 个人使用最方便,下载即用
TGI → HuggingFace 亲儿子,生态集成好
| 特性 | vLLM | HuggingFace TGI | Ollama | SGLang |
|---|---|---|---|---|
| 吞吐量 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 易用性 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 功能丰富度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 生产就绪 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ |
| 社区活跃度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
选择建议:
| 你的需求 | 推荐框架 |
|---|---|
| 🏢 生产环境,高并发,高性能 | vLLM 或 SGLang |
| 🧪 本地测试,快速上手 | Ollama(一行命令就搞定) |
| 🤗 深度使用 HuggingFace 生态 | TGI |
| 🔧 需要结构化生成(JSON 约束) | SGLang(Guidance 支持更好) |
9.4 🔮 最新发展趋势
vLLM 社区非常活跃,以下是值得关注的方向:
1️⃣ 推测解码(Speculative Decoding)
🧠 原理:用一个小模型(“实习生”)快速生成草稿,大模型(“专家”)快速验证修改。
效果:生成速度提升 2~3 倍,质量几乎不变。
2️⃣ 多模态统一推理
从纯文本 → 图文理解 → 视频理解 → 音频理解,一个引擎搞定所有模态。
3️⃣ 更强的量化技术
INT4 → INT2 → 混合精度量化,在"模型大小"和"精度"之间找到更好的平衡点。
4️⃣ 服务网格集成
更好的 Kubernetes 原生支持,自动扩缩容、滚动更新、灰度发布。
5️⃣ 万亿参数级模型
支持 MoE(混合专家)架构的分布式推理,如 Mixtral 8×22B、DeepSeek-V2 等。
📎 附录
A. 🏃 常用命令速查(快速复制版)
# 基础命令
vllm serve <model-name> # 启动服务
vllm serve <model-name> --host 0.0.0.0 --port 8000 # 指定端口
# 性能相关
vllm serve <model-name> --tensor-parallel-size 2 # 多卡推理
vllm serve <model-name> --quantization awq # 量化
vllm serve <model-name> --enable-prefix-caching # 前缀缓存
vllm serve <model-name> --enable-chunked-prefill # 分块预填充
# 高级功能
vllm serve <model-name> --enable-lora # 启用 LoRA
vllm serve <model-name> --trust-remote-code # 自定义模型
# 生产配置
vllm serve <model-name> --api-key your-key # 设置 API Key
vllm serve <model-name> --gpu-memory-utilization 0.9 # 显存控制
vllm serve <model-name> --max-model-len 4096 # 上下文长度
B. 📋 重要参数速查表
| 参数 | 默认值 | 一句话说明 | 调优建议 |
|---|---|---|---|
--model |
必填 | 模型名称或 HuggingFace 路径 | 选对模型版本 |
--max-model-len |
模型默认值 | 最大上下文长度(token 数) | 显存不够就调低 |
--tensor-parallel-size |
1 | 用几张 GPU 并行推理 | 有多少张就设多大 |
--gpu-memory-utilization |
0.9 | 最多用多少比例的显存 | 稳定优先就设 0.8 |
--max-num-seqs |
256 | 最多同时处理几个请求 | 吞吐优先就调高 |
--max-num-batched-tokens |
8192 | 一次最多处理多少 token | 显存够就调高 |
--quantization |
None | 量化方式 (awq/gptq/fp8) | 显存不够就量化 |
--enable-lora |
False | 是否支持 LoRA 适配器 | 多任务切换时开启 |
--enable-prefix-caching |
False | 是否缓存相同前缀 | 相同 System Prompt 时开启 |
--api-key |
None | API 认证密钥 | 生产环境必须设置 |
--served-model-name |
模型名 | 对外显示的模型名称 | 随便取个好记的名字 |
C. 📚 学习资源
| 资源 | 链接 | 适合 |
|---|---|---|
| 📖 官方文档 | https://docs.vllm.ai/ | 所有人(最权威) |
| 💻 GitHub 仓库 | https://github.com/vllm-project/vllm | 开发者(看源码、提 Issue) |
| 📄 论文 | “Efficient Memory Management for Large Language Model Serving with PagedAttention” | 原理研究者 |
| 🌐 中文社区 | https://vllm.hyper.ai/ | 中文用户(文档/教程) |
🎓 学习路线图
如果你学完了这本教程,这里建议下一步:
本教程 ✅ → 你已经能:
1. 理解 PagedAttention 原理
2. 安装和使用 vLLM
3. 做离线推理和 API 服务
4. 优化性能、部署生产环境
5. 遇到问题能自己排查
下一步 🎯 → 可以尝试:
1. 阅读 vLLM 官方文档深入某个特性
2. 尝试用 vLLM 部署不同的模型
3. 搭建完整的推理服务平台(含监控)
4. 参与 vLLM 开源社区贡献
教程信息
| 字段 | 内容 |
|---|---|
| 📌 教程版本 | v2.0(详细讲解版) |
| 🕐 更新时间 | 2026 年 6 月 |
| 🎯 适用版本 | vLLM 0.7.x+ |
| ✍️ 说明 | 本教程由 Claudian 精心打磨,力求通俗易懂 |
评论区