




本文覆盖 Redis 架构线程模型、五大数据结构源码级实现、持久化机制、内存管理与淘汰策略、高可用架构(主从/哨兵/集群)、缓存三大问题、分布式锁、高并发场景实战,以及 20 道分层面试题。适用于后端开发、架构师面试准备。
一、Redis 整体架构与线程模型
1.1 Redis 为什么快
Redis 单机可达 10万+ QPS,核心原因有三层:
第一,纯内存操作。数据全部存在内存中,读写都是纳秒级,没有磁盘 IO 瓶颈(持久化除外)。
第二,单线程Reactor模型。避免了多线程的上下文切换开销、锁竞争开销。Redis 的性能瓶颈不在 CPU,而在内存大小和网络 IO。
第三,高效的数据结构。SDS、跳表、压缩列表等底层结构经过精心设计,操作复杂度低。
第四,IO 多路复用。基于 epoll(Linux)/ kqueue(Mac)/ select(Windows),单线程处理海量连接。
第五,Redis 6.0 多线程 IO。网络读写多线程化,命令执行仍单线程,兼顾线程安全与网络性能。
1.2 单线程 Reactor 模型详解
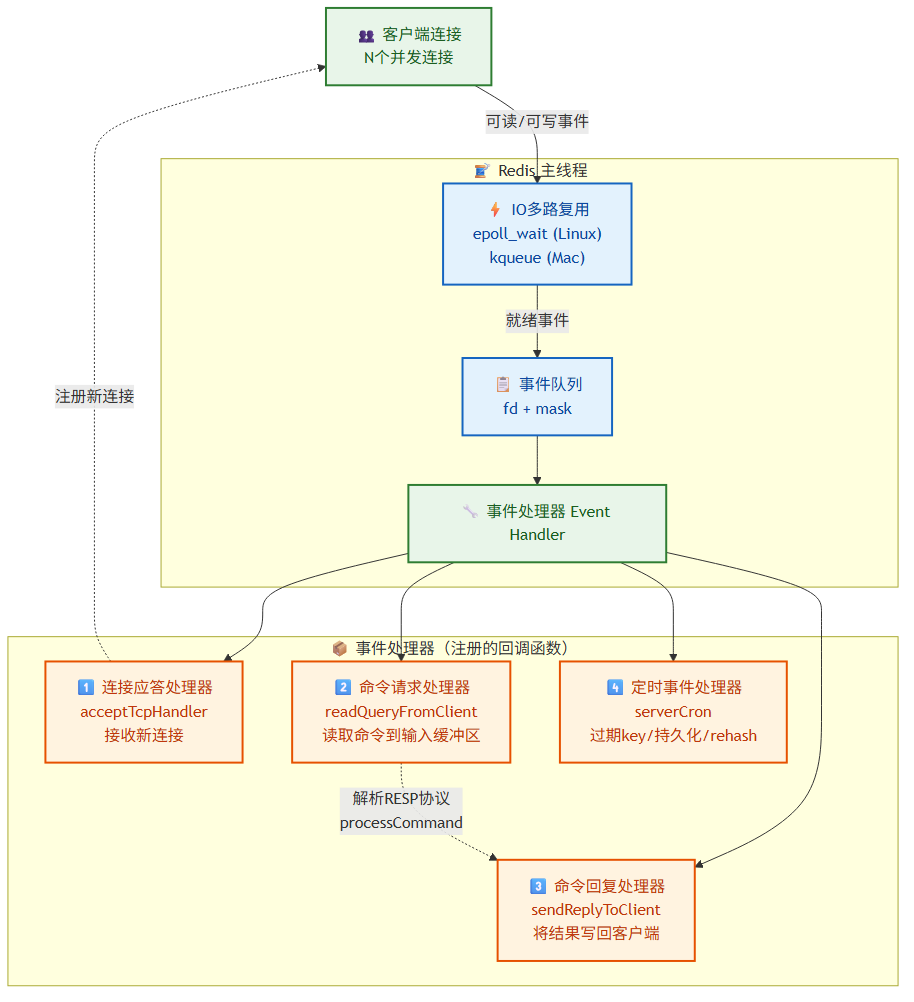
Redis 的事件循环(Event Loop)核心结构:
┌─────────────────────────────────────────┐
│ Redis 主线程 │
│ │
│ ┌───────────┐ ┌───────────────────┐ │
│ │ IO 多路 │ │ 事件处理器 │ │
│ │ 复用程序 │──→│ (Event Handler) │ │
│ │ (epoll) │ │ │ │
│ └───────────┘ │ ┌───────────────┐ │ │
│ │ │ 连接应答处理器 │ │ │
│ ┌───────────┐ │ │ (acceptTcp) │ │ │
│ │ 事件队列 │ │ ├───────────────┤ │ │
│ │ (fd+mask) │ │ │ 命令请求处理器 │ │ │
│ └───────────┘ │ │ (readQuery) │ │ │
│ │ ├───────────────┤ │ │
│ │ │ 命令回复处理器 │ │ │
│ │ │ (sendReply) │ │ │
│ │ ├───────────────┤ │ │
│ │ │ 定时事件处理器 │ │ │
│ │ │ (TimeEvent) │ │ │
│ │ └───────────────┘ │ │
│ └───────────────────┘ │
└─────────────────────────────────────────┘
源码关键文件与函数链:
// src/server.c —— Redis 服务器启动入口
int main() {
initServer(); // 创建事件循环、注册事件处理器
while(server.shutdown == 0) {
// aeProcessEvents 是事件循环核心
aeProcessEvents();
}
}
// src/ae.c —— 事件循环核心
int aeProcessEvents(aeEventLoop *eventLoop, int flags) {
// 1. 计算最近定时任务的等待时间
shortest = aeSearchNearestTimer();
// 2. 调用 epoll_wait 等待事件,阻塞最短 shortest 时间
numevents = aeApiPoll(eventLoop, tvp);
// 3. 处理所有就绪的 IO 事件
for (j = 0; j < numevents; j++) {
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
if (fe->mask & AE_READABLE) fe->rfileProc(...); // 读事件 → 命令请求处理器
if (fe->mask & AE_WRITABLE) fe->wfileProc(...); // 写事件 → 命令回复处理器
}
// 4. 处理定时事件(serverCron 等)
processed += processTimeEvents();
}
命令执行完整流程:
客户端发送命令
↓
epoll 返回可读事件
↓
readQueryFromClient() —— 读取客户端命令到输入缓冲区
↓
processInputBuffer() —— 解析协议(RESP)
↓
processCommand() —— 查命令表,校验,执行
↓
addReply() —— 将结果写入输出缓冲区
↓
epoll 返回可写事件
↓
writeToClient() —— 将缓冲区数据发送给客户端
1.3 Redis 6.0 多线程 IO 模型
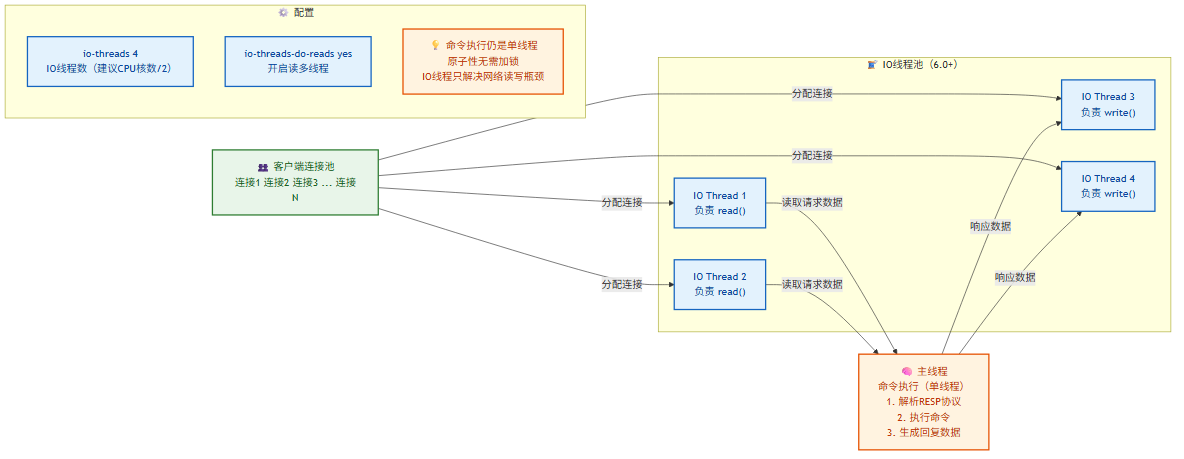
Redis 6.0 引入多线程 IO,但命令执行仍然是单线程。
┌──────────┐ ┌──────────────────────────────┐
│ 客户端 │ │ Redis 进程 │
│ 连接1 │────→│ │
│ 连接2 │────→│ ┌─────────┐ ┌───────────┐ │
│ 连接3 │────→│ │ IO 线程池 │→│ 主线程 │ │
│ ... │ │ │ (读取/写入)│ │ (命令执行) │ │
│ 连接N │────→│ └─────────┘ └───────────┘ │
└──────────┘ │ │
│ 主线程: 解析→执行→返回 │
│ IO线程: read()和write() │
└──────────────────────────────┘
配置方式:
# redis.conf
io-threads 4 # IO 线程数(建议 CPU 核数的一半,不超过 8)
io-threads-do-reads yes # 开启读操作多线程(默认仅写多线程)
为什么命令执行不使用多线程?因为 Redis 所有操作都是原子的,单线程无需加锁。如果命令执行多线程化,所有数据结构都要加锁,反而降低性能。多线程 IO 只解决了网络读写瓶颈,CPU 不是 Redis 的瓶颈。
1.4 Redis vs Memcached 对比
| 特性 | Redis | Memcached |
|---|---|---|
| 数据结构 | String/List/Hash/Set/ZSet/Stream等 | 仅 KV(String) |
| 持久化 | RDB + AOF | ❌ 纯内存 |
| 高可用 | 主从/哨兵/集群 | 需客户端分片 |
| 线程模型 | 单线程命令执行(6.0 IO多线程) | 多线程 |
| 单 Value 上限 | 512MB | 1MB |
| 过期策略 | 惰性 + 定期 | 惰性 |
| 适用场景 | 缓存/分布式锁/消息队列/排行榜 | 纯 KV 缓存 |
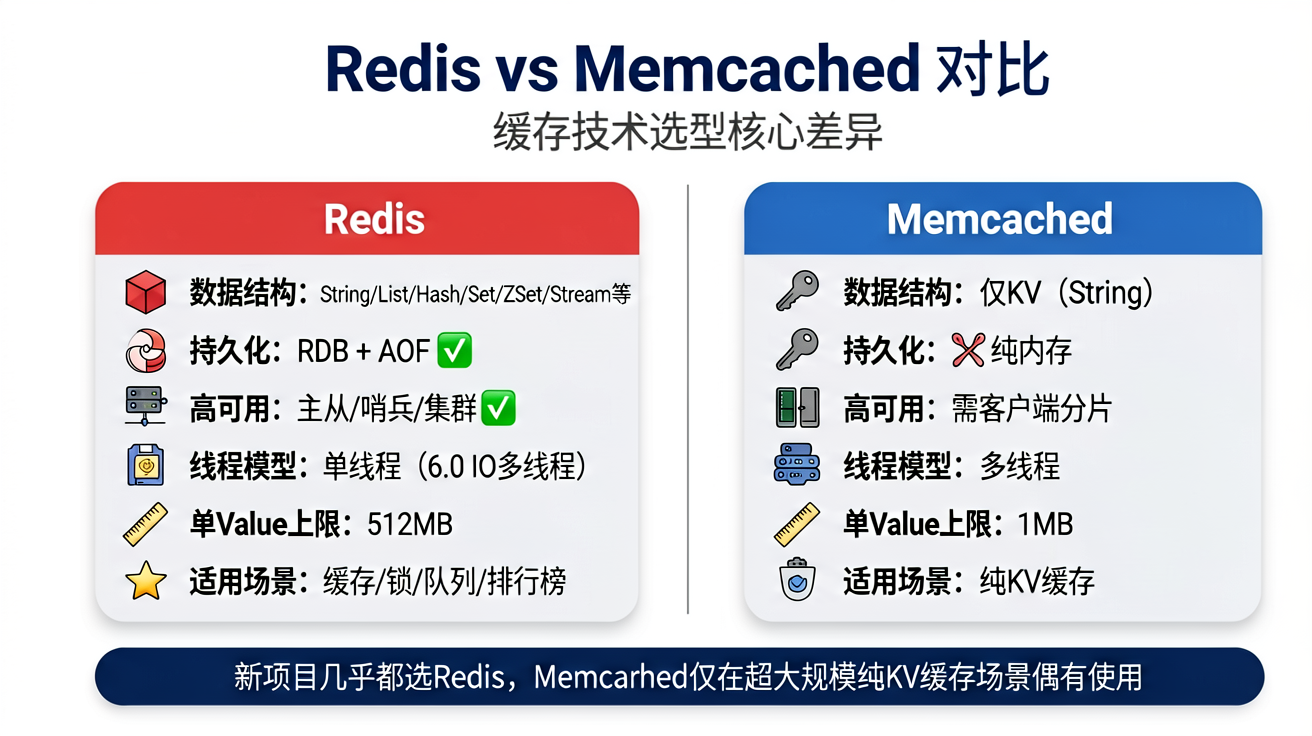
大厂结论:新项目几乎都选 Redis,Memcached 仅在超大规模纯 KV 缓存场景偶有使用(多线程模型在极端高并发下网络 IO 吞吐更高)。
二、数据结构与底层实现源码级解析
2.1 Redis 对象系统
Redis 每个键值对中的值都是一个 redisObject:
// src/server.h
typedef struct redisObject {
unsigned type:4; // 类型: OBJ_STRING/OBJ_LIST/OBJ_HASH/OBJ_SET/OBJ_ZSET
unsigned encoding:4; // 编码: 底层实现方式
unsigned lru:LRU_BITS; // LRU/LFU 信息(24位)
int refcount; // 引用计数
void *ptr; // 指向底层数据结构的指针
} robj;
核心设计思想:类型与编码分离。同一种类型(如 List)在不同数据量下使用不同编码(如 listpack 或 quicklist),兼顾内存和性能。
# 查看键的底层编码
OBJECT ENCODING mykey
2.2 String —— SDS(Simple Dynamic String)

Redis 没有使用 C 语言的字符串,而是自己实现了 SDS。
// src/sds.h (Redis 7.x 简化)
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; // 已使用长度
uint8_t alloc; // 分配总长度(不含头和\0)
unsigned char flags; // 头类型标记
char buf[]; // 实际数据
};
SDS 相比 C 字符串的五大优势:
① O(1) 获取长度。C 字符串要遍历到 \0 才知道长度,SDS 直接读 len 字段。
② 杜绝缓冲区溢出。C 的 strcat 如果目标空间不够会溢出。SDS 修改前会检查空间,自动扩容。
③ 减少内存重分配次数。
- 空间预分配:修改后 len < 1MB 时分配
2 × len空间;len >= 1MB 时多分配 1MB。 - 惰性释放:缩短时不立即释放空间,留着备用。
④ 二进制安全。C 字符串以 \0 判断结束,不能存二进制数据。SDS 以 len 判断结束,可以存图片、序列化数据等。
⑤ 兼容部分 C 字符串函数。SDS 末尾也追加了 \0,可以直接使用 printf 等。
SDS 有 5 种头类型(sdshdr5/8/16/32/64),根据字符串长度选择最小的头类型,节省内存。这是 Redis 内存优化的典型设计。
String 的三种编码:
| 编码 | 条件 | 说明 |
|---|---|---|
int |
值为整数且 <= LONG_MAX | 直接存在 ptr 中,不分配额外内存 |
embstr |
字符串且 <= 44 字节 | redisObject 和 SDS 内存连续分配,一次 malloc |
raw |
字符串且 > 44 字节 | redisObject 和 SDS 分开分配,两次 malloc |
为什么是 44 字节?redisObject(16字节)+ sdshdr8(3字节)+ 内容 + \0(1字节)= 64字节。jemalloc 内存分配器以 64 字节为一个单元,44 + 16 + 3 + 1 = 64 正好一个单元,不浪费。
127.0.0.1:6379> SET num 12345
OK
127.0.0.1:6379> OBJECT ENCODING num
"int"
127.0.0.1:6379> SET str "hello"
OK
127.0.0.1:6379> OBJECT ENCODING str
"embstr"
127.0.0.1:6379> SET bigstr [50个字符]
OK
127.0.0.1:6379> OBJECT ENCODING bigstr
"raw"
2.3 List —— quicklist
Redis 早期的 List 编码经历了 ziplist → linkedlist → quicklist(ziplist + linkedlist 混合)→ listpack(Redis 7.0)的演进。
当前(Redis 7.x)List 的编码为 listpack(小数据量)和 quicklist(大数据量)。
quicklist 结构:
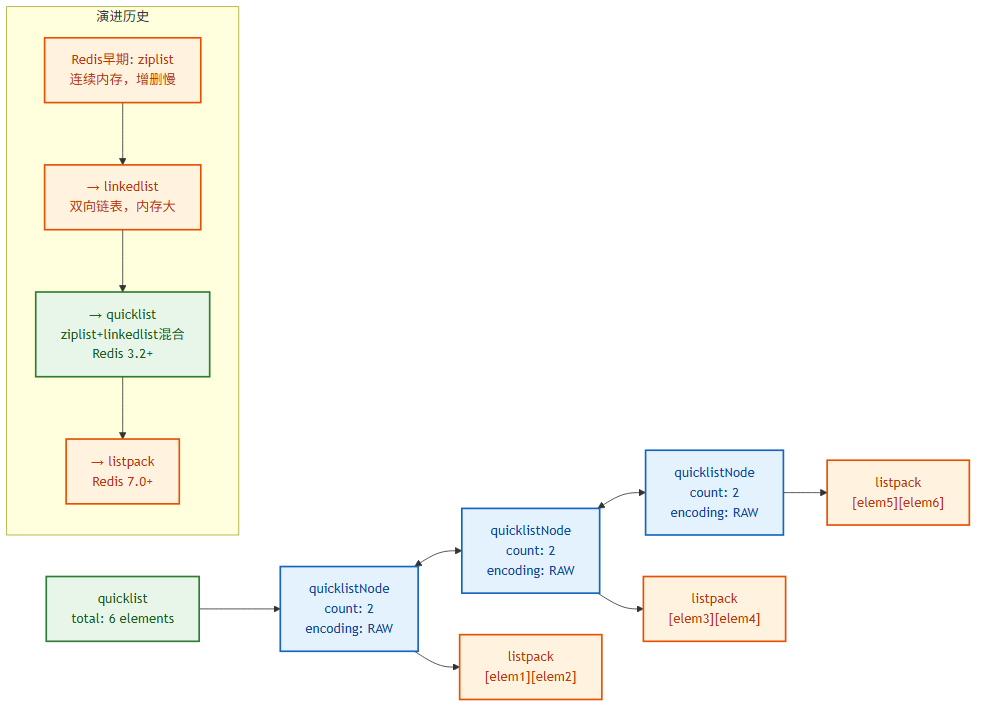
quicklist
├── head → quicklistNode
│ ├── *prev
│ ├── *next
│ ├── *entry (指向 listpack)
│ │ └── listpack: [element1][element2]...
│ ├── count (节点内元素数)
│ └── encoding (RAW/LZ4 压缩)
├── tail → quicklistNode
└── count (总元素数)
quicklist 是一个双向链表,每个节点是一个 listpack(压缩列表)。这样既保留了链表的快速增删特性,又利用 listpack 的紧凑存储节省内存。
# 配置每个 quicklist 节点的 listpack 大小
# -1: 每个 listpack 最大 4KB
# -2: 每个 listpack 最大 8KB (默认)
# -3: 每个 listpack 最大 16KB
# -4: 每个 listpack 最大 32KB
# -5: 每个 listpack 最大 64KB
list-max-listpack-size -2
# 中间节点是否压缩 (none/all/all/小数量保留两端)
list-compress-depth 0 # 默认不压缩,1表示首尾各保留1个不压缩
2.4 Hash —— listpack + hashtable
Hash 类型有两种编码:
listpack(Redis 7.0 前为 ziplist):当元素数量少且值短时使用。将 field-value 对紧凑存储在连续内存中。
# 转换阈值
hash-max-listpack-entries 128 # 元素数 <= 128 用 listpack
hash-max-listpack-value 64 # 单个值 <= 64 字节
hashtable:超过阈值或单个值过长时,转换为 hashtable(字典)。
// src/dict.h
typedef struct dict {
dictEntry **table; // 哈希表数组
unsigned long size; // 表大小(总是 2^n)
unsigned long sizemask; // size - 1,用于快速取模
unsigned long used; // 已用条目数
// ...
} dict;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // 链地址法解决冲突
} dictEntry;
渐进式 rehash:
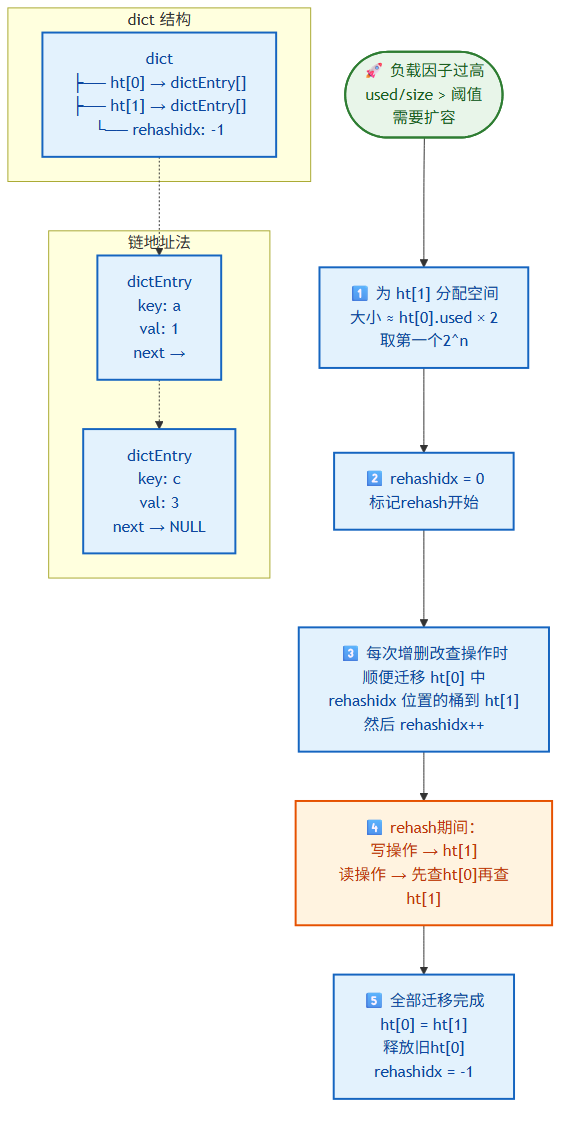
当 hashtable 的负载因子(used/size)过高时,需要扩容。Redis 使用渐进式 rehash 避免一次性 rehash 导致阻塞。
typedef struct dict {
dict ht[2]; // 两个哈希表
int rehashidx; // -1 表示没有 rehash
} dict;
流程:
- 为
ht[1]分配空间(约ht[0].used × 2的第一个 2^n)。 rehashidx设为 0,标记 rehash 开始。- 每次增删改查操作时,顺便将
ht[0]中rehashidx位置的桶迁移到ht[1],然后rehashidx++。 - rehash 期间,写操作在
ht[1],读操作先查ht[0]再查ht[1]。 - 全部迁移完成后,
ht[0] = ht[1],释放旧ht[0],rehashidx = -1。
2.5 Set —— intset + hashtable
intset:当所有元素都是整数且数量 <= 512 时使用。
// src/intset.h
typedef struct intset {
uint32_t encoding; // INTSET_ENC_INT16/32/64
uint32_t length;
int8_t contents[]; // 有序整数数组
} intset;
intset 是一个有序数组,支持二分查找。如果插入的整数超出当前编码范围(如 int16 中插入 int32 的值),整个数组会升级编码。
hashtable:当有非整数元素或数量超过阈值时,转为 hashtable(value 为 NULL)。
set-max-intset-entries 512 # 超过此值转为 hashtable
2.6 ZSet —— listpack + skiplist + hashtable
ZSet 是 Redis 最复杂也最常用的数据结构,有两种编码:
listpack:元素少且值短时使用(与 Hash 类似的阈值)。
skiplist + hashtable:超过阈值时,同时使用跳表和哈希表。
zset-max-listpack-entries 128
zset-max-listpack-value 64
跳表(Skip List)源码解析:
// src/t_zset.h
typedef struct zskiplistNode {
sds ele; // 元素值
double score; // 分值
struct zskiplistNode *backward; // 后退指针
struct zskiplistLevel {
struct zskiplistNode *forward; // 前进指针
unsigned long span; // 跨度(用于计算排名)
} level[]; // 多层指针数组
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length; // 节点数
int level; // 当前最大层数
} zskiplist;
为什么 ZSet 同时用 skiplist 和 hashtable?
- skiplist 支持范围查询(ZRANGE/ZRANGEBYSCORE),O(logN)。
- hashtable 支持 O(1) 的单元素查找(ZSCORE/ZRANK 的 score 查找)。
- 两者共享同一份元素数据,不额外存储副本。
跳表 vs 红黑树:
Redis 作者 antirez 的解释:
- 跳表的实现比红黑树简单得多,代码量少,易于理解和维护。
- 跳表的范围操作天然高效(找到起点后沿链表遍历即可),红黑树需要中序遍历。
- 跳表的内存开销比红黑树略大(每个节点多层指针),但可以接受。
- 跳表的并发性能更好(范围加锁),红黑树调整时可能涉及大量节点重平衡。
跳表插入过程(ZADD 为例):
1. 生成随机层数(ZSKIPLIST_MAXLEVEL=32, p=0.25)
- level 1: 100% 概率
- level 2: 25% 概率
- level 3: 6.25% 概率
- ...
2. 创建新节点,分配 level[] 数组
3. 从最高层开始,找到每层的插入位置(用 update[] 数组记录)
4. 在每层插入新节点,设置 forward 指针
5. 设置 backward 指针
6. 更新 span(跨度)值
2.7 Stream —— 消息队列结构
Redis 5.0 引入 Stream,底层基于 Radix Tree(基数树)。
// src/t_stream.h
typedef struct stream {
rax *rax; // Radix Tree 存储消息
uint64_t length; // 消息总数
streamID maxdeleted; // 最大已删除ID
streamID length; // 最后一条消息ID
rax *nacks; // Consumer Group 的 PEL(待确认消息)
// ...
} stream;
Radix Tree 的 key 是消息 ID(时间戳-序号),value 是消息内容。它压缩了公共前缀,内存效率高。
# 生产消息
XADD mystream * name Alice age 30
# 消费消息
XREAD COUNT 10 STREAMS mystream 0
# 消费组
XGROUP CREATE mystream group1 0
XREADGROUP GROUP group1 consumer1 COUNT 10 STREAMS mystream >
2.8 编码转换总结表
| 类型 | 编码1(小数据) | 转换阈值 | 编码2(大数据) |
|---|---|---|---|
| String | int / embstr | > 44字节 | raw |
| List | listpack | > 128个或单值 > 64B | quicklist |
| Hash | listpack | > 128个或单值 > 64B | hashtable |
| Set | intset | > 512个或有非整数 | hashtable |
| ZSet | listpack | > 128个或单值 > 64B | skiplist+hashtable |
三、持久化机制深度对比
3.1 RDB(Redis Database)
RDB 是将当前内存中的数据以二进制快照形式写入磁盘。
触发方式:
# 手动触发
SAVE # 同步执行,阻塞所有命令,生产禁用
BGSAVE # fork 子进程异步执行,推荐
# 自动触发配置
save 3600 1 # 1小时内至少1个key变化
save 300 100 # 5分钟内至少100个key变化
save 60 10000 # 1分钟内至少10000个key变化
BGSAVE 原理 —— fork + COW(Copy-On-Write):
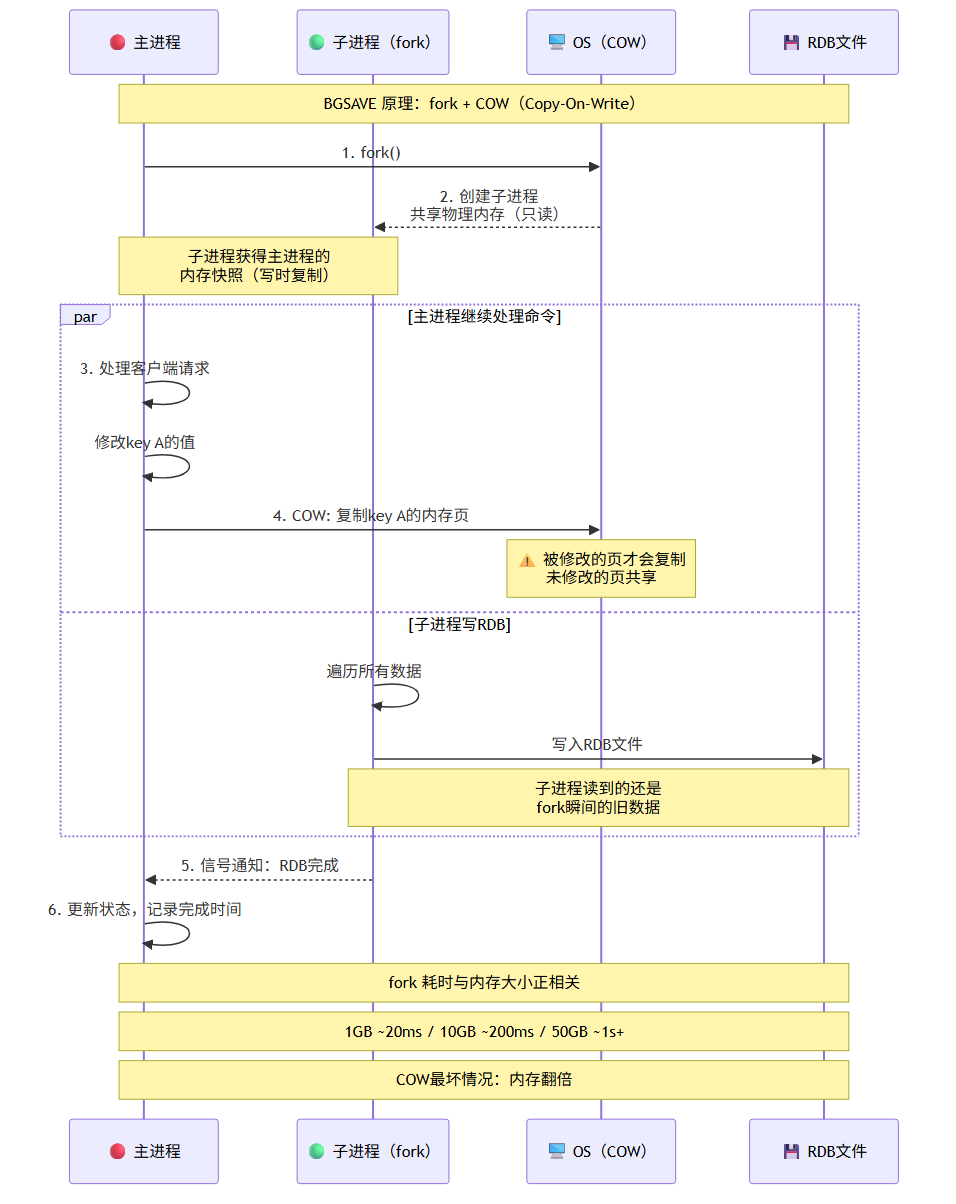
1. 主进程调用 fork(),创建子进程
2. fork 瞬间,子进程和主进程共享同一份物理内存(只读)
3. 子进程遍历所有数据,写入 RDB 文件
4. 此期间主进程仍处理命令
5. 如果主进程修改了某个页,OS 的 COW 机制会复制该页
6. 子进程写完后,通知主进程
主进程 子进程
│ │
├─ fork() ──────────→│ (共享内存)
│ │
├─ 处理命令 ├─ 遍历数据
│ 修改key A │ 写入RDB
│ ↓ │
│ COW: 复制A的页 │ (读到的还是旧值)
│ │
│ ├─ RDB完成
│←── 信号通知 ────────┤
│ │
├─ 更新状态 └─ 退出
RDB 文件格式:
REDIS [5字节 magic]
[版本号] [4字节]
[辅助字段] [元数据:版本、时间、内存使用等]
[db_selector] [数据库选择器]
[键值对...] [TTL + key + value,二进制编码]
EOF [1字节 结束标记]
[8字节校验和] [CRC64]
3.2 AOF(Append Only File)
AOF 以追加方式记录每条写命令到日志文件。
AOF 三种刷盘策略:
appendonly yes
appendfilename "appendonly.aof"
# appendfsync always # 每条命令都刷盘(最安全,性能最差)
appendfsync everysec # 每秒刷盘(默认,推荐:最多丢1秒数据)
# appendfsync no # 由OS决定刷盘(性能最好,可能丢数据较多)
AOF 工作流程:
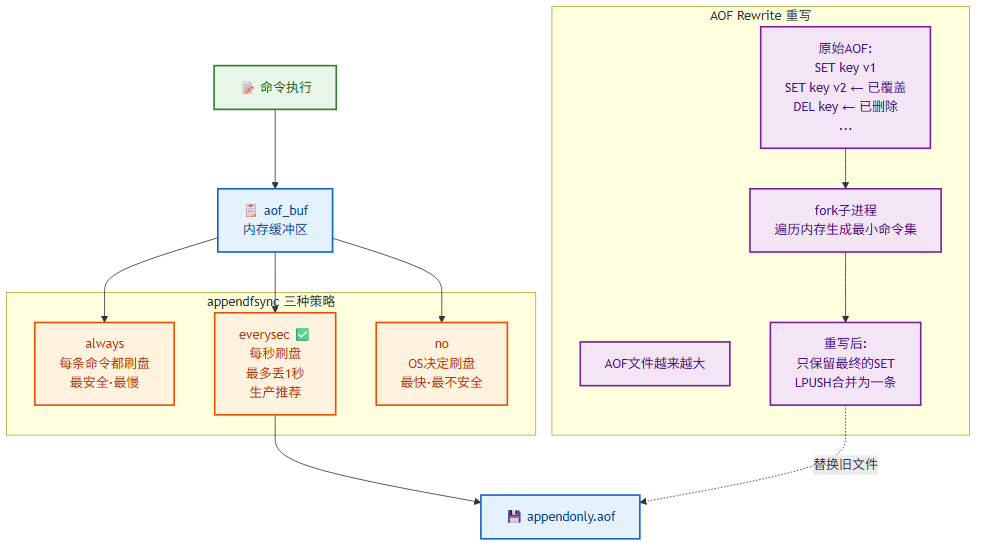
命令执行
↓
追加到 aof_buf(内存缓冲区)
↓
根据 appendfsync 策略写入磁盘
↓
AOF 文件越来越大 → 触发 AOF Rewrite
AOF Rewrite(重写):
AOF 文件持续增长,包含大量过期/已删除的命令。Rewrite 读取当前内存数据,生成最小命令集。
原始AOF:
SET key1 "v1"
SET key1 "v2" ← 已被覆盖
DEL key1 ← 已删除
LPUSH list "a"
LPUSH list "b"
LPUSH list "c"
重写后:
SET key1 "v2" ← 不存在,跳过
LPUSH list "c" "b" "a" ← 合并
Rewrite 同样使用 fork + COW,子进程遍历内存生成新 AOF,主进程继续处理命令。期间的增量命令写入 AOF 重写缓冲区,子进程完成后追加到新文件。
# 自动触发配置
auto-aof-rewrite-percentage 100 # AOF 文件比上次重写后大 100%
auto-aof-rewrite-min-size 64mb # 且 AOF 文件至少 64MB
3.3 混合持久化(Redis 4.0+)
aof-use-rdb-preamble yes # 默认 yes
混合持久化在 AOF Rewrite 时,前半部分写 RDB 格式,后半部分写 AOF 增量命令。
AOF 文件结构:
┌──────────────────────────┐
│ RDB 格式数据(全量快照) │ ← 二进制,紧凑,加载快
├──────────────────────────┤
│ AOF 增量命令(重写期间的变更)│ ← 文本格式,追加
└──────────────────────────┘
恢复时:先加载 RDB 部分(快速),再回放 AOF 增量(少量命令)。
3.4 三种方式对比与生产选择
| 方式 | 数据安全 | 恢复速度 | 文件大小 | 性能影响 | 生产推荐 |
|---|---|---|---|---|---|
| RDB | 可能丢失最后一次快照后数据 | 快(二进制加载) | 小 | BGSAVE 时 fork 开销 | ✅ 灾备 |
| AOF(everysec) | 最多丢1秒 | 中(回放命令) | 大 | 持续 IO | ✅ 主选 |
| 混合 | 最多丢1秒 | 快 | 中 | 同 AOF | ✅ 推荐 |
生产建议:开启 appendonly yes + aof-use-rdb-preamble yes(混合持久化)。RDB 作为冷备,定期 BGSAVE 并将 RDB 文件传到异地/对象存储。
3.5 持久化对性能的影响
fork 的开销:
1. fork 本身耗时 —— 与内存大小正相关
- 1GB 内存: ~20ms
- 10GB 内存: ~200ms
- 50GB 内存: ~1s+
fork 期间主线程阻塞,导致请求超时
2. COW 的内存开销
- 如果 fork 期间大量写入,会复制大量内存页
- 最坏情况:内存翻倍
3. 大量数据写入磁盘的 IO 压力
监控 fork 耗时:
# 查看 info stats
redis-cli info stats | grep latest_fork_usec
# 单位微秒,超过 100000 (100ms) 需要关注
优化方案:① 单实例内存控制在 10GB 以内;② 使用 vm.overcommit_memory = 1 避免 fork 失败;③ 使用 SSD 磁盘;④ 大集群考虑 Redis Cluster 分散单节点内存。
四、内存管理与淘汰策略
4.1 内存分配器
Redis 默认使用 jemalloc 内存分配器(也可选 tcmalloc / libc malloc)。
jemalloc 的优势:
- 按 size class 分配,减少内存碎片
- 小对象分配效率高
- 线程缓存(Thread Cache)减少锁竞争
# 查看内存使用
MEMORY USAGE key # 查看单个 key 占用内存
INFO memory # 查看整体内存信息
# 关键指标
used_memory:1000000 # Redis 分配的总内存(含碎片)
used_memory_rss:1200000 # 操作系统看到的 RSS
mem_fragmentation_ratio:1.2 # RSS / used_memory
# 1.0-1.5: 正常
# > 1.5: 碎片率高
# < 1.0: 可能使用了 Swap(严重!)
4.2 过期策略
Redis 对设置了 TTL 的 key 采用两种策略结合:
惰性过期:访问 key 时检查是否过期,过期则删除。
// src/db.c —— 每次访问 key 前调用
int expireIfNeeded(redisDb *db, robj *key) {
if (!keyIsExpired(db, key)) return 0;
// 过期了,从数据库删除
deleteExpiredKey(db, key);
// 通知从库和AOF
propagateDeletion(db, key);
return 1;
}
优点:CPU 友好,不额外消耗资源。缺点:过期 key 如果长期不被访问,会一直占用内存。
定期过期:Redis 每秒执行 10 次(hz 参数控制)过期扫描。
// src/expire.c —— 定期过期
void activeExpireCycle(int type) {
// 每次随机抽查 20 个设置了 TTL 的 key
// 删除其中已过期的
// 如果过期比例 > 25%,继续抽查下一批
// 每轮执行不超过 25ms
}
为什么是随机抽查而不是全量扫描?因为全量扫描会阻塞主线程。随机抽查 + 自适应策略在 CPU 和内存之间取平衡。
4.3 八种淘汰策略(Redis 4.0+)
当内存使用达到 maxmemory 限制时,触发淘汰策略:
| 策略 | 说明 | 适用场景 |
|---|---|---|
noeviction |
不淘汰,写入报错 | 默认,非缓存场景 |
allkeys-lru |
所有key中淘汰最近最少使用 | 纯缓存推荐 |
allkeys-lfu |
所有key中淘汰最不常用 | 访问频率差异大的缓存 |
allkeys-random |
所有key中随机淘汰 | 无差别缓存 |
volatile-lru |
设置了TTL的key中淘汰LRU | 混合场景(部分数据持久化) |
volatile-lfu |
设置了TTL的key中淘汰LFU | 同上 |
volatile-random |
设置了TTL的key中随机淘汰 | 同上 |
volatile-ttl |
设置了TTL的key中淘汰最快过期的 | 预知过期时间场景 |

LRU 近似算法:
Redis 没有实现真正的 LRU(需要双向链表维护全局顺序,内存开销大),而是使用近似 LRU:
// 淘汰时,随机采样 N 个 key
// maxmemory-samples 5 (默认)
// 从 N 个 key 中淘汰最近最少使用的
// 采样数越大,越接近真实 LRU,但 CPU 开销也越大
Redis 4.0+ 的 LRU 使用了改进的算法:每个 key 的 redisObject.lru 字段(24位)记录最后访问时间(精度秒),淘汰时比较这个时间戳。
LFU 算法:
// redisObject.lru 的 24 位被拆分:
// 高 16 位: 最后访问时间(分钟精度,约 45 天循环)
// 低 8 位: 访问频率计数器(对数计数,0-255)
uint8_t lfu_log_incr(uint8_t counter) {
if (counter == 255) return 255;
double r = (double)rand() / RAND_MAX;
double baseval = counter - LFU_INIT_VAL; // LFU_INIT_VAL = 5
double p = 1.0 / (baseval * lfu_log_factor + 1.0);
// 概率性增加,访问越多增加概率越低
if (r < p) counter++;
return counter;
}
LFU 还会随时间衰减计数器,避免旧热点 key 永远不被淘汰。
# LFU 配置
maxmemory-policy allkeys-lfu
lfu-log-factor 10 # 计数器增长因子,越大增长越慢
lfu-decay-time 1 # 衰减周期(分钟)
4.4 生产内存配置建议
maxmemory 8gb # 限制最大内存
maxmemory-policy allkeys-lru # 缓存场景用 LRU
maxmemory-samples 10 # 采样数从 5 提高到 10,更精准
# 如果使用 LFU
# maxmemory-policy allkeys-lfu
# lfu-log-factor 10
# lfu-decay-time 1
监控:
redis-cli info memory | grep -E "used_memory_human|mem_fragmentation_ratio|maxmemory_human"
# 查看各 key 的大致内存分布
redis-cli --bigkeys # 扫描大 key
redis-cli --memkeys # 扫描内存占用高的 key(6.0+)
五、高可用架构
5.1 主从复制
全量同步流程(首次连接或断线后无法增量同步时):
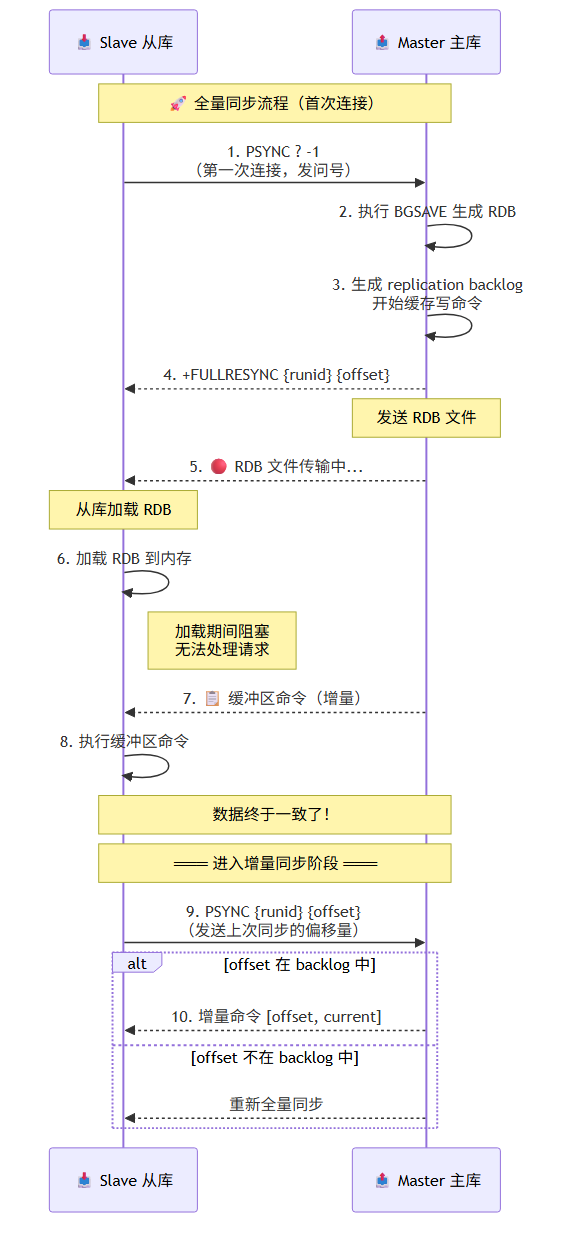
Slave Master
│ │
├─ PSYNC ? -1 (第一次连接) │
│─────────────────────────────────→│
│ ├─ 执行 BGSAVE 生成 RDB
│ ├─ 生成 replication backlog
│←── +FULLRESYNC <runid> <offset> │
│ │
│ ├─ 发送 RDB 文件
│←────────── [RDB 数据] ───────────│
│ │
├─ 加载 RDB ├─ 缓存期间的写命令
│ │
│←── [缓冲区命令] ─────────────────│
│ │
├─ 执行命令,数据一致 │
│ │
│═══ 进入增量同步 ═════════════════│
增量同步流程:
Slave 断线重连
↓
PSYNC <runid> <offset> # 发送上次同步的 runid 和 offset
↓
Master 检查:
1. runid 是否匹配?不匹配 → 全量同步
2. offset 是否在 backlog 中?
- 在 → 增量同步,发送 [offset, current_offset] 的命令
- 不在 → 全量同步(backlog 被覆盖了)
关键参数:
repl-backlog-size 256mb # 环形缓冲区大小,越大越不容易全量同步
repl-backlog-ttl 3600 # backlog 空闲 TTL(无从库后多久释放)
repl-timeout 60 # 超时时间
min-replicas-to-write 1 # 至少1个从库同步成功才允许写入
min-replicas-max-lag 10 # 从库延迟不超过10秒
级联复制:
Master → Slave1 → Slave2 → Slave3
Slave1 既是 Master 的从库,又是 Slave2 的主库。减轻 Master 的复制压力,但增加延迟。
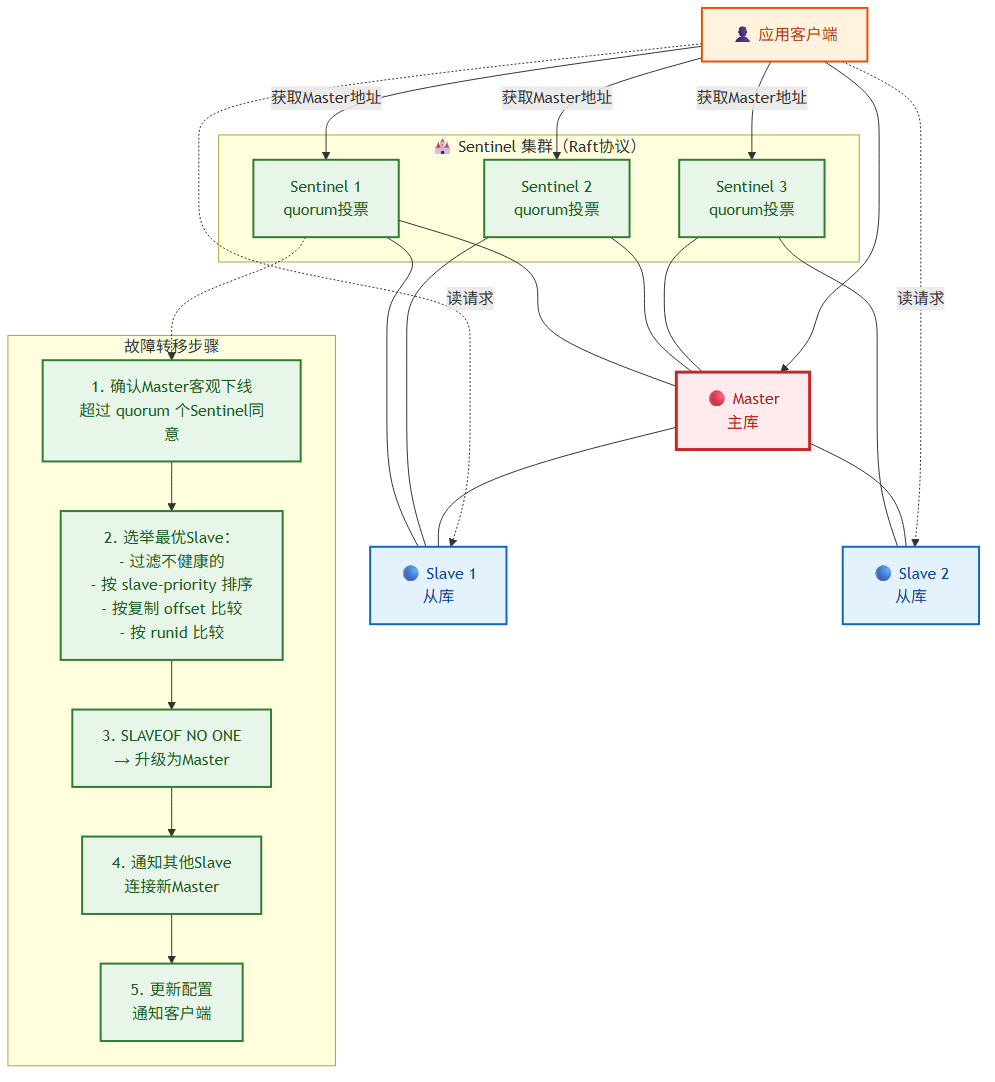
5.2 哨兵(Sentinel)
Sentinel 的核心职责:监控、通知、自动故障转移、配置提供。
┌────────────┐
│ Sentinel 1 │──────┐
│ Sentinel 2 │──────┤ 互相通信 + 监控 Master/Slave
│ Sentinel 3 │──────┘
└────────────┘ ┌────────┐
│ Master │
└────┬───┘
│
┌─────┴─────┐
│ Slave 1 │
│ Slave 2 │
└───────────┘
主观下线(SDOWN):
单个 Sentinel 认为节点不可达(超过 down-after-milliseconds 未响应 PING)。
客观下线(ODOWN):
超过 quorum 个 Sentinel 都认为 Master 主观下线。
Leader 选举(Raft 协议):
Sentinel 之间通过 Raft 协议选出 Leader 执行故障转移。
故障转移步骤:
1. Leader Sentinel 确认 Master 客观下线
2. 从所有 Slave 中选出最优 Slave:
a. 过滤掉不健康的 Slave(断线时间长、响应慢)
b. 按优先级(slave-priority)排序
c. 优先级相同,比较复制 offset(数据最新的)
d. offset 相同,比较 runid(最小的)
3. 对最优 Slave 执行 SLAVEOF NO ONE,升级为 Master
4. 通知其他 Slave 连接新 Master
5. 更新 Sentinel 配置,通知客户端
# sentinel.conf
sentinel monitor mymaster 192.168.1.100 6379 2 # quorum=2
sentinel down-after-milliseconds mymaster 5000 # 5秒无响应判定下线
sentinel failover-timeout mymaster 60000 # 故障转移超时
sentinel parallel-syncs mymaster 1 # 同时同步的从库数
5.3 Cluster 集群
Redis Cluster 采用去中心化的分布式架构,无中心节点。
数据分片 —— 16384 个哈希槽:
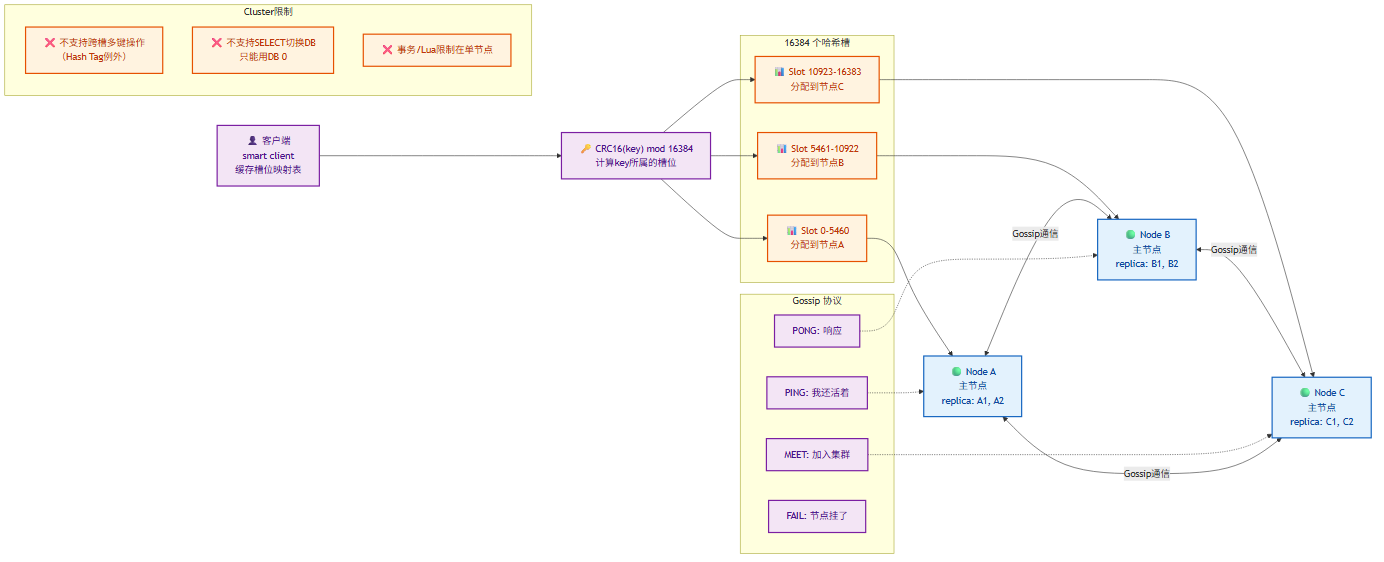
# Key → Slot 的映射算法
slot = CRC16(key) mod 16384
为什么是 16384(2^14)而不是 65536?Redis 作者的答复:① CRC16 的散列效果在 16384 槽时已经足够均匀;② 集群节点间通过 Gossip 协议传播槽位信息,16384 个槽数据包大小合适(2KB),65536 会浪费带宽;③ Redis Cluster 建议最大 1000 节点,16384 槽足够分配。
Cluster 节点通信 —— Gossip 协议:
每个节点定期向其他节点发送 PING 消息,携带自己已知的集群信息。通过这种方式,集群状态最终一致。
Gossip 消息类型:
- PING: "我还活着,这是我知道的集群状态"
- PONG: 响应 PING
- MEET: "加入集群"
- FAIL: "XXX 节点挂了"
- PUBLISH: 广播消息(用于 Pub/Sub)
槽位迁移:
CLUSTER SETSLOT <slot> MIGRATING <target-node-id> # 源节点:准备迁出
CLUSTER SETSLOT <slot> IMPORTING <source-node-id> # 目标节点:准备迁入
# 迁移过程中:
# - GETKEYSINSLOT 获取槽中的 key
# - MIGRATE 逐个迁移 key
# - 迁移完成,广播槽位变更
故障检测与转移:
1. 节点A PING 节点B,超过 cluster-node-timeout 未响应 → 标记 PFAIL(疑似下线)
2. 通过 Gossip 传播 PFAIL 状态
3. 超过半数主节点标记 B 为 PFAIL → 升级为 FAIL(确定下线)
4. B 的从节点检测到 B 下线 → 发起选举
5. 从节点获取半数以上主节点的投票 → 成为新主节点
6. 新主节点接管 B 的槽位,广播集群
Cluster 的限制:
- 不支持跨槽位的多键操作(除非使用 Hash Tag)
- 不支持 SELECT 切换数据库(只能用 DB 0)
- 事务和 Lua 脚本限制在单节点
# Hash Tag: 用 {} 指定 hash 计算的 key 部分
SET {user:1000}:name "Alice" # slot = CRC16("user:1000") mod 16384
SET {user:1000}:age 30 # 同一个 slot,可以多键操作
MSET {user:1000}:name "Alice" {user:1000}:age 30 # ✅ 同一 slot
5.4 高可用方案对比
| 方案 | 数据分片 | 自动故障转移 | 写能力扩展 | 适用规模 |
|---|---|---|---|---|
| 主从复制 | ❌ | ❌ | ❌ | 读多写少,小规模 |
| Sentinel | ❌ | ✅ | ❌ | 中等规模,单 Master |
| Cluster | ✅ 16384槽 | ✅ | ✅ | 大规模,高并发 |
生产建议:
- 数据量 < 30GB,QPS < 10万:主从 + Sentinel
- 数据量 > 30GB 或需要横向扩展:Cluster
- 不需要自动故障转移,只需读写分离:主从复制
六、缓存三大问题
6.1 缓存穿透(Cache Penetration)
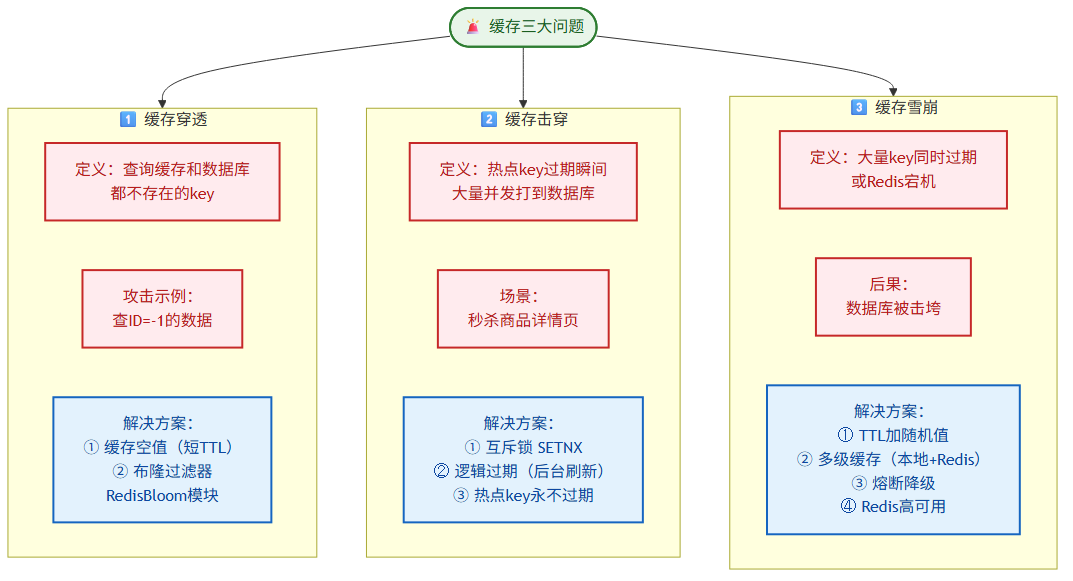
定义:请求查询一个数据库和缓存中都不存在的数据,每次请求都打到数据库。
攻击场景:恶意请求查询 ID=-1 或不存在的 ID。
解决方案:
方案一:缓存空值
def get_user(user_id):
# 1. 查缓存
user = redis.get(f"user:{user_id}")
if user is not None:
if user == "NULL":
return None # 缓存的空值
return json.loads(user)
# 2. 查数据库
user = db.query("SELECT * FROM users WHERE id = %s", user_id)
if user is None:
# 缓存空值,设置较短 TTL
redis.setex(f"user:{user_id}", 300, "NULL")
return None
redis.setex(f"user:{user_id}", 3600, json.dumps(user))
return user
优点:简单。缺点:大量不存在的 key 会浪费内存;数据后来被创建了,缓存还是空值(需要额外处理)。
方案二:布隆过滤器(Bloom Filter)
from pybloom_live import ScalableBloomFilter
# 启动时加载所有存在的 key 到布隆过滤器
bf = ScalableBloomFilter()
for user_id in db.query("SELECT id FROM users"):
bf.add(str(user_id))
def get_user(user_id):
# 1. 先过布隆过滤器
if str(user_id) not in bf:
return None # 一定不存在
# 2. 查缓存
...
# 3. 查数据库
...
优点:内存高效(1亿数据约 100MB)。缺点:有误判率(说存在的可能不存在,说不存在的一定不存在);无法删除元素(可用 Counting Bloom Filter)。
Redis 4.0+ 可通过 RedisBloom 模块直接使用:
# 需安装 RedisBloom 模块
BF.ADD myfilter "user:1001"
BF.EXISTS myfilter "user:1001" # 返回 1(可能存在)
BF.EXISTS myfilter "user:9999" # 返回 0(一定不存在)
6.2 缓存击穿(Cache Breakdown)
定义:某个热点 key 过期瞬间,大量并发请求同时打到数据库。
解决方案:
方案一:互斥锁(Mutex)
import redis
import time
r = redis.Redis()
def get_hot_data(key):
# 1. 查缓存
data = r.get(key)
if data is not None:
return json.loads(data)
# 2. 缓存未命中,尝试获取锁
lock_key = f"lock:{key}"
if r.set(lock_key, "1", nx=True, ex=10): # SETNX + TTL
try:
# 3. 获取锁成功,再次查缓存(双重检查)
data = r.get(key)
if data is not None:
return json.loads(data)
# 4. 查数据库
data = db.query(key)
# 5. 写缓存
r.setex(key, 3600, json.dumps(data))
return data
finally:
r.delete(lock_key) # 释放锁
else:
# 6. 获取锁失败,短暂等待后重试
time.sleep(0.05)
return get_hot_data(key)
方案二:逻辑过期(不设 TTL,在 value 中记录过期时间)
def get_hot_data(key):
data = r.get(key)
if data is None:
return None
data_dict = json.loads(data)
# 检查逻辑过期时间
if data_dict['expire'] > time.time():
return data_dict['data'] # 未过期,直接返回
# 逻辑过期,尝试获取锁异步刷新
if r.set(f"lock:{key}", "1", nx=True, ex=10):
# 后台线程刷新缓存
threading.Thread(target=refresh_cache, args=(key,))
# 返回旧数据(不阻塞用户)
return data_dict['data']
方案三:热点 key 永不过期(定时任务刷新)
适用于极少变化的热点数据(如配置、字典表),设置很长的 TTL 或不设 TTL,由后台任务定期刷新。
6.3 缓存雪崩(Cache Avalanche)
定义:大量 key 同时过期,或 Redis 宕机,导致大量请求打到数据库。
解决方案:
方案一:过期时间加随机值
# 避免大量 key 同时过期
ttl = 3600 + random.randint(-300, 300) # 1小时 ± 5分钟
r.setex(key, ttl, value)
方案二:多级缓存
请求 → 本地缓存(Caffeine/Guava)→ Redis → 数据库
TTL: 60s TTL: 3600s
本地缓存兜底,即使 Redis 宕机也不会全部打到数据库。
方案三:熔断降级
from circuitbreaker import circuit
@circuit(failure_threshold=10, recovery_timeout=30)
def get_data(key):
data = redis.get(key)
if data is None:
data = db.query(key) # 数据库压力大时熔断
return data
# 熔断后返回降级数据
def get_data_safe(key):
try:
return get_data(key)
except CircuitBreakerError:
return get_fallback_data(key) # 返回默认值或缓存
方案四:Redis 高可用,避免单点故障(Sentinel / Cluster)。
七、分布式锁
7.1 基础版:SETNX
# 加锁(原子操作)
SET lock_key unique_value NX PX 30000
# NX: 不存在才设置
# PX 30000: 30秒过期
import uuid
def acquire_lock(key, ttl=30):
value = str(uuid.uuid4())
if redis.set(key, value, nx=True, ex=ttl):
return value
return None
def release_lock(key, value):
# 必须用 Lua 脚本保证原子性
script = """
if redis.call('get', KEYS[1]) == ARGV[1] then
return redis.call('del', KEYS[1])
else
return 0
end
"""
return redis.eval(script, 1, key, value)
基础版的问题:
- 锁过期但业务未完成:业务执行时间超过 TTL,锁被释放,其他客户端获取锁,导致并发问题。
- 无法重入:同一线程不能多次获取同一把锁。
- 无法等待:获取不到锁直接失败,需要客户端自行重试。
- 单点故障:Redis 主从切换时锁可能丢失。
7.2 Redisson 分布式锁
Redisson 是 Redis 的 Java 客户端,提供了功能完善的分布式锁实现。
看门狗(Watchdog)机制:
RLock lock = redisson.getLock("myLock");
lock.lock(); // 自动续期
try {
// 业务逻辑
} finally {
lock.unlock();
}
看门狗原理:
- 获取锁时,如果未指定 TTL,默认设置 30 秒。
- 启动一个定时任务,每 10 秒(TTL/3)检查锁是否还被持有。
- 如果还被持有,将 TTL 重置为 30 秒。
- 如果客户端崩溃,定时任务停止,锁到期自动释放。
// 带超时的锁
lock.lock(10, TimeUnit.SECONDS); // 不会启动看门狗
// 尝试获取锁
boolean acquired = lock.tryLock(5, 30, TimeUnit.SECONDS);
// 5秒内尝试获取,获取到后30秒自动释放
可重入锁实现:
Redisson 使用 Hash 结构实现可重入:
# key: 锁名 field: 客户端ID value: 重入次数
HSET lock_key client_id 1 # 第一次加锁
HINCRBY lock_key client_id 1 # 重入加锁
HINCRBY lock_key client_id -1 # 释放一次
# value 减为 0 时 DEL
Lua 脚本保证原子性:
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hset', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);
7.3 RedLock 算法
针对 Redis 主从切换导致锁丢失的问题,Redis 作者提出了 RedLock:
1. 获取当前时间 T1
2. 依次向 N 个(通常5个)独立的 Redis 实例请求加锁
3. 每个请求设置超时时间(很短,如 50ms)
4. 如果获取了超过 N/2+1(即3个)实例的锁,且总耗时 < TTL,则认为加锁成功
5. 否则向所有实例发送释放锁请求
// Redisson RedLock 使用
RLock lock1 = redisson1.getLock("lockKey");
RLock lock2 = redisson2.getLock("lockKey");
RLock lock3 = redisson3.getLock("lockKey");
RedissonRedLock redLock = new RedissonRedLock(lock1, lock2, lock3);
redLock.lock();
try {
// 业务逻辑
} finally {
redLock.unlock();
}
RedLock 的争议(Martin Kleppmann 的批评):
- 依赖系统时钟,如果某台机器时钟跳变,可能导致锁失效。
- GC 暂停可能导致客户端持锁但无法及时续期。
- 网络分区下的行为不确定。
实际生产建议:对于大多数场景,Redisson 单节点锁(带看门狗)已足够。强一致性要求场景使用 Zookeeper 或 etcd 分布式锁。
八、高并发场景实战
8.1 秒杀系统设计
秒杀核心问题:瞬时高并发读写、库存超卖、系统雪崩。
架构分层:
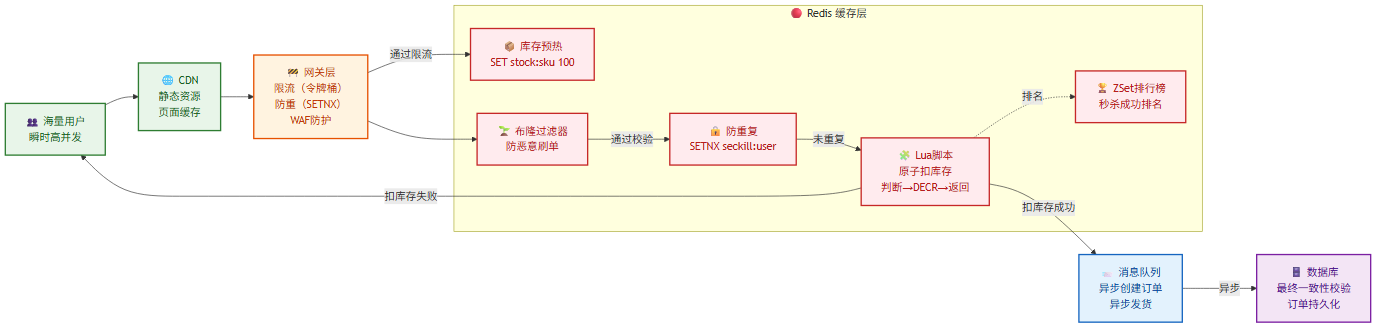
用户 → CDN → 网关(限流)→ 应用层 → 缓存层 → 数据库
Redis 在秒杀中的角色:
① 库存预扣减
# 活动开始前预热库存到 Redis
redis.set("stock:sku:1001", 100) # 100件库存
# 秒杀下单
def seckill(user_id, sku_id):
# 1. 防重:SETNX 判断是否已秒杀
if not redis.set(f"seckill:user:{user_id}:{sku_id}", "1", nx=True, ex=3600):
return "您已秒杀成功,请勿重复参与"
# 2. 扣库存(Lua 保证原子性)
script = """
local stock = redis.call('get', KEYS[1])
if not stock then return -1 end
if tonumber(stock) <= 0 then return 0 end
redis.call('decr', KEYS[1])
return 1
"""
result = redis.eval(script, 1, f"stock:sku:{sku_id}")
if result == 1:
# 3. 发送 MQ 异步创建订单
mq.send("order_queue", {"user_id": user_id, "sku_id": sku_id})
return "秒杀成功,订单创建中"
elif result == 0:
return "已售罄"
else:
return "活动未开始"
② 限流(令牌桶)
# Lua 实现令牌桶限流
LUA_TOKEN_BUCKET = """
local key = KEYS[1]
local capacity = tonumber(ARGV[1]) -- 桶容量
local rate = tonumber(ARGV[2]) -- 令牌生成速率(个/秒)
local now = tonumber(ARGV[3]) -- 当前时间戳(毫秒)
local requested = tonumber(ARGV[4]) -- 请求的令牌数
local bucket = redis.call('hmget', key, 'tokens', 'timestamp')
local tokens = tonumber(bucket[1]) or capacity
local last_time = tonumber(bucket[2]) or now
-- 计算时间差内生成的令牌
local delta = math.max(0, now - last_time) / 1000
tokens = math.min(capacity, tokens + delta * rate)
if tokens < requested then
return 0 -- 令牌不足
end
tokens = tokens - requested
redis.call('hmset', key, 'tokens', tokens, 'timestamp', now)
redis.call('expire', key, math.ceil(capacity / rate) + 1)
return 1
"""
def allow_request(key, capacity=100, rate=10, requested=1):
now = int(time.time() * 1000)
return bool(redis.eval(LUA_TOKEN_BUCKET, 1, key, capacity, rate, now, requested))
③ 排行榜
# 秒杀成功排行榜
redis.zadd("seckill:rank:sku:1001", {user_id: timestamp})
# 获取前 10 名
redis.zrange("seckill:rank:sku:1001", 0, 9, withscores=True)
8.2 排行榜系统
Redis ZSet 天然适合排行榜场景。
# 游戏积分排行榜
redis.zadd("game:rank", {user_id: score})
# 获取Top10
redis.zrevrange("game:rank", 0, 9, withscores=True)
# 获取用户排名
redis.zrevrank("game:rank", user_id) # 返回排名(0开始)
redis.zscore("game:rank", user_id) # 返回分数
# 获取排名区间(如 90-100名)
redis.zrevrange("game:rank", 89, 99, withscores=True)
# 分页查询
page, size = 1, 20
redis.zrevrange("game:rank", (page-1)*size, page*size-1, withscores=True)
实时排行榜优化:
# 百万级用户排行榜
# 1. 定时刷新(每5分钟全量更新)
# 2. 只缓存 Top 1000,之外的用数据库
# 3. 用户查询自己的排名用 ZREVRANK(O(logN))
# 分段缓存优化(避免单个大 ZSet)
def get_rank(user_id):
score = redis.zscore("game:rank", user_id)
if score is None:
return None
# Top 1000 实时查询
if score > redis.zscore("game:rank:top1000",
redis.zrevrange("game:rank:top1000", -1, -1)[0]):
return redis.zrevrank("game:rank:top1000", user_id) + 1
# 其余分段查询
segment = int(score / 1000) # 按 1000 分分段
return redis.zrevrank(f"game:rank:seg:{segment}", user_id) + 1 + offset
8.3 限流系统
计数器限流(固定窗口)
# 每分钟限制 100 次
def rate_limit_fixed(user_id, limit=100):
key = f"rate:{user_id}:{int(time.time() / 60)}"
count = redis.incr(key)
if count == 1:
redis.expire(key, 60)
return count <= limit
问题:窗口边界突刺(59 秒和 1 秒各 100 次 = 1 秒内 200 次)。
滑动窗口限流
# 使用 ZSet 实现
def rate_limit_sliding(user_id, limit=100, window=60):
key = f"rate:{user_id}"
now = time.time()
pipe = redis.pipeline()
# 1. 移除窗口外的记录
pipe.zremrangebyscore(key, 0, now - window)
# 2. 添加当前请求
pipe.zadd(key, {str(uuid.uuid4()): now})
# 3. 统计窗口内请求数
pipe.zcard(key)
# 4. 设置过期时间
pipe.expire(key, window)
results = pipe.execute()
return results[2] <= limit
令牌桶限流(见 8.1 中的 Lua 实现,适合突发流量)
8.4 消息队列
Redis 自身可作为轻量级消息队列,适合中小规模场景。
List 实现队列:
# 生产者
redis.lpush("task_queue", json.dumps(task))
# 消费者(阻塞式)
while True:
result = redis.brpop("task_queue", timeout=30)
if result:
task = json.loads(result[1])
process(task)
Stream 实现消息队列(推荐,Redis 5.0+):
# 生产者
redis.xadd("mystream", {"field1": "value1", "field2": "value2"})
# 消费者(消费者组)
# 创建消费者组
redis.xgroup_create("mystream", "group1", id="0", mkstream=True)
# 消费消息
while True:
messages = redis.xreadgroup(
groupname="group1",
consumername="consumer1",
streams={"mystream": ">"},
count=10,
block=5000
)
for stream, msg_list in messages:
for msg_id, fields in msg_list:
process(fields)
redis.xack("mystream", "group1", msg_id) # 确认消息
# 死信队列:处理 pending 时间过长的消息
pending = redis.xpending("mystream", "group1")
if pending['pending'] > 0:
# 查看待确认消息
messages = redis.xpending_range("mystream", "group1", min="-", max="+", count=10)
for msg in messages:
if msg['time_since_delivered'] > 60000: # 超过60秒
# 转移给其他消费者
redis.xclaim("mystream", "group1", "consumer2",
min_idle_time=60000, message_ids=[msg['message_id']])
Stream vs 专业 MQ(Kafka/RocketMQ):
| 特性 | Redis Stream | Kafka | RocketMQ |
|---|---|---|---|
| 吞吐量 | 万级 | 百万级 | 十万级 |
| 持久化 | AOF/RDB | 磁盘日志 | 磁盘日志 |
| 消费者组 | ✅ | ✅ | ✅ |
| 消息回溯 | ✅ | ✅ | ✅ |
| 事务消息 | ❌ | ❌ | ✅ |
| 延迟队列 | ❌(需额外实现) | ❌ | ✅ |
| 运维成本 | 低(已有Redis) | 高 | 中 |
| 适用场景 | 中小规模,已有Redis | 大数据流处理 | 业务消息 |
8.5 延迟队列
方案一:ZSet 实现
# 添加延迟任务
def add_delay_task(task_id, task_data, delay_seconds):
execute_time = time.time() + delay_seconds
redis.zadd("delay_queue", {json.dumps({"id": task_id, "data": task_data}): execute_time})
# 消费者轮询
def consume_delay_queue():
while True:
# 获取到期任务
now = time.time()
tasks = redis.zrangebyscore("delay_queue", 0, now, start=0, num=10)
for task_json in tasks:
# ZREM 返回 1 表示成功抢到(防止重复消费)
if redis.zrem("delay_queue", task_json):
task = json.loads(task_json)
process(task)
time.sleep(0.1)
方案二:Redis 键过期通知
# 开启键空间通知
redis.config_set("notify-keyspace-events", "Ex")
# 添加延迟任务(设置过期时间 = 延迟时间)
redis.setex(f"delay:task:{task_id}", delay_seconds, task_data)
# 监听过期事件
pubsub = redis.pubsub()
pubsub.psubscribe("__keyevent@0__:expired")
for message in pubsub.listen():
if message['type'] == 'pmessage':
key = message['data'] # delay:task:xxx
task_id = key.split(':')[-1]
task_data = get_task_data(task_id)
process(task_data)
注意:键过期通知不可靠(过期事件可能丢失),生产环境建议用 ZSet 方案或 RocketMQ 延迟消息。
九、性能优化与生产实践
9.1 大 Key 问题
定义:
- String 类型 > 10KB
- Hash/List/Set/ZSet 类型 > 5000 个元素或 > 10MB
危害:
- 网络阻塞:单个大 key 操作耗时,阻塞其他请求
- 内存不均:Cluster 下数据倾斜
- 持久化阻塞:AOF 写入大 key 阻塞主线程
- 删除阻塞:DEL 大 key 阻塞主线程(同步删除)
排查:
# 方法1: redis-cli --bigkeys
redis-cli --bigkeys
# 方法2: 手动扫描
redis-cli --eval scan_bigkeys.lua
# 方法3: MEMORY USAGE
redis-cli memory usage key
解决:
# 1. 拆分大 Hash
# 原: user:1000 (包含 name, age, email, address, ...)
# 拆: user:1000:basic (name, age)
# user:1000:contact (email, phone)
# user:1000:address (...)
# 2. 拆分大 List
# 原: feed:user:1000 (10万条)
# 拆: feed:user:1000:page:0 (1000条)
# feed:user:1000:page:1 (1000条)
# 3. 异步删除大 Key(Redis 4.0+)
# UNLINK 替代 DEL(后台线程异步释放内存)
redis.unlink("big_key")
# 配置自动异步删除
# lazyfree-lazy-eviction yes # 淘汰时异步
# lazyfree-lazy-expire yes # 过期时异步
# lazyfree-lazy-server-del yes # 服务器删除时异步
# lazyfree-lazy-user-del yes # 用户 DEL 时异步
9.2 热 Key 问题
定义:某个 key 被高频访问,导致单节点压力过大。
排查:
# 方法1: redis-cli --hotkeys (需开启 LFU)
redis-cli --hotkeys
# 方法2: MONITOR 命令(生产慎用,影响性能)
# 方法3: 代理层统计(如果有代理层)
解决:
# 1. 本地缓存(多级缓存)
def get_hot_data(key):
# 先查本地缓存
data = local_cache.get(key) # Caffeine / Guava
if data:
return data
# 再查 Redis
data = redis.get(key)
if data:
local_cache.set(key, data, ttl=10) # 本地缓存10秒
return data
# 2. 拆分热 Key(读写分离到多个副本)
# 原单节点热 key: hot:config
# 拆: hot:config:1, hot:config:2, hot:config:3
# 客户端随机访问其中一个
def get_hot_data(key):
n = 3 # 副本数
idx = random.randint(1, n)
return redis.get(f"{key}:{idx}")
# 3. Cluster 下使用读写分离
# 热点 key 的读请求分散到从节点
9.3 Pipeline 批量操作
# 逐条操作(10次网络往返)
for i in range(10):
redis.set(f"key{i}", f"value{i}")
# Pipeline(1次网络往返)
pipe = redis.pipeline()
for i in range(10):
pipe.set(f"key{i}", f"value{i}")
results = pipe.execute()
Pipeline 原理:客户端将多条命令打包发送,服务端依次执行后将结果打包返回,减少网络 RTT。
注意:
- Pipeline 不是原子操作(中间可能插入其他客户端命令)
- 单次 Pipeline 命令数不宜过多(建议 500-1000),否则会阻塞其他请求
- 需要原子性用 MULTI/EXEC 事务
9.4 事务与 Lua 脚本
# MULTI/EXEC 事务
MULTI
SET key1 "value1"
INCR counter
SET key2 "value2"
EXEC
# 注意: Redis 事务不支持回滚!
# 如果 INCR 失败(counter 不是数字),后续命令仍会执行
# Lua 脚本(原子执行,推荐)
script = """
local current = redis.call('get', KEYS[1])
if current == false then
redis.call('set', KEYS[1], ARGV[1])
redis.call('expire', KEYS[1], ARGV[2])
return 1
else
return 0
end
"""
# EVAL 执行,Redis 保证原子性
redis.eval(script, 1, "key", "value", 60)
Lua 脚本优势:
- 原子执行(不会被其他命令打断)
- 减少网络往返
- 可实现复杂逻辑
注意:Lua 脚本执行时间不能太长(默认 5 秒超时),否则会阻塞主线程。
# Lua 脚本超时配置
lua-time-limit 5000 # 毫秒
# 超时后可以 SCRIPT KILL 中止(但可能只执行了一半)
# 如果已经执行了写操作,只能 SHUTDOWN NOSAVE
9.5 生产参数调优清单
# ===== 内存 =====
maxmemory 8gb
maxmemory-policy allkeys-lru
maxmemory-samples 10
# ===== 持久化 =====
appendonly yes
appendfsync everysec
aof-use-rdb-preamble yes
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
save 3600 1
save 300 100
save 60 10000
# ===== 网络 =====
timeout 300 # 客户端空闲超时
tcp-keepalive 60 # TCP keepalive
tcp-backlog 511 # 连接队列
protected-mode yes # 保护模式
# ===== 复制 =====
repl-backlog-size 256mb
repl-timeout 60
min-replicas-to-write 0 # 生产可设 1
min-replicas-max-lag 10
# ===== 性能 =====
hz 10 # 后台任务频率
activerehashing yes # 渐进式 rehash
io-threads 4 # IO 多线程(6.0+)
lazyfree-lazy-eviction yes # 异步释放内存
lazyfree-lazy-expire yes
lazyfree-lazy-server-del yes
lazyfree-lazy-user-del yes
# ===== 客户端缓冲区 =====
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit replica 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
9.6 监控关键指标
| 指标 | 命令 | 告警阈值 |
|---|---|---|
| 内存使用率 | INFO memory → used_memory / maxmemory |
> 80% |
| 碎片率 | INFO memory → mem_fragmentation_ratio |
> 1.5 或 < 1.0 |
| QPS | INFO stats → instantaneous_ops_per_sec |
突增/突降 |
| 连接数 | INFO clients → connected_clients |
> maxclients × 80% |
| 慢查询 | SLOWLOG GET 10 |
单条 > 10ms |
| 主从延迟 | INFO replication → ... |
> 1s |
| 拒绝连接 | INFO stats → rejected_connections |
> 0 |
| Key 过期率 | INFO stats → expired_keys |
突增 |
| 淘汰率 | INFO stats → evicted_keys |
突增 |
| fork 耗时 | INFO stats → latest_fork_usec |
> 100ms |
# Redis 完整监控工具
# 1. redis-stat(实时监控)
redis-stat --server
# 2. RedisLive(Web 可视化)
# 3. Prometheus + redis_exporter + Grafana(推荐)
# 4. redis-cli --latency(延迟监控)
9.7 Redis 常见问题排查
CPU 100%:
# 1. 检查慢查询
redis-cli slowlog get 10
# 2. 检查是否有大 Key 操作
redis-cli --bigkeys
# 3. 检查 Lua 脚本
redis-cli script exists <sha1>
# 4. 检查 MONITOR 是否开启(极度影响性能)
redis-cli info clients
内存持续增长:
# 1. 检查是否有大 Key
redis-cli --bigkeys
# 2. 检查过期策略
redis-cli config get maxmemory-policy
# 3. 检查客户端输出缓冲区
redis-cli client list
# 关注 omem(输出缓冲区内存)
# 4. 检查碎片率
redis-cli info memory | grep fragmentation
# 5. 手动整理碎片(4.0+)
redis-cli memory purge
连接数飙升:
# 1. 查看客户端列表
redis-cli client list
# 关注 age(连接时长)和 cmd(最后执行的命令)
# 2. 检查是否有空闲连接
redis-cli client list | grep -v "cmd=.*"
# 3. 设置超时
redis-cli config set timeout 300
# 4. 检查连接池配置
# 应用侧 HikariCP/Druid 的 maxPoolSize 是否合理
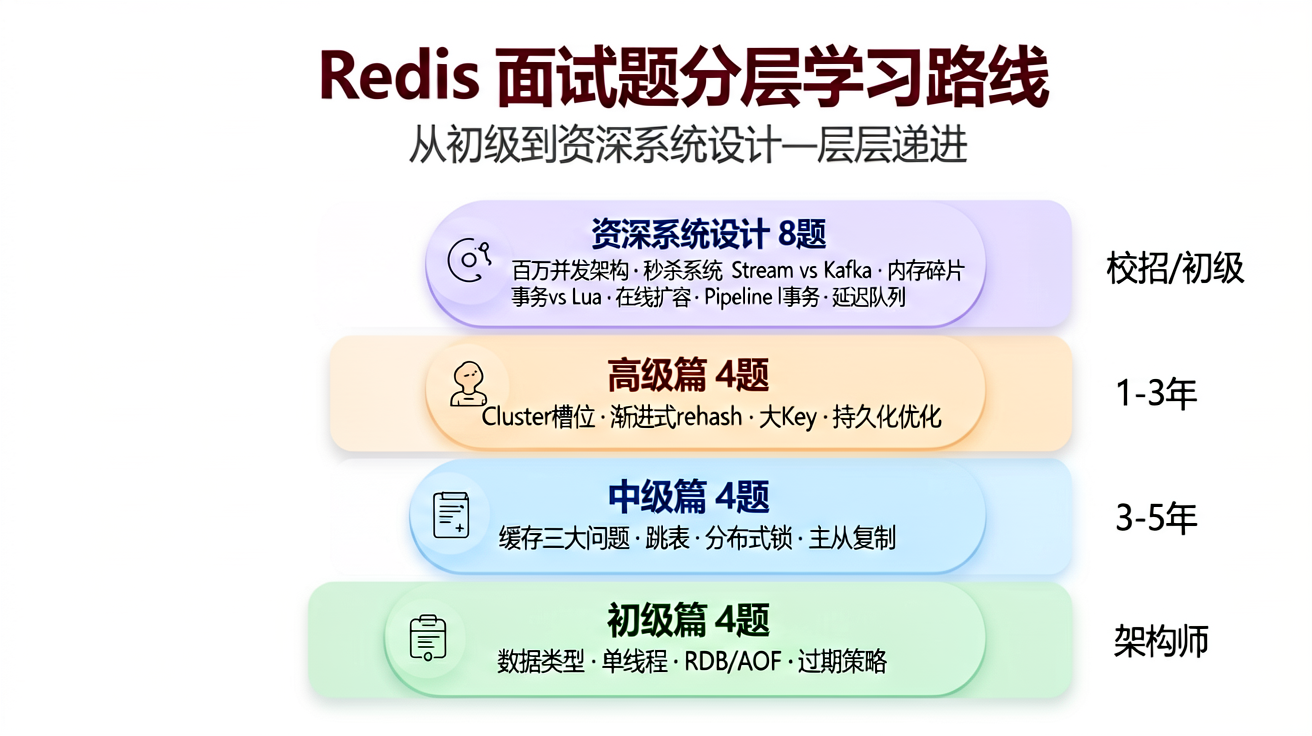
十、分层面试题
初级篇
Q1:Redis 有哪些数据类型?分别适合什么场景?
答:五种基础类型——String(计数器、缓存、分布式锁)、List(消息队列、最新动态)、Hash(用户信息、商品详情)、Set(标签、共同好友、去重)、ZSet(排行榜、延迟队列)。三种高级类型——Bitmap(签到打卡、布隆过滤器)、HyperLogLog(UV 统计,误差 0.81%)、Stream(消息队列,支持消费者组)。Geo(地理位置)本质是 ZSet 的扩展。
Q2:Redis 为什么是单线程的?
答:Redis 的性能瓶颈不在 CPU 而在内存和网络 IO。单线程避免了多线程的上下文切换开销和锁竞争。Redis 的操作都是基于内存的,速度极快,单线程已经能达到 10万+ QPS。Redis 6.0 引入了多线程 IO,但命令执行仍然是单线程,因为所有数据结构操作都是原子的,单线程不需要加锁。
Q3:Redis 的 RDB 和 AOF 有什么区别?
答:RDB 是二进制快照,文件小、恢复快,但可能丢失最后一次快照后的数据。AOF 是命令追加日志,数据安全性高(everysec 最多丢 1 秒),但文件大、恢复慢。Redis 4.0 支持混合持久化(AOF 文件前半部分是 RDB,后半是增量 AOF),兼顾恢复速度和数据安全。生产推荐 AOF + 混合持久化。
Q4:Redis 如何实现过期 key 的删除?
答:两种策略结合——惰性过期(访问 key 时检查是否过期,过期则删除)和定期过期(每秒执行 10 次,随机抽取 20 个设置了 TTL 的 key 检查,过期比例超过 25% 则继续抽查)。惰性过期对 CPU 友好但可能内存浪费,定期过期弥补这一缺陷。
中级篇
Q5:缓存穿透、击穿、雪崩的区别和解决方案?
答:穿透是查询不存在的数据,缓存和数据库都没有。解决方案是缓存空值或使用布隆过滤器。击穿是热点 key 过期瞬间大量请求打到数据库。解决方案是互斥锁(SETNX 加锁后查库写缓存)或逻辑过期(不设 TTL,后台异步刷新)。雪崩是大量 key 同时过期或 Redis 宕机。解决方案是过期时间加随机值、多级缓存、熔断降级、Redis 高可用。
Q6:Redis 的跳表是什么?为什么不用红黑树?
答:跳表是一种多层链表结构,通过概率性的多层索引实现 O(logN) 的查找、插入、删除。相比红黑树——跳表实现简单、范围查询高效(沿链表遍历即可)、并发性能更好(范围加锁)。Redis ZSet 同时使用跳表和哈希表,跳表负责范围查询和排序,哈希表负责 O(1) 的单元素查找。
Q7:Redis 如何实现分布式锁?
答:基础版使用 SET key value NX PX ttl 加锁,Lua 脚本释放锁(判断 value 一致后删除)。但基础版有锁过期业务未完成、不可重入、单点故障的问题。生产推荐 Redisson——看门狗自动续期、Hash 结构实现可重入、支持公平锁和读写锁。强一致性要求场景使用 RedLock(5 个独立 Redis 实例,多数成功才算加锁成功)或 Zookeeper。
Q8:Redis 主从复制的原理是什么?
答:首次连接时全量同步——从库发送 PSYNC,主库执行 BGSAVE 生成 RDB 发送给从库,从库加载 RDB 后进入增量同步。后续通过 replication backlog(环形缓冲区)进行增量同步。如果从库断线重连,发送上次同步的 offset,主库检查 offset 是否在 backlog 中,在则发送增量命令,不在则全量同步。Redis 2.8+ 支持部分重同步(PSYNC)。
高级篇
Q9:Redis Cluster 的槽位为什么是 16384?
答:Redis 作者 antirez 的解释——CRC16 的散列效果在 16384 槽时已足够均匀;集群节点通过 Gossip 协议传播槽位信息,16384 个槽的信息包大小为 2KB(每个槽 1 bit),65536 槽需要 8KB,浪费带宽;Redis Cluster 建议最大 1000 节点,16384 槽足够分配。
Q10:Redis 的渐进式 rehash 是怎么实现的?
答:Redis 字典使用两个哈希表 ht[0] 和 ht[1]。负载因子过高时为 ht[1] 分配空间,标记 rehashidx=0。此后每次增删改查操作,顺便将 ht[0] 中 rehashidx 位置的桶迁移到 ht[1],rehashidx++。rehash 期间写操作在 ht[1],读操作先查 ht[0] 再查 ht[1]。全部迁移后 ht[0]=ht[1],rehashidx=-1。这样避免了一次性 rehash 导致的长时间阻塞。
Q11:Redis 的大 Key 问题如何解决?
答:排查使用 redis-cli --bigkeys 或 MEMORY USAGE。解决方式——①拆分大 Hash/List 为多个小 key;②使用 UNLINK 替代 DEL 异步删除(4.0+);③开启 lazyfree-lazy-eviction 等配置让淘汰/过期时异步释放;④避免在单个 key 中存储过大的值(如不要在一个 Hash 中存 10 万个 field);⑤ Cluster 场景下大 key 会导致数据倾斜,必须拆分。
Q12:Redis 的持久化对性能有什么影响?如何优化?
答:RDB 的 BGSAVE 和 AOF Rewrite 都使用 fork 创建子进程。fork 本身耗时(与内存大小正相关,1GB 约 20ms,10GB 约 200ms),fork 期间主线程阻塞。COW 机制下如果 fork 期间大量写入,会复制内存页导致内存翻倍。优化方案——①单实例内存控制在 10GB 以内;②设置 vm.overcommit_memory=1 避免 fork 失败;③使用 SSD;④AOF Rewrite 安排在低峰期;⑤监控 latest_fork_usec 指标。
资深/系统设计篇
Q13:设计一个支持百万并发的 Redis 缓存架构。
答:分层设计:
接入层:客户端使用连接池(HikariCP,maxPoolSize=20),启用 Pipeline 批量操作减少 RTT。热点 key 使用本地缓存(Caffeine,TTL=10s)作为一级缓存,Redis 作为二级缓存。
缓存层:Redis Cluster 部署,6 主 6 从共 12 节点,每节点 16GB 内存,总容量 96GB。16384 槽均匀分配。开启 AOF + 混合持久化,保证数据安全。
防雪崩:缓存 key 的 TTL 加 ±20% 随机值;使用互斥锁防止缓存击穿;布隆过滤器防止缓存穿透;多级缓存保证 Redis 宕机时本地缓存兜底。
监控:Prometheus + redis_exporter 监控内存、QPS、连接数、慢查询、主从延迟。Grafana 大盘展示。慢查询自动告警。
容灾:Redis Cluster 自动故障转移;每 4 小时 BGSAVE 并将 RDB 上传到对象存储;异地灾备通过 DRDS 同步到备用机房。
Q14:如何用 Redis 实现一个秒杀系统?
答:核心思路——库存预热到 Redis,下单通过 Lua 脚本原子扣减库存,异步 MQ 创建订单。
活动前:将库存写入 Redis SET stock:sku:xxx 100。用户 ID 写入布隆过滤器防刷。
秒杀开始:①网关层令牌桶限流(Redis + Lua);②防重检查 SETNX seckill:user:{uid};③Lua 原子扣库存(判断库存 > 0 → DECR → 返回结果);④成功则发 MQ 异步创建订单;⑤前端轮询订单状态。
容灾:库存 key 设置 TTL 避免残留;MQ 消费失败重试 3 次后进死信队列;Redis Cluster 保证可用性;数据库层做最终库存校验(防超卖兜底)。
Q15:Redis 的 Stream 和 Kafka 有什么区别?如何选择?
答:Redis Stream 适合中小规模(万级 QPS),已有 Redis 基础设施,运维成本低。支持消费者组、消息回溯、ACK 确认。但不支持事务消息、延迟队列、消息堆积能力有限(受内存限制)。Kafka 适合大规模(百万级 QPS),大数据流处理,消息堆积能力强(磁盘存储)。运维成本高,需要独立的 ZK/KRaft 集群。
选择原则:如果已有 Redis 且 QPS < 10万,用 Stream;如果 QPS > 10万或需要消息堆积、流处理,用 Kafka;如果是业务消息(事务、延迟、顺序),用 RocketMQ。
Q16:Redis 的内存碎片是怎么产生的?如何处理?
答:内存碎片产生原因——Redis 频繁修改和删除 key,释放的内存空间不连续,无法被新 key 使用。jemalloc 分配器按 size class 分配,大小不匹配也会产生碎片。
排查:INFO memory 查看 mem_fragmentation_ratio,大于 1.5 说明碎片严重。
处理:Redis 4.0+ 使用 MEMORY PURGE 手动整理碎片;开启 activedefrag yes 自动碎片整理(CPU 开销小);重启 Redis 实例(最暴力但有效,需要在低峰期操作);调整 maxmemory 让 Redis 主动淘汰数据释放空间。
Q17:Redis 的事务和 Lua 脚本有什么区别?
答:Redis 事务(MULTI/EXEC)将多条命令打包顺序执行,中间不会插入其他客户端命令。但 Redis 事务不支持回滚(某条命令出错,后续命令仍执行),且不能根据前一条命令的结果决定后续操作。
Lua 脚本在 Redis 中以原子方式执行,可以实现条件逻辑(根据前一步结果决定下一步操作),减少网络往返。Lua 脚本会被缓存(EVALSHA),减少网络传输。生产推荐用 Lua 脚本替代事务。
# 事务示例(不支持条件逻辑)
MULTI
GET balance
# 这里不能根据 GET 的结果做判断
SET balance 100
EXEC
# Lua 脚本示例(支持条件逻辑)
EVAL "local bal = redis.call('get', KEYS[1]) \
if tonumber(bal) >= tonumber(ARGV[1]) then \
return redis.call('decrby', KEYS[1], ARGV[1]) \
else return -1 end" 1 balance 50
Q18:Redis Cluster 进行扩容时如何保证不停机?
答:在线扩容流程:
①启动新节点并加入集群:CLUSTER MEET。
②使用 redis-cli --cluster reshard 工具迁移槽位。工具会自动执行:CLUSTER SETSLOT MIGRATING/IMPORTING → GETKEYSINSLOT → MIGRATE 逐 key 迁移。
③迁移过程中使用 ASK 重定向:客户端访问正在迁移的槽位时,源节点返回 ASK 重定向到目标节点,客户端临时访问目标节点(不影响请求)。
④迁移完成后更新集群槽位映射。
⑤新节点配置 cluster-node-timeout 适当增大,避免迁移期间误判节点故障。
注意:大规模数据迁移建议在低峰期进行;迁移过程中 Cluster 的性能会有一定下降(ASKN 重定向开销);可以使用 reshard --cluster-yes 非交互模式自动化迁移。
Q19:Redis 的 Pipeline 和事务有什么区别?
答:Pipeline 是客户端行为,将多条命令打包发送,减少网络 RTT,但命令之间可能插入其他客户端命令(非原子)。事务是服务端行为,MULTI/EXEC 之间的命令在服务端顺序执行,中间不会插入其他命令(原子性),但仍有网络往返(MULTI→命令→EXEC)。
Lua 脚本兼具两者优点——原子执行且单次网络往返。选择:只需减少网络开销用 Pipeline;需要原子性用事务或 Lua 脚本(推荐 Lua)。
Q20:Redis 如何实现延迟队列?对比 RocketMQ 延迟消息?
答:Redis 实现延迟队列两种方式——ZSet(score 为执行时间戳,轮询获取到期任务)或键过期通知(不推荐,事件可能丢失)。
ZSet 方案:生产者 ZADD delay_queue timestamp task,消费者定时 ZRANGEBYSCORE 获取到期任务,ZREM 确认。缺点是需要轮询、多个消费者需要去重(ZREM 返回值判断)、无法持久化(重启丢失)。
RocketMQ 延迟消息:生产者发送时指定延迟级别,Broker 存储后定时扫描投递。优点是持久化、高可靠、支持多种延迟级别。缺点是延迟级别固定(1s/5s/10s/30s/1m/…30m/1h/2h,共18级),不支持任意延迟时间。
选择原则:已有 Redis 且延迟任务量小(< 1万/秒)用 Redis ZSet;需要高可靠或大量延迟消息用 RocketMQ;需要任意延迟时间可用 RabbitMQ + 插件或时间轮算法。
附录:Redis 学习路线
第一阶段:基础(1-2周)
五种数据类型及操作命令、TTL 与过期策略、基础持久化概念。目标:熟练使用 Redis CLI 和客户端库。
第二阶段:进阶(2-3周)
底层数据结构实现(SDS/跳表/字典/压缩列表)、内存管理与淘汰策略、主从复制原理。目标:理解 Redis 内部机制,能排查性能问题。
第三阶段:高级(2-3周)
Sentinel 和 Cluster 原理、分布式锁、缓存三大问题解决方案、Lua 脚本编程。目标:能设计 Redis 高可用架构和缓存方案。
第四阶段:生产实战(持续)
大 Key/热 Key 问题排查、参数调优、监控告警、性能压测、故障排查。目标:具备 Redis 运维和问题解决能力。
推荐学习资源:
- 《Redis 设计与实现》——黄健宏(底层原理必读)
- 《Redis 开发与运维》——付磊等
- 《Redis 实战》——Josiah L. Carlson
- Redis 官方文档(redis.io/docs)
- GitHub:
redis/redis源码 - Redis 源码注释:
github.com/huangz1990/redisbook
源码阅读路线:
src/sds.c—— SDS 动态字符串src/dict.c—— 字典与渐进式 rehashsrc/t_zset.c—— 跳表与 ZSet 实现src/adlist.c—— 双向链表src/ae.c—— 事件循环src/networking.c—— 网络处理src/replication.c—— 主从复制src/cluster.c—— 集群src/aof.c/src/rdb.c—— 持久化src/expire.c—— 过期策略
评论区