



引言
在自然语言处理(NLP)和人工智能的发展历程中,Transformer架构的出现无疑是一个里程碑式的事件。自2017年Google团队在论文《Attention Is All You Need》中首次提出Transformer以来,它不仅彻底改变了NLP领域的研究方向,更成为了如今所有大型语言模型(如GPT系列、BERT、T5等)的基石架构。本文将全面深入地解析Transformer架构,从基本原理到关键组件,再到现代大模型的演进,并通过丰富的示例帮助读者理解这一革命性架构的精妙之处。
一、Transformer诞生的历史背景
在Transformer出现之前,主流的序列到序列(Seq2Seq)模型主要基于循环神经网络(RNN)及其变体如长短期记忆网络(LSTM)和门控循环单元(GRU)。这些模型在处理序列数据时存在两个主要局限性:
- 顺序计算限制:RNN必须按顺序处理输入序列,这使得它们难以充分利用现代GPU的并行计算能力。
- 长距离依赖问题:随着序列长度的增加,RNN难以捕捉相距较远的元素之间的关系。
为了解决这些问题,研究者们引入了注意力机制(Attention Mechanism),最初的注意力机制作为RNN的辅助组件,帮助模型聚焦于输入序列中的关键部分。然而,Transformer的提出彻底颠覆了这一思路,它完全摒弃了循环和卷积结构,仅依靠注意力机制来处理序列信息,从而实现了真正的并行计算和强大的长距离依赖建模能力。
二、Transformer整体架构概览
Transformer的整体架构由编码器(Encoder)和解码器(Decoder)两部分组成,这两部分都由若干相同的层堆叠而成。图1展示了Transformer的完整架构示意图。
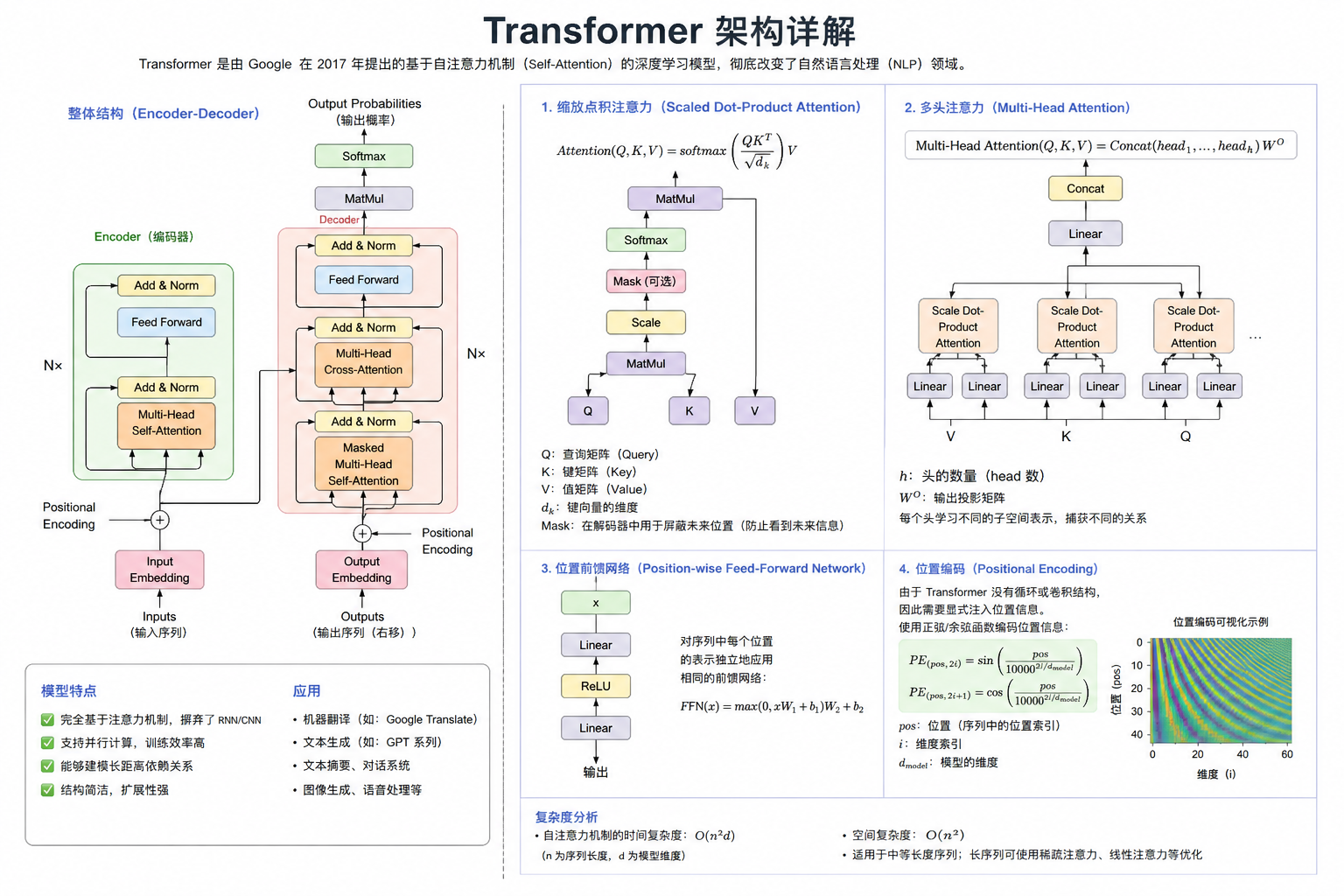
编码器(Encoder)
编码器负责处理输入序列,将其转换为一系列连续表示,捕捉输入序列的语义信息。原始Transformer中的编码器由6个相同的层堆叠而成,每层包含两个子层:
- 多头自注意力机制(Multi-Head Self-Attention)
- 位置前馈神经网络(Position-wise Feed-Forward Network)
每个子层周围都有残差连接(Residual Connection),随后进行层归一化(Layer Normalization)。因此,每个子层的输出可以表示为:LayerNorm(x + Sublayer(x)),其中Sublayer(x)是由子层本身实现的函数。
解码器(Decoder)
解码器负责根据编码器的输出生成目标序列。解码器同样由6个相同的层堆叠而成,每层包含三个子层:
- 带掩码的多头自注意力机制(Masked Multi-Head Self-Attention)
- 编码器-解码器注意力(Encoder-Decoder Attention)
- 位置前馈神经网络(Position-wise Feed-Forward Network)
与编码器类似,每个子层周围也有残差连接和层归一化。
三、Transformer核心组件详解
3.1 输入表示
Transformer的输入表示由两部分组成:词嵌入(Token Embedding)和位置编码(Positional Encoding)。
词嵌入
词嵌入将输入序列中的每个词转换为固定维度的向量表示。与传统的one-hot编码相比,词嵌入能够捕捉词语之间的语义相似性。例如,"猫"和"狗"的嵌入向量在向量空间中距离较近,而"猫"和"汽车"的嵌入向量距离较远。
import torch
import torch.nn as nn
class Embeddings(nn.Module):
def __init__(self, vocab_size, d_model):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab_size, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
位置编码
由于Transformer本身不包含任何循环或卷积结构,它无法直接捕捉序列中元素的顺序信息。因此,Transformer引入了位置编码来显式地注入位置信息。原始Transformer使用正弦和余弦函数的不同频率来生成位置编码:
$ PE_{(pos, 2i)} = \sin(pos / 10000^{2i/d_{model}}) $
$ PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i/d_{model}}) $
其中,pos是位置索引,i是维度索引。这种设计使得模型能够轻松学习相对位置关系,因为对于任意固定偏移量k,PE_{pos+k}可以表示为PE_{pos}的线性函数。
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 计算位置编码
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1)].requires_grad_(False)
return self.dropout(x)
3.2 注意力机制
注意力机制是Transformer的核心创新,它允许模型在处理每个词时,动态地关注输入序列中的其他词。Transformer中使用的是缩放点积注意力(Scaled Dot-Product Attention)。
缩放点积注意力
给定查询(Query)、键(Key)和值(Value)三个矩阵,注意力计算过程如下:
- 计算查询和键的点积,得到注意力分数
- 将注意力分数除以键维度的平方根(缩放因子)
- 对缩放后的注意力分数应用softmax函数,得到注意力权重
- 使用注意力权重对值进行加权求和,得到最终输出
$ Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V $
- 其中,
d_k是键的维度。
def attention(query, key, value, mask=None, dropout=None):
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = scores.softmax(dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
多头注意力
多头注意力机制允许模型在不同的表示子空间中并行地关注信息。具体来说,它将查询、键和值分别通过h个不同的线性变换,然后对每个头(head)执行缩放点积注意力,最后将所有头的输出拼接起来,再通过一次线性变换。
$ MultiHead(Q, K, V) = Concat(head_1, …, head_h)W^O $
$ head_i = Attention(QW_i^Q, KW_i^K, VW_i^V) $
其中,W_i^Q、W_i^K、W_i^V是投影矩阵,W^O是输出投影矩阵。
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) 执行所有线性投影
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]
# 2) 批量执行注意力
x, self.attn = attention(
query, key, value, mask=mask, dropout=self.dropout
)
# 3) 拼接所有头并执行最终的线性投影
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
del query
del key
del value
return self.linears[-1](x)
3.3 前馈神经网络
每个编码器和解码器层都包含一个位置前馈神经网络(Position-wise Feed-Forward Network),它对每个位置单独且相同地应用两个线性变换,中间夹着一个ReLU激活函数:
$ FFN(x) = max(0, xW_1 + b_1)W_2 + b_2 $
虽然线性变换在不同位置上是相同的,但它们在层与层之间使用不同的参数。另一种描述方式是两个卷积核大小为1的卷积。输入和输出的维度都是d_model = 512,内部层的维度d_ff = 2048。
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
3.4 残差连接和层归一化
Transformer中的每个子层周围都有残差连接,随后进行层归一化。这使得模型的训练更加稳定和高效。残差连接可以表示为:x + Sublayer(x),其中Sublayer(x)是由子层本身实现的函数。
层归一化(Layer Normalization)与批归一化(Batch Normalization)不同,它对每个样本的所有特征进行归一化,而不是对一个批次中的同一个特征进行归一化。层归一化在序列数据上表现更好,因为它不依赖于批次大小。
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
3.5 编码器层
编码器层由多头自注意力子层和位置前馈神经网络子层组成,每个子层周围都有残差连接和层归一化。
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
3.6 解码器层
解码器层由三个子层组成:带掩码的多头自注意力子层、编码器-解码器注意力子层和位置前馈神经网络子层,每个子层周围都有残差连接和层归一化。
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
四、Transformer完整实现
下面给出一个完整的Transformer模型的PyTorch实现:
class Encoder(nn.Module):
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(src_vocab, d_model), c(position)),
nn.Sequential(Embeddings(tgt_vocab, d_model), c(position)),
Generator(d_model, tgt_vocab),
)
# 初始化参数
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
五、Transformer的训练与推理
5.1 训练过程
Transformer的训练过程通常使用标准的监督学习方法。输入是一对序列(源序列和目标序列),模型需要学习将源序列映射到目标序列。训练过程中,解码器的自注意力子层使用了掩码(mask),以防止当前位置关注到后续位置的信息(即防止"偷看"答案)。
损失函数通常使用交叉熵损失(Cross-Entropy Loss),优化器可以使用Adam优化器,学习率采用带预热(warmup)的调度策略。
class NoamOpt:
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
def step(self):
self._step += 1
rate = self.rate()
for p in self.optimizer.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step=None):
if step is None:
step = self._step
return self.factor * \
(self.model_size ** (-0.5) *
min(step ** (-0.5), step * self.warmup ** (-1.5)))
def get_std_opt(model):
return NoamOpt(model.src_embed[0].d_model, 2, 4000,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
5.2 推理过程
在推理(生成)过程中,解码器逐步生成目标序列。最初,解码器的输入是一个特殊的开始符号(如<s>)。然后,模型将当前位置的输出作为下一步的输入,直到生成特殊的结束符号(如</s>)或达到最大长度限制。
def decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len-1):
out = model.decode(memory, src_mask,
ys,
subsequent_mask(ys.size(1)).type_as(src.data))
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim = 1)
next_word = next_word.data[0]
ys = torch.cat([ys,
torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
return ys
六、Transformer的变体与改进
自Transformer提出以来,研究者们提出了许多变体和改进,以适应不同的任务和需求。以下是几个重要的变体:
6.1 BERT(Bidirectional Encoder Representations from Transformers)
BERT只使用了Transformer的编码器部分,并在大规模语料库上进行了预训练。它引入了两种新的预训练任务:
- 掩码语言模型(Masked Language Model, MLM):随机掩码输入序列中的一些词,然后让模型预测这些被掩码的词。
- 下一句预测(Next Sentence Prediction, NSP):给定两个句子,预测它们是否在原始文本中是连续的。
BERT在各种NLP任务上取得了显著的性能提升,成为了许多下游任务的基础模型。
6.2 GPT(Generative Pre-trained Transformer)
GPT系列模型只使用了Transformer的解码器部分,专注于生成任务。与BERT不同,GPT使用标准的语言模型预训练目标,即预测下一个词。随着模型规模的扩大,GPT展现了惊人的生成能力和涌现行为。
6.3 T5(Text-to-Text Transfer Transformer)
T5将所有NLP任务都转换为文本到文本(Text-to-Text)的形式,使用统一的编码器-解码器架构。T5在多种任务上进行了系统性的探索,包括不同的预训练目标和架构变体。
6.4 其他改进
其他重要的改进包括:
- 更高效的位置编码:如相对位置编码、旋转位置编码(RoPE)等
- 更高效的注意力机制:如稀疏注意力、线性注意力等,以降低计算复杂度
- 更大的模型规模:随着计算资源的增加,模型参数量从最初的数百万增长到数千亿
- 更好的预训练策略:如更长的预训练、更多样化的数据、多模态预训练等
七、Transformer在实践中的应用
Transformer架构已经广泛应用于各种任务和领域,以下是一些典型应用:
7.1 机器翻译
Transformer最初就是为了解决机器翻译问题而提出的。在机器翻译任务中,源语言序列由编码器处理,解码器生成目标语言序列。Transformer在多种语言对上取得了当时的最优结果。
# 机器翻译示例
src = "I love natural language processing."
src_tokens = tokenize(src)
src_tensor = convert_to_tensor(src_tokens)
src_mask = (src_tensor != PAD).unsqueeze(-2)
# 翻译
translation = decode(model, src_tensor, src_mask, max_len=50, start_symbol=BOS_IDX)
detokenized_translation = detokenize(translation)
print("Translation:", detokenized_translation)
7.2 文本摘要
文本摘要任务可以视为一个特殊的文本到文本问题,其中源文本是长文档,目标文本是摘要。Transformer可以通过训练来生成简洁的摘要,捕捉文档的关键信息。
# 文本摘要示例
document = "A long document..."
doc_tokens = tokenize(document)
doc_tensor = convert_to_tensor(doc_tokens)
doc_mask = (doc_tensor != PAD).unsqueeze(-2)
# 生成摘要
summary = decode(model, doc_tensor, doc_mask, max_len=30, start_symbol=BOS_IDX)
detokenized_summary = detokenize(summary)
print("Summary:", detokenized_summary)
7.3 问答系统
在问答系统中,Transformer可以处理问题和上下文,生成准确的答案。对于抽取式问答,可以使用编码器表示输入,然后预测答案在上下文中的位置;对于生成式问答,可以使用编码器-解码器架构直接生成答案。
# 问答示例
context = "The Transformer architecture was introduced in 2017..."
question = "When was the Transformer architecture introduced?"
context_tokens = tokenize(context)
question_tokens = tokenize(question)
context_tensor = convert_to_tensor(context_tokens)
question_tensor = convert_to_tensor(question_tokens)
# 获取答案
answer = model.generate_answer(context_tensor, question_tensor)
detokenized_answer = detokenize(answer)
print("Answer:", detokenized_answer)
7.4 代码生成与补全
Transformer可以学习编程语言的语法和模式,用于代码生成、代码补全甚至程序理解。这对于提高编程效率和代码质量具有重要意义。
# 代码补全示例
prefix = "def quick_sort(arr):"
prefix_tokens = tokenize_code(prefix)
prefix_tensor = convert_to_tensor(prefix_tokens)
# 补全代码
completion = decode(model, prefix_tensor, prefix_mask, max_len=100, start_symbol=BOS_IDX)
detokenized_completion = detokenize_code(completion)
print("Code completion:", detokenized_completion)
八、Transformer的挑战与未来方向
尽管Transformer架构取得了巨大的成功,但它仍然面临一些挑战和限制,未来的研究可能会集中在以下几个方向:
8.1 计算效率
Transformer的计算复杂度与序列长度的平方成正比,这使得它难以处理非常长的序列。虽然已经提出了一些更高效的注意力机制,但如何在不牺牲性能的情况下进一步提高计算效率仍然是一个重要问题。
8.2 模型压缩与部署
随着模型规模的不断增长,如何压缩和部署这些大型模型成为了一个关键挑战。模型蒸馏、量化和剪枝等技术将在未来的研究中发挥重要作用。
8.3 多模态扩展
虽然最初是为文本处理设计的,但Transformer架构已经被成功扩展到图像、音频、视频等多种模态。未来的研究可能会更深入地探索多模态学习,实现真正的跨模态理解和生成。
8.4 可解释性与鲁棒性
随着模型规模的增长,模型的内部机制变得越来越不透明。如何提高模型的可解释性和鲁棒性,使其行为更加可控和可预测,是一个重要的研究方向。
8.5 更少的预训练数据
当前的大型语言模型需要海量的预训练数据,这在某些语言或领域可能不可用。如何设计更高效的模型,使其能够从更少的数据中学习,是一个具有挑战性的问题。
九、总结
Transformer架构的提出彻底改变了自然语言处理乃至整个人工智能领域的研究方向。其创新性的注意力机制、并行计算能力和强大的表示学习能力,使得它成为了现代大型语言模型的基础架构。通过本文的详细解析,我们深入了解了Transformer的各个组件和工作原理,并通过示例代码看到了其具体实现。
从最初的机器翻译应用到如今的通用人工智能系统,Transformer架构不断演进,催生了一系列突破性的模型和应用。尽管仍面临计算效率、模型部署、可解释性等挑战,但随着研究的深入和技术的进步,我们有理由相信,Transformer架构及其变体将在未来的人工智能发展中继续发挥核心作用。
对于希望深入了解和实践Transformer的读者,建议从实现简单的Transformer模型开始,逐步尝试不同的变体和改进,并在实际应用中不断探索和优化。通过实践,您将更好地理解这一革命性架构的精妙之处,并为未来的研究和工作打下坚实基础。
评论区