
多智能体协作工程化实践:从 Codex 到 OpenClaw 的拓扑与调度
多智能体协作在抖音小红书经常被讲成一个看着很牛逼的团队故事:一个 agent 查资料,一个 agent 写代码,一个 agent 跑测试,一个 agent 做 review,最后主 agent 像项目经理一样把结果收回来。然后下面评论区:“我去好牛逼!”
但是真正使用过多智能体,或者说真正高效的运用多智能体的人看到,只是笑着摇摇头。因为多智能体从来不是"多开几个模型实例"这么简单,还要考虑任务调度、上下文隔离、权限控制、状态管理和结果合并机制等东西。
换成工程语言,就是:
- 谁有权创建 worker?
- worker 拿到多少上下文?
- 它能不能写文件?
- 多个 worker 写到同一区域怎么办?
- worker 失败、超时、被用户中断时,父任务怎么恢复?
- 结果回来以后,谁判断冲突,谁承担最后的 merge 责任?
这样一堆问题。
所以我们怎么去更好的搭建自己的多智能体团队?不妨先看看 Codex、Claude Code、OpenClaw、Hermes Agent,学习它们是怎么做的。
触发与拓扑
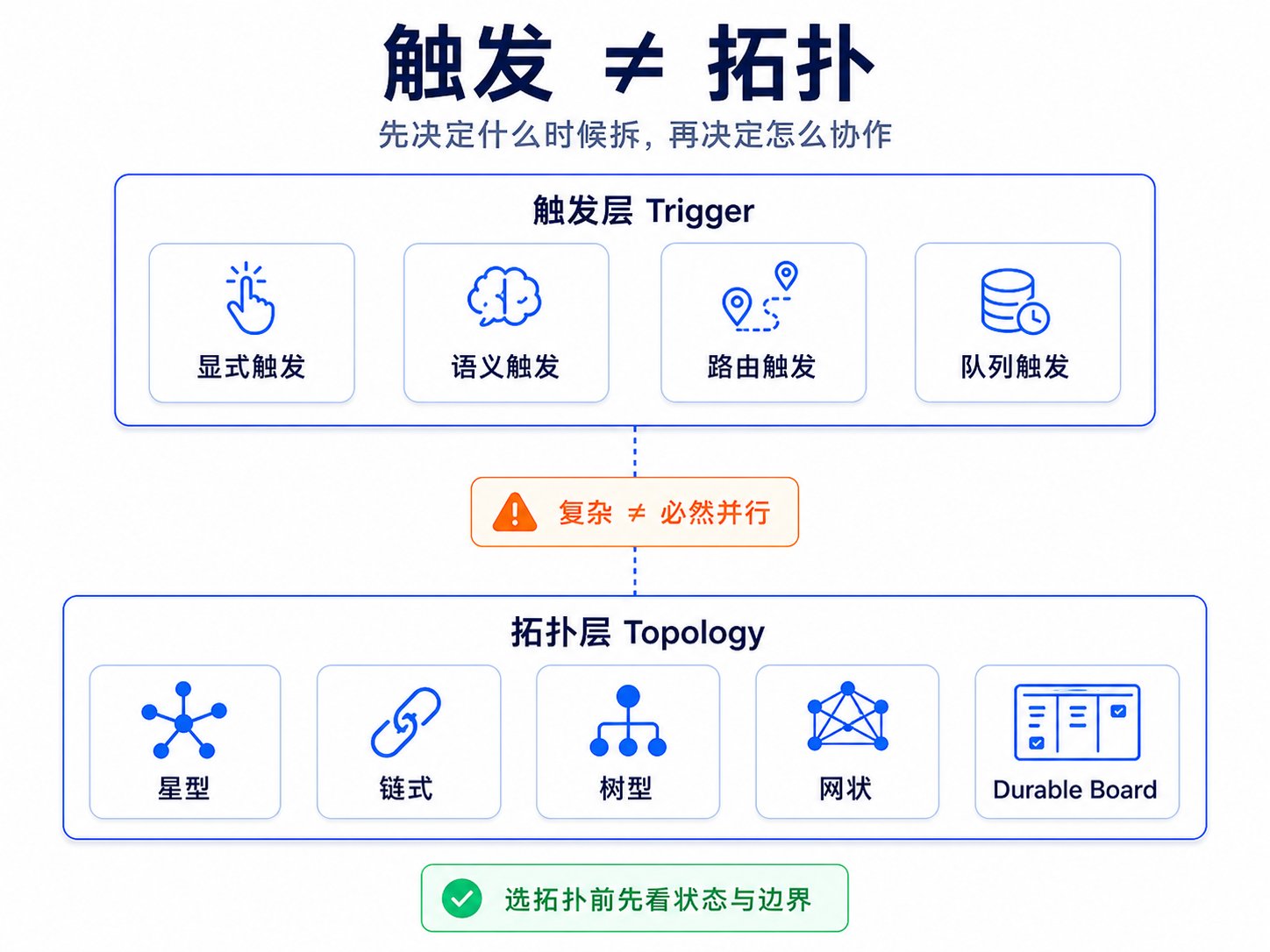
图:触发方式与拓扑结构分类
很多讨论混在一起,是因为大家把两个问题当成了一个问题。
第一个问题是触发:系统什么时候从单 agent 变成多 agent?
第二个问题是拓扑:一旦变成多 agent,它们怎么组织?是主 agent 派几个 worker 后统一收口,还是 worker 之间能互相通信?是当前 turn 里等结果回来,还是把任务放进持久队列,明天再继续?
触发方式
触发方式大致有四类:
第一类是显式触发。用户直接说"use parallel subagents"“spawn one agent per review category”“delegate this work in parallel”。Codex 主要属于这一类。它不会因为任务看起来复杂就擅自开一堆 worker,而是把并行授权留给用户和主 agent。
第二类是语义触发。主 agent 根据任务内容和 subagent description 判断是否调用某个专家 agent。Claude Code 的普通 subagent 主要属于这一类。description 写得越像触发条件,系统越容易在合适的时间调用它;description 写得越像一句愿望,系统越容易乱叫人。
第三类是路由触发。系统不是先问"这个任务复杂吗",而是先看消息来自哪里。OpenClaw 会根据 channel、account、thread、peer、guild、role 等入口信息选择 agent。Slack ops channel 进 ops agent,私人 Telegram 进 deep work agent,家庭入口进低权限 assistant。
第四类是队列触发。任务被写进 board、queue、cron 或 background job,由 dispatcher 按状态和 assignee 拉起 worker。Hermes Kanban 属于这一类。这里的关键不再是本轮对话里能不能马上返回,而是任务能不能跨 turn、跨天、跨重启、跨人类介入。
拓扑结构
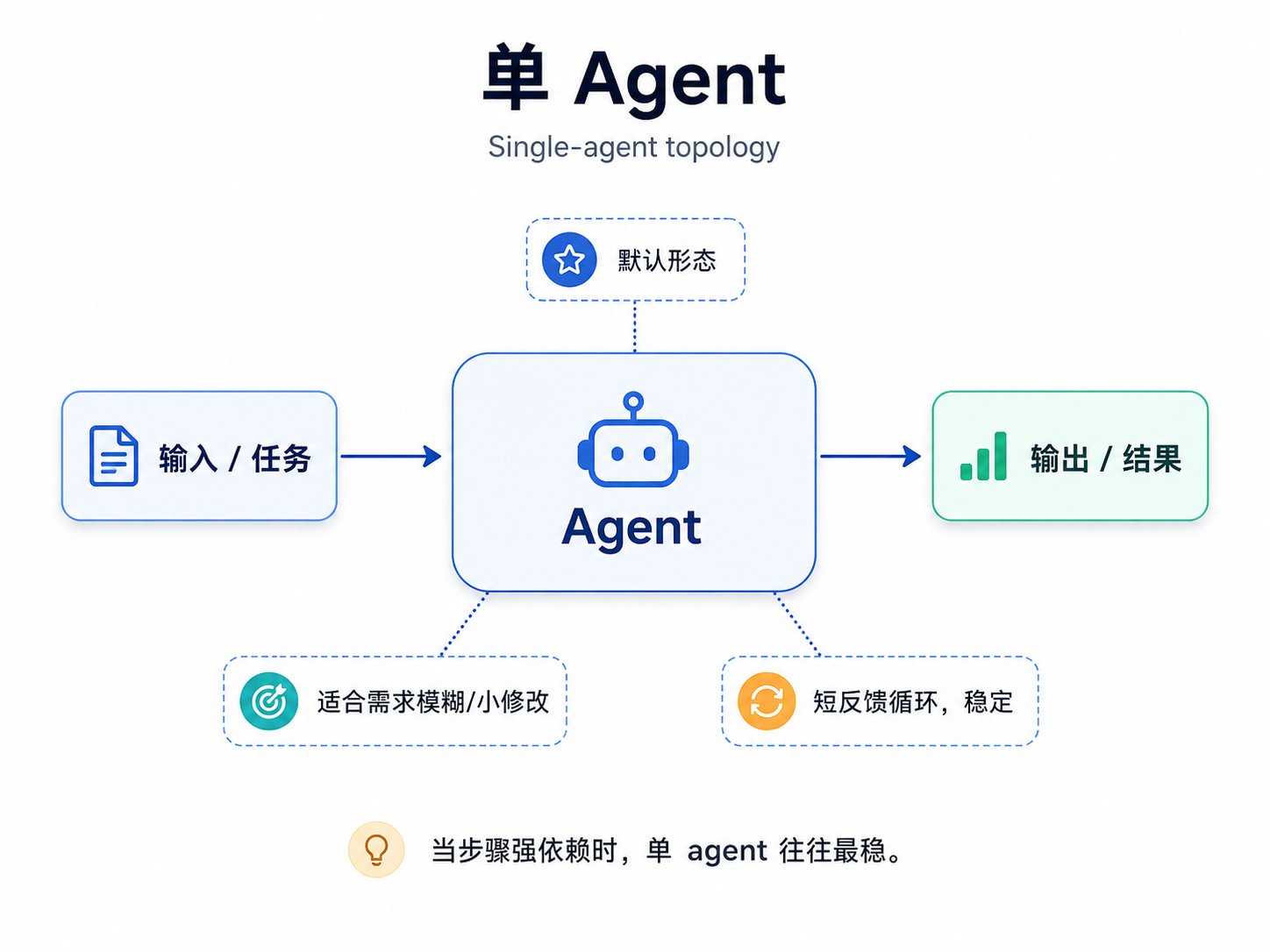
图:单 agent — 最简单的默认形态
单 agent 是默认形态。需求模糊、修改很小、步骤强依赖时,单 agent 往往最稳定。很多任务不需要多智能体,只需要更好的上下文和更短的反馈循环。
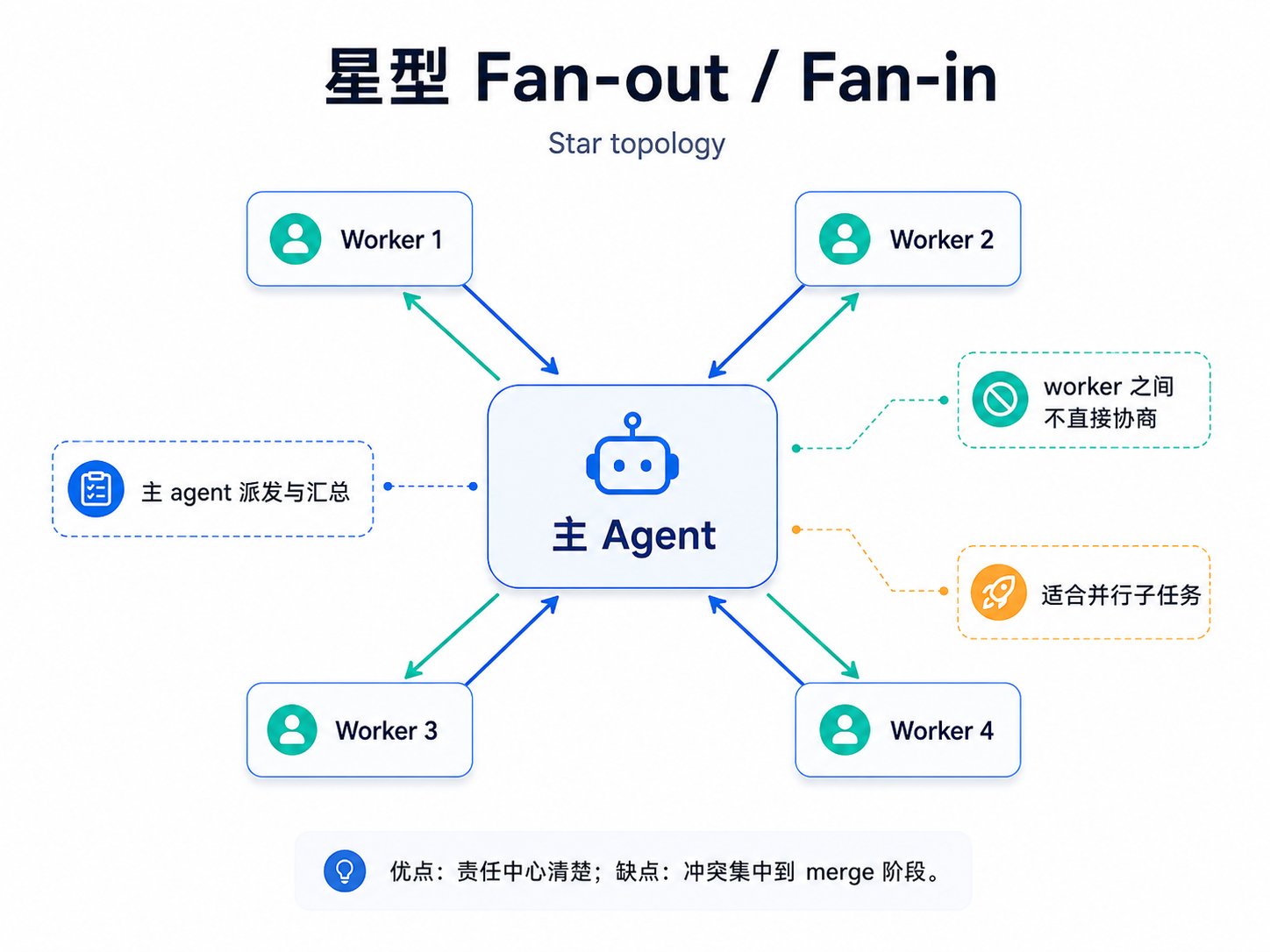
图:星型 fan-out/fan-in — 最常见的 subagent 形态
星型 fan-out/fan-in 是最常见的 subagent 形态。一个主 agent 派多个 worker,worker 之间不直接协商,结果回到主 agent,主 agent 做 reduce。Codex subagents、Claude 普通 subagents、Hermes delegate_task 都主要是这种结构。它的优点是责任中心清楚,缺点是 worker 之间不能互相纠错,所有冲突都压到主 agent 的 merge 阶段。
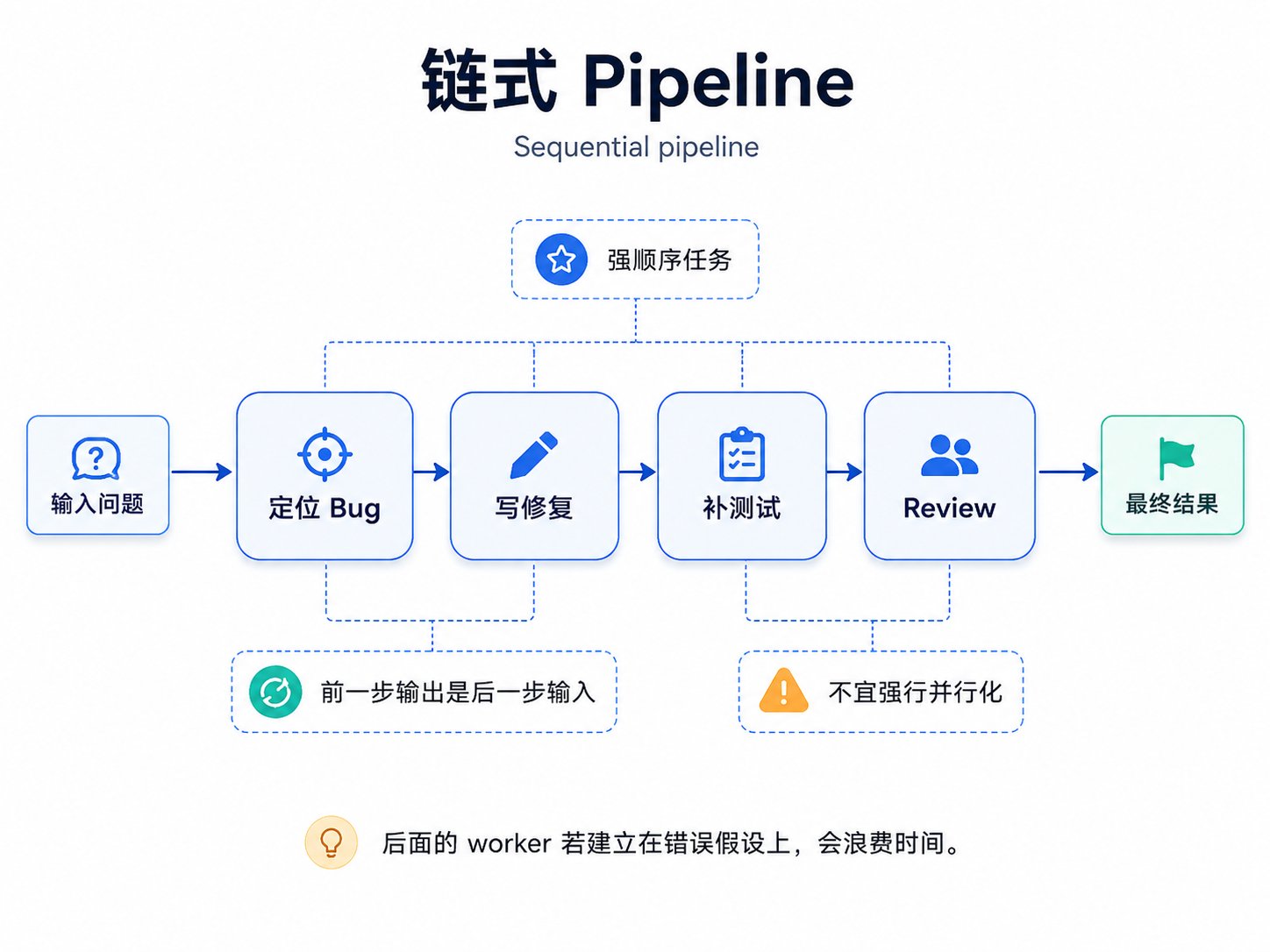
图:链式 pipeline — 适合强顺序任务
链式 pipeline 适合强顺序任务。比如先定位 bug,再写修复,再补测试,再 review。硬把这种任务并行化,通常只会让后面的 worker 在错误假设上浪费时间。
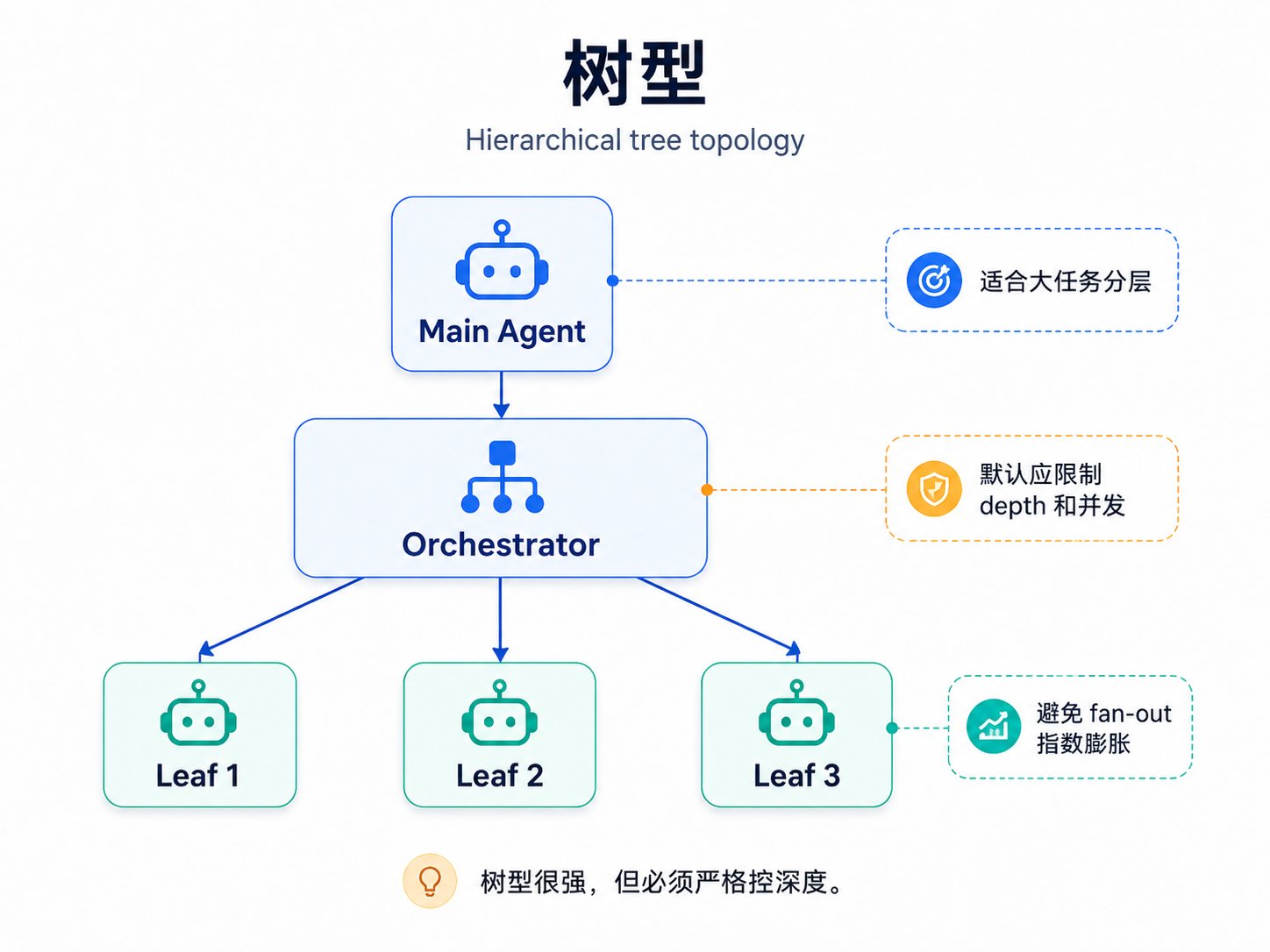
图:树型 — 分层委派,适合大任务
树型 适合大任务分层。main agent 派一个 orchestrator,orchestrator 再派几个 leaf workers。树型看起来强,但要严格限制 depth 和并发,否则 fan-out 会指数级膨胀。OpenClaw 和 Hermes 都把默认深度压得很低,就是在控制这个风险。
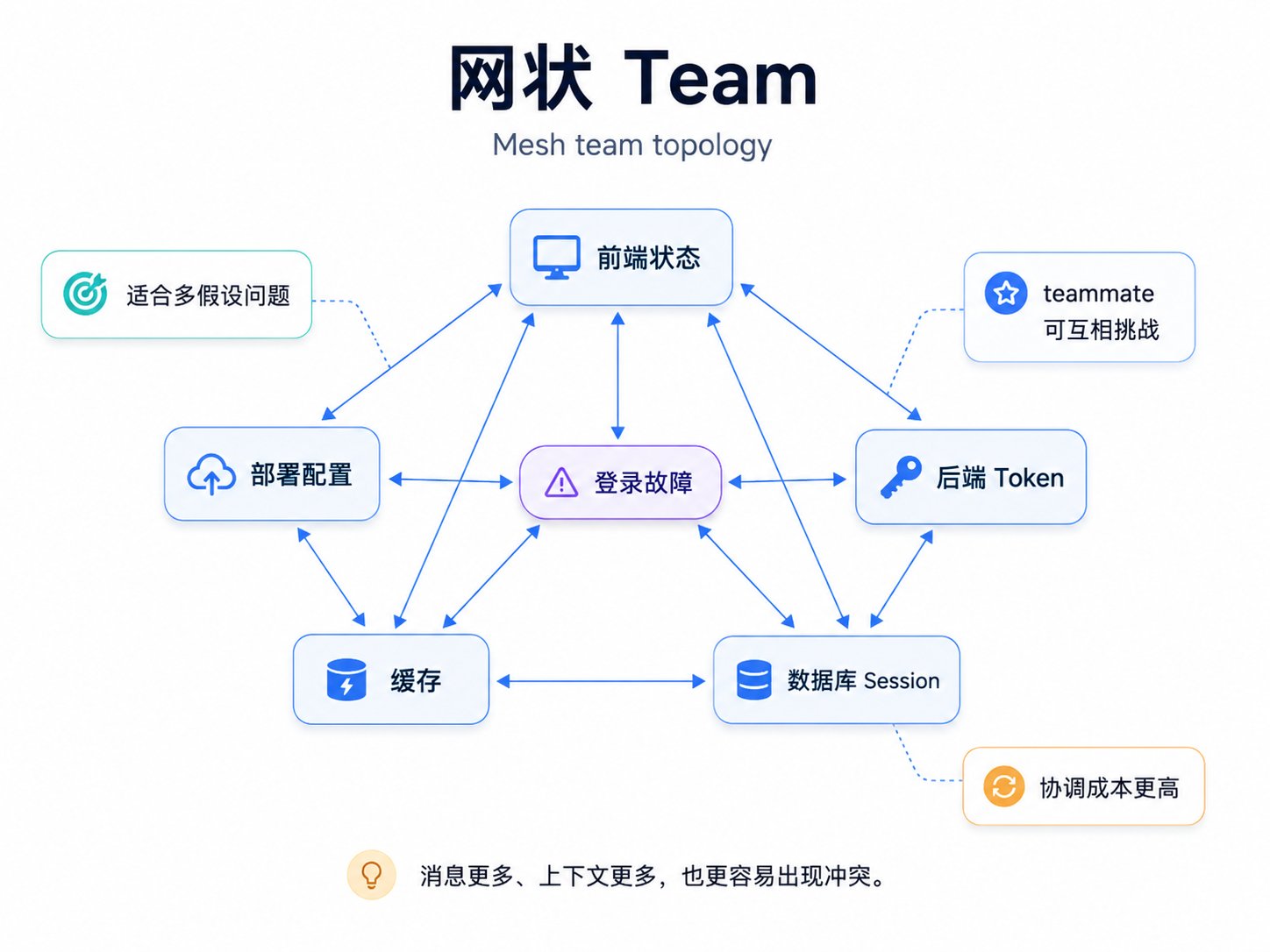
图:网状 team — 多假设并行验证
网状 team 适合多假设问题。比如生产登录故障可能来自前端状态、后端 token、数据库 session、缓存或部署配置,多个 teammate 可以分别验证假设,并互相挑战。网状结构的代价也很直接:消息更多、上下文更多、协调成本更高,写文件冲突也更容易出现。
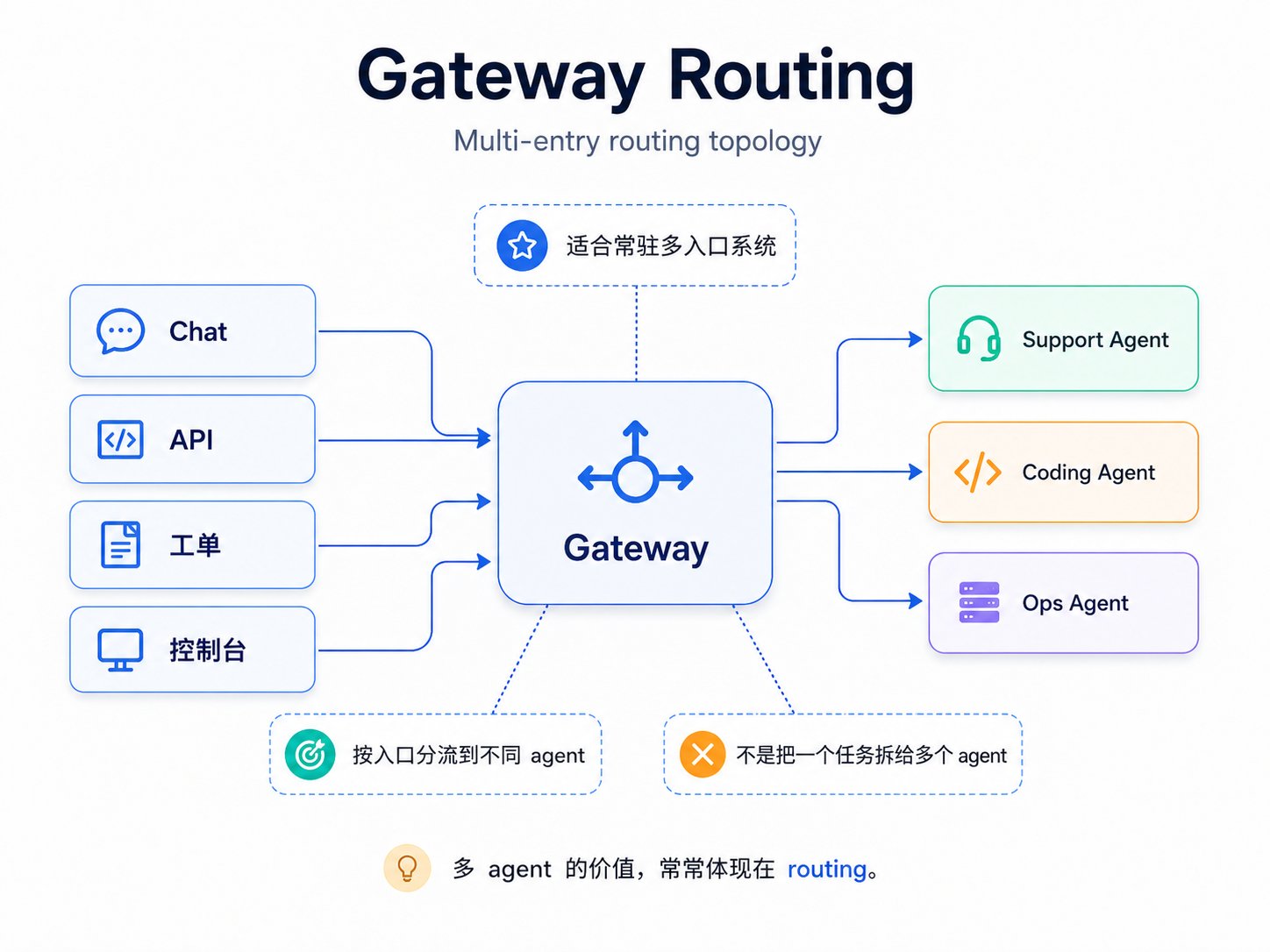
图:Gateway routing — 常驻多入口系统
Gateway routing 适合常驻多入口系统。它不是"一个任务拆给多个 agent",而是"不同入口进入不同 agent"。OpenClaw 的多 agent 价值,很大一部分在这里。
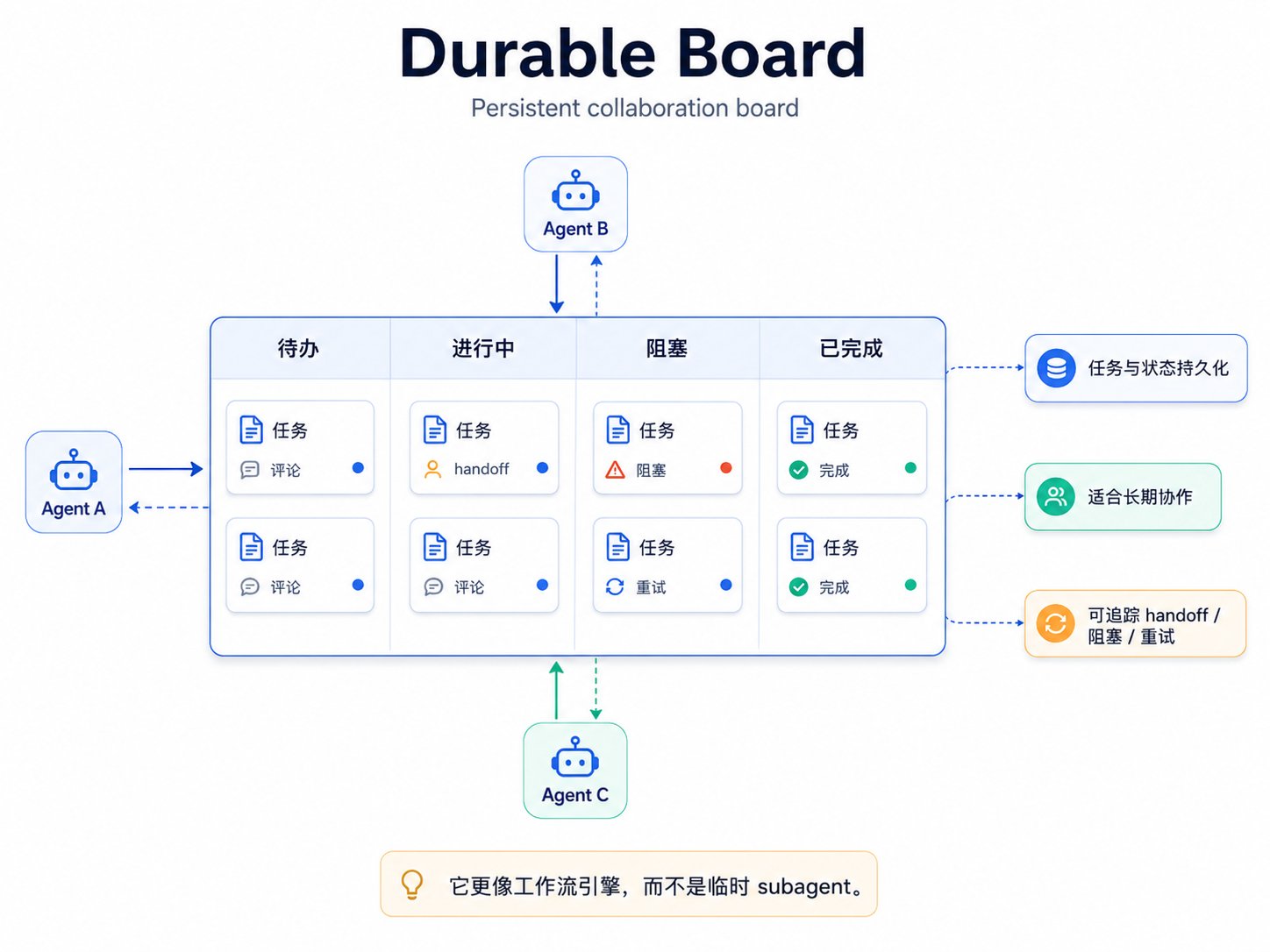
图:Durable board — 长期协作的持久化队列
Durable board 适合长期协作。任务、评论、handoff、阻塞状态、重试记录都落到持久化存储里。
调用链
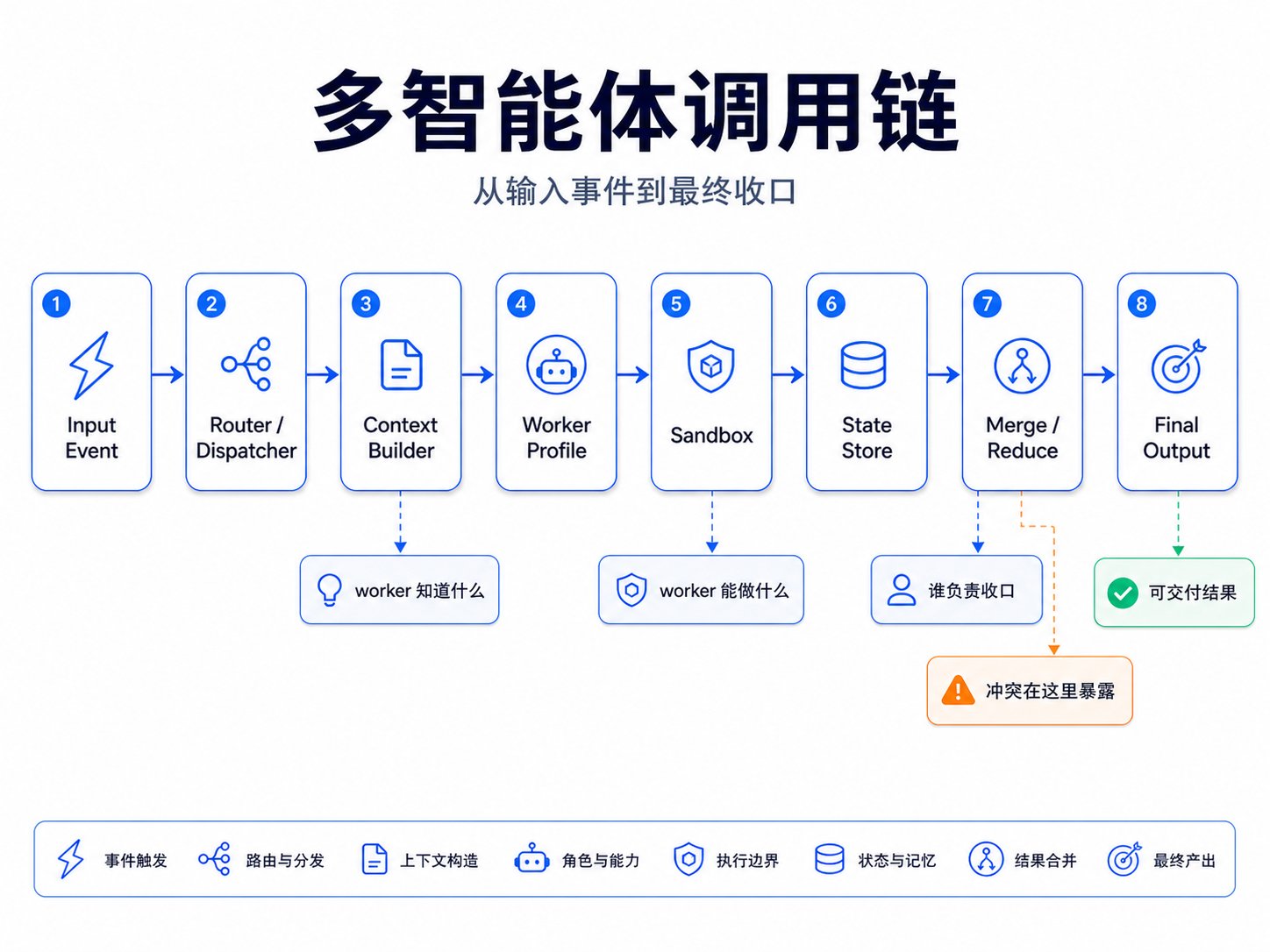
图:多智能体系统的完整调用链
我会把一个多智能体系统拆成下面这条调用链:
input event -> router / dispatcher -> context builder -> worker profile selection -> execution sandbox -> state store -> merge / reduce -> final output or next task
Router / Dispatcher
负责决定是否拆任务,以及拆给谁。Codex 里这个判断主要来自用户显式授权和主 agent,Claude Code 里会受 description 匹配影响,OpenClaw 里很多时候由入口绑定决定,Hermes 里短任务可能由父 agent 调 delegate_task,也可能由模型按任务复杂度自动选择 delegation;长任务则可能由 Kanban dispatcher 按 assignee 拉起 worker。
Context Builder
负责决定 worker 知道什么。子 agent 没有足够上下文,跑偏很正常。你不能把一个 worker 拉进来只说"修一下",然后期待它理解项目路径、错误现场、相关文件、验收标准、禁止事项和输出格式。对 subagent 来说,委派信息就是需求文档。
Worker Profile Selection
决定用什么角色。一般有只读 explorer,能改代码的 worker,security reviewer,test reviewer,有长期 memory 的 profile,一次性 child。角色选错了,后面的权限和输出也会跟着错。
Execution Sandbox
决定 worker 能做什么。它能不能跑 shell?能不能联网?能不能写文件?能不能继续 spawn child?能不能访问用户凭据?这些都不只是安全配置,也会直接改变协作模式。只读 reviewer 和可写 implementer 是两种完全不同的 agent。
State Store
决定状态放在哪里。一次性 subagent 的状态通常只活在本轮任务里,最后返回 summary。OpenClaw 的 agent 有自己的 session store。Hermes Kanban 会把 task、comment、handoff、blocked/retry 状态写进数据库。状态放在哪里,决定了系统能不能跨 turn、跨天、跨重启。
Merge / Reduce
负责收口。多个 worker 给出结果后,谁判断冲突,谁取舍,谁写最终 patch,谁对用户负责?很多多智能体 demo 看起来漂亮,是因为它跳过了 merge 难题。真实工程里,merge 才是多智能体成败的地方。
Cancel / Fail Propagation
最后还要看取消和失败传播。父任务被中断时,子任务要不要一起停?worker 超时怎么办?两个 worker 给出相反结论怎么办?一个 worker 写了错误 patch,另一个 worker 的测试基于这个 patch 继续跑,系统怎么回滚?这些不是模型能力问题,而是运行时设计问题。
Codex:显式 fan-out
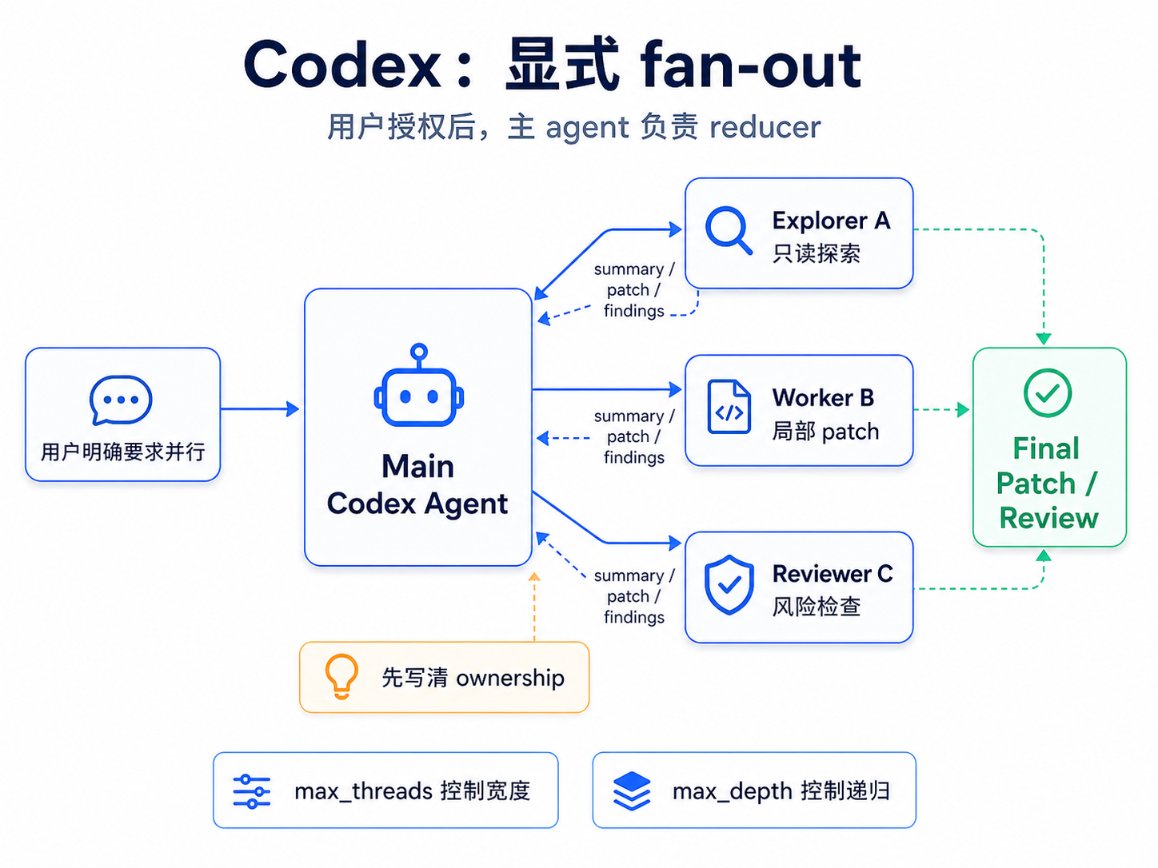
图:Codex 的多 agent 架构
Codex 的 subagent 策略很克制。它默认不会因为任务听起来复杂就自动开一组 agent。你需要明确给出并行授权,比如:
Use parallel subagents. Spawn one agent per review category. Delegate this work in parallel and synthesize the results.
如果你只说"深入分析一下"“彻底 review 一下”“仔细调查这个 bug”,Codex 通常会把它理解成质量要求,而不是多 agent 授权。
这是一个重要的产品取舍:Codex 把 fan-out 的控制权留给用户和主 agent,而不是把复杂度自动翻译成更多 worker。
这个设计背后有几个理由:
- 多开 agent 会增加 token、延迟、日志量和合并成本
- 如果 worker 能写文件,还会带来冲突风险
- 如果子 agent 返回大量解释,主 agent 的 reduce 成本会变高
- 显式授权虽然看起来少了一点"自动",但能把系统行为变得可预测
Codex 的默认拓扑是星型:
main Codex agent -> explorer A: read-only search -> explorer B: trace call path -> worker C: scoped patch -> reviewer D: test and risk review <- summaries / patch / findings main Codex agent reduces result
主 agent 同时扮演 dispatcher 和 reducer。它决定派谁出去,也负责把结果合并成用户能用的回答或补丁。子 agent 的价值不只是"多一个脑子",还有上下文隔离。代码库搜索、长日志、测试输出、调用链探索,都可以放进子上下文里,避免主上下文被噪声污染。
Codex 内置 Agent 类型
Codex 内置 agent 类型可以按责任理解:
- Explorer:适合读代码、找路径、定位调用链、搜相关文件。它最好保持只读,输出文件路径、函数名、关键证据、风险点和下一步建议。explorer 的价值在于减少主上下文探索成本,而不是直接改代码。
- Worker:适合改代码、补测试、实现局部功能。worker 必须有明确 ownership,比如只改 src/auth/,或只负责 tests/auth/。如果两个 worker 都能改同一块逻辑,最后省下的时间很可能会在冲突解决里还回去。
- Default:通用兜底,适合边界还没完全清楚、但需要独立上下文处理的任务。它方便,但也要小心:越通用的 worker,越需要清楚的任务边界。
Codex 支持自定义 agent。团队可以把 TOML 放在 .codex/agents/ 或用户级目录里,配置 description、developer instructions、model、reasoning effort、sandbox、MCP、skills。
Codex 还有两个很关键的护栏:
- agents.max_threads 控制并发宽度
- agents.max_depth 控制递归深度
默认深度通常只允许主 agent 派子 agent,不鼓励子 agent 继续开孙子 agent。
Codex 不适合把所有复杂任务都自动拆开:
- 小修小补不值得 fan-out
- 强顺序任务不适合并行
- 多个 worker 会写同一文件时,需要先串行设计,再并行执行
- 需求还模糊时,多 agent 只会把模糊放大
更稳健的 Codex 委派方式应该像这样:
Use parallel subagents. Explorer A: trace the auth request path from UI to API. Read-only. Explorer B: inspect session persistence and cookie handling. Read-only. Worker C: patch only src/auth/session.ts after A and B report back. Reviewer D: review the final diff and test coverage. Read-only. Main agent must synthesize findings, resolve conflicts, and present one final plan.
Claude Code:description + team
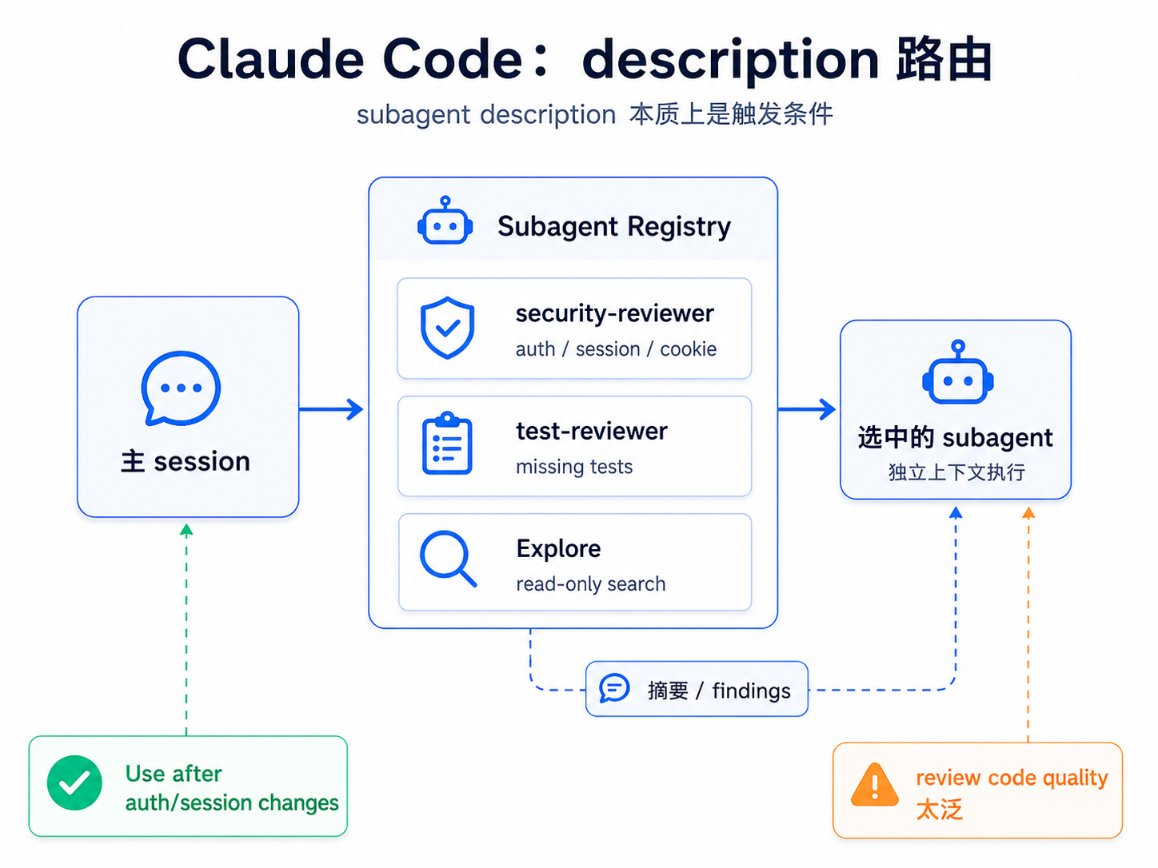
图:Claude Code 的多 agent 架构
Claude Code 的普通 subagent 更像一个本地专家注册表。每个 subagent 有 name、description、system prompt、工具权限、模型和独立上下文。
例如一个安全 reviewer 可以这样写:
name: security-reviewer description: Use proactively after authentication or session code changes to review token handling, cookie flags, expiry, and missing tests. tools: Read, Grep, Glob, Bash model: sonnet
这里的 description 是路由规则。
- 写得具体,Claude 就更容易在合适的时机调用它
- 写得太泛,比如 “review code quality”,它就可能频繁出现,最后变成噪声
普通 subagent 的生命周期比较短。它适合探索、审查、日志分析、局部 debug、代码库理解这类上下文噪声大的工作。
Claude Code 内置的 Explore、Plan、General-purpose 可以理解成三个默认 worker profile:
- Explore:偏只读,适合代码库搜索、路径定位、快速理解
- Plan:适合计划模式里的研究,把探索材料放在子上下文里,避免主上下文膨胀
- General-purpose:更宽,可以处理多步任务,也可能读写文件
这一层和 Codex 的差别在触发门槛。Codex 的问题在于**“用户有没有授权并行”,Claude Code 的问题是"有没有一个 description 匹配当前任务"**。
普通 Claude subagent 仍然是星型:
main Claude session -> Explore -> security-reviewer -> test-reviewer <- summaries main session decides next step
Agent Teams
Agent Teams 是另一套逻辑,目前还是实验功能,默认关闭。启用后,它让一个 lead Claude 带多个 teammate,每个 teammate 有独立上下文,可以互相通信,并共享任务列表。
lead Claude <-> frontend teammate <-> backend teammate <-> database teammate <-> test teammate shared task list direct teammate messages
team 模式适合多假设问题。比如生产登录失败,可能来自前端状态、后端 token、数据库 session、缓存或部署配置。
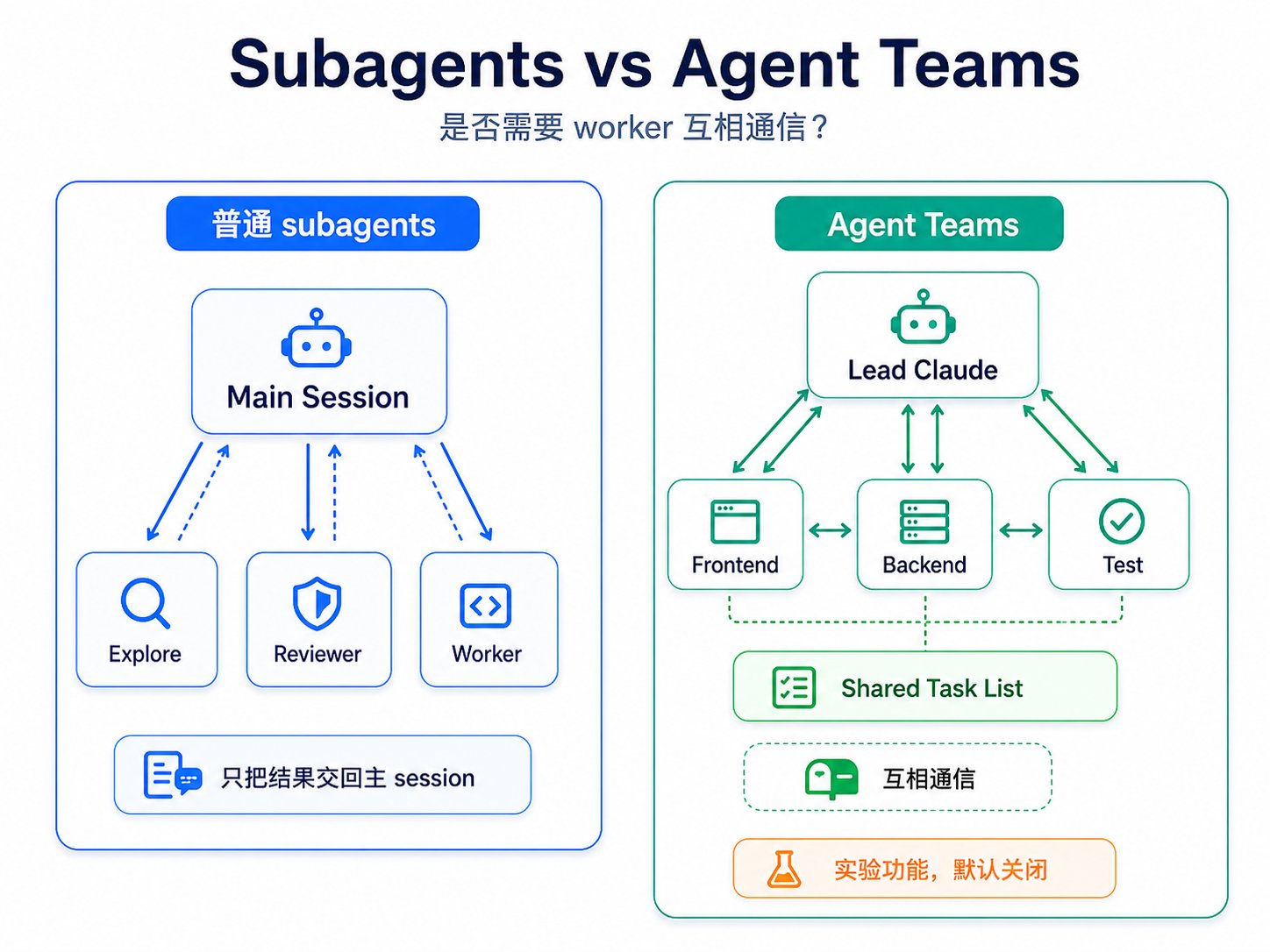
图:Claude Code 的三层架构
但 team 模式的成本也更高。lead 必须有明确收口责任。没有 ownership 的 team,很容易变成"多个 Claude session 同时忙,但没人负责最终结果"。
Claude Code 还有 Agent View、worktrees 和 /batch:
- Agent View:更像人类调度台,可观察、暂停或接管后台 session。
- Worktrees:写代码时的文件隔离手段,让每个 worker 在自己的副本里改,最后再合并。
- /batch:更适合 repo-wide migration 或机械重构,按目录拆成多个 worktree-isolated subagents。
所以 Claude Code 可以分成三层:
Layer 1: 普通 subagent description 自动路由 独立上下文 返回摘要 Layer 2: Agent Teams lead + teammates 共享任务列表 teammate 可互相通信 Layer 3: Agent View / worktrees / batch 人类调度多个 session 用 worktree 隔离写入 适合大规模机械改造
Claude Code 的常见失败点:
- description 太宽,会乱触发
- 工具权限太大,会越界
- team 没有 ownership,会冲突
- batch 没有验收标准,会产生风格不一致的 patch
一个好的 description 应该像触发条件:
Use after auth/session/cookie code changes. Check token handling, cookie flags, expiry, replay risk, and missing tests. Return findings with file paths and severity. Do not modify files.
OpenClaw:Gateway + 后台任务
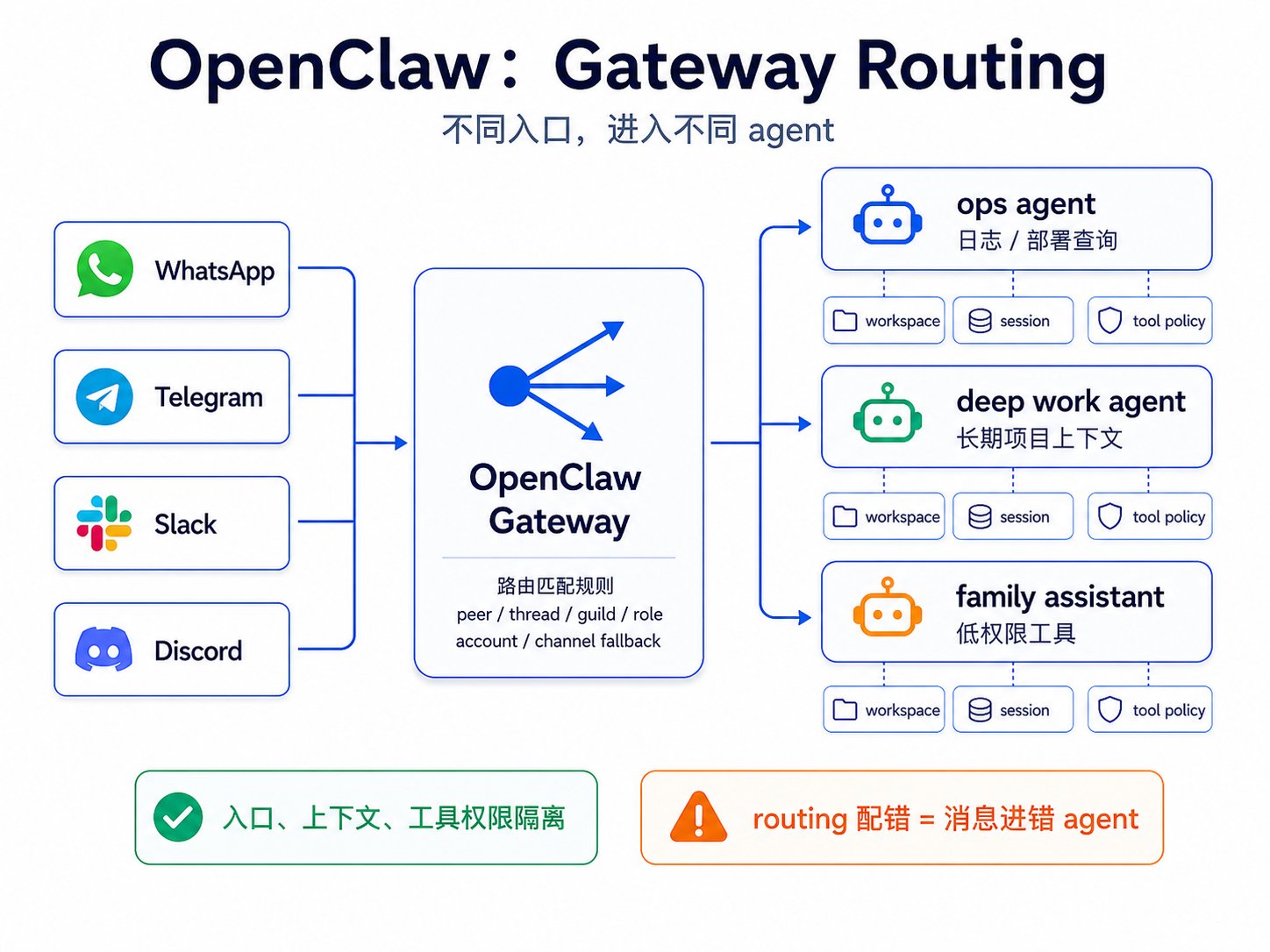
图:OpenClaw 的多 agent 架构
OpenClaw 和 Codex、Claude Code 的出发点不同。Codex 和 Claude Code 多半发生在一个 coding session 里;OpenClaw 先面对的是多渠道事件流。它更像一个 self-hosted Gateway,把 WhatsApp、Telegram、Discord、Slack 等 channel 接到 agent runtime。
在 OpenClaw 里,用户发来的不一定是一个统一的"任务"。不同入口意味着不同身份、不同权限、不同上下文和不同风险。所以 OpenClaw 的第一层不是 subagent,而是 routing。
incoming message -> channel/account/thread/peer matching -> selected agent -> agent workspace + session store -> response or background task
它可以按 peer、thread inheritance、Discord guild / role、Slack team、accountId、channel-level fallback 等规则选择 agent。
OpenClaw 里的 agent 更像隔离运行单元:
- 有自己的 workspace(AGENTS.md、SOUL.md、USER.md 等)
- 有自己的 agentDir(认证信息、模型 registry、per-agent config)
- 有自己的 session store(会话历史和 routing state)
OpenClaw 的多 agent 价值,很大一部分来自隔离。入口身份隔离、上下文隔离、权限隔离、工具隔离,这些都是它的主线。
第二层才是 background subagent。已有 agent 可以通过 /subagents spawn 或 sessions_spawn 拉起后台 agent run。
这和 Codex 的 fan-out 生命周期不同。Codex 的子 agent 更像当前任务里的并行 worker;OpenClaw 的 background subagent 更像异步 job,适合常驻聊天场景。
OpenClaw 也允许嵌套,但默认限制很强。maxSpawnDepth 默认是 1。
第三层是 ACP Agents。OpenClaw 可以把外部 coding harness 接进来,比如 Codex、Claude Code、Cursor、OpenCode、Gemini CLI。
OpenClaw 可以按三层理解:
Routing layer: channel/account/thread/peer -> agent Agent isolation layer: workspace / agentDir / session store / sandbox / tool policy Execution layer: native background subagent or external ACP harness
OpenClaw 容易出问题的地方:
- routing 配错,消息会进错 agent
- 权限策略太宽,低风险入口可能拿到危险工具
- session store 设计不清,上下文互相污染
- background job 太多,造成并发和成本压力
- ACP harness 调度不清
所以 OpenClaw 的工程重点不是"怎么让几个 agent 一起思考",而是"怎么让不同入口、不同身份、不同权限的 agent 网络长期稳定运行"。
Hermes:短任务 RPC,长任务 durable queue
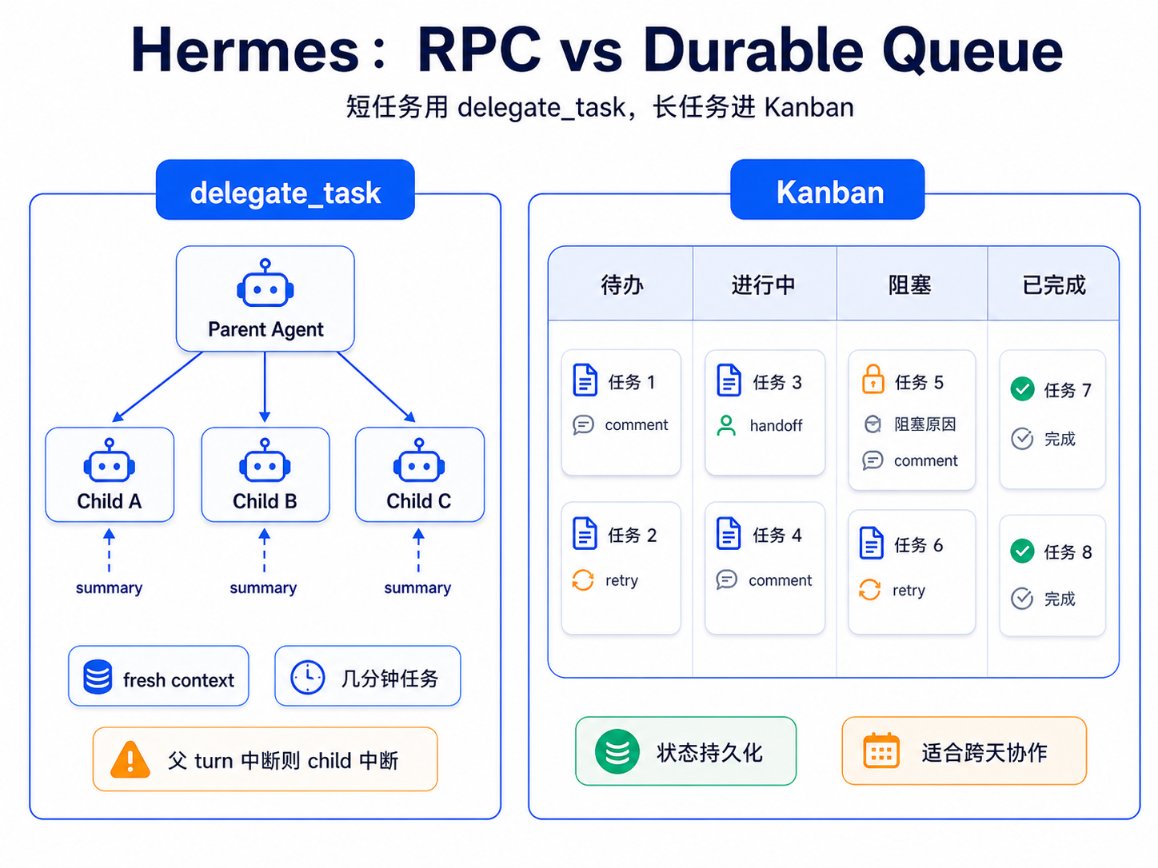
图:Hermes Agent 的架构
Hermes Agent 的设计很工程化,因为它把短程并行和长期协作拆成两个原语:
Delegate_task:短程并行
delegate_task 处理短程并行。父 agent 发起调用,child agent 执行,最后返回 summary。这很像 RPC。
parent agent -> delegate_task(goal, context) -> child A -> child B -> child C <- ordered summaries parent continues
Hermes 文档里那句 “subagents know nothing” 很关键。它把多智能体委派里最常见的坑讲透了:子 agent 不会自动知道背景。父 agent 必须把项目路径、错误信息、相关文件、任务目标、验收标准、禁止事项和输出格式写进去。
Hermes 对 delegate_task 的限制:
- 默认最多 3 个并发 child,超过就报错
- batch 结果按输入顺序返回
- 父 turn 被 interrupt 时,活跃 child 会一起中断
- 默认 leaf subagent 不能再 delegate
- 限制 leaf 工具:不能 delegate_task、不能 clarify、不能写 shared memory、不能跨平台发消息
Kanban:持久队列
Kanban 处理另一类任务。它不是 subagent,而是 durable queue 加 state machine。任务、handoff、comment 写进 SQLite task board。
delegate_task 和 Kanban 的差别:
delegate_task: 临时 child 父 agent 等结果 状态主要在本轮调用里 适合几十秒到几分钟的并行研究、检查、局部修复 Kanban: 持久 task worker profile 接力 状态在 board 里 适合跨 turn、跨天、等待人类、失败重试、审计
**举个例子:**你要让三个 researcher 分别查三个资料源,然后汇总成一段结论,用 delegate_task 很合适。你要做一篇两天的调研报告,先抓资料,再分析,再写稿,再审校,那就应该进 Kanban。
Hermes 容易失败的点,是把两类任务混用。
Hermes 的工程价值在于它把生命周期讲清楚了。一次性并行和持久协作不是同一种东西。前者需要 fork/join,后者需要队列、状态、重试、评论、handoff 和审计轨迹。
用几个具体场景看
场景一:PR Review
Codex 或 Claude Code 普通 subagent 都够。安全、测试、性能各开一个只读 worker,最后主 agent 汇总。
用 Codex 时,可以显式说:
Use three read-only subagents: security, tests, and maintainability. Each should return findings with file paths and severity. Do not modify files. Main agent synthesizes one review.
场景二:生产登录故障
适合 team 或至少并行探索。故障可能在前端状态、token 签发、session 存储、缓存、部署配置。
多 agent 的第一阶段应该扩大观察面,不应该急着扩大写入面。
场景三:多渠道个人助理
Codex 或 Claude Code 不适合。OpenClaw 更适合。需要 routing、入口身份隔离、权限隔离和 session store。
一个合理设计可能是:
- Slack ops channel ➜ ops agent(日志读取和低风险部署查询)
- 私人 Telegram ➜ deep work agent(个人项目上下文)
- 家庭入口 ➜ low-privilege assistant(无 shell 和公司账号)
场景四:两天的调研报告
一次性 subagent 不够。Hermes Kanban 这类 durable board 更合适。
Kanban 管生命周期,delegate_task 管局部并行。把这两层分清,系统才不会又笨重又丢状态。
场景五:Repo-wide Migration
适合 worktree + batch。按目录或模块拆,不要按"让几个 agent 自己商量"拆。
反模式:多 Agent 最容易坏在哪里
- 把复杂度当触发器:任务复杂不等于应该并行。如果子任务之间强依赖,那就是 pipeline,不是 fan-out。
- 不给 delegation contract:worker 拿不到路径、错误现场、验收标准和禁止事项,只能猜。
- 让多个 worker 写同一片代码:多 agent 最怕"并行写入但没有 ownership"。
- 没有 reducer:多个 agent 返回结果之后,需要有人做取舍、合并、去重、排序、验收。
- 把短任务做成队列,把长任务做成 RPC:短任务上 durable board 会拖慢反馈;长任务用一次性 subagent 会丢状态。
- 权限过宽:一个 review agent 不该有写文件权限;一个家庭入口 agent 不该有公司 shell;一个 leaf worker 不一定需要继续 spawn child。
- 没有观测和审计:多 agent 系统需要知道谁触发了谁,传了什么 context,用了什么工具,返回了什么 summary,失败在哪里。
选择顺序

图:多智能体设计的选择顺序
做多智能体设计时,可以按这个顺序问:
- 单 agent 能不能做。能做就先别拆。小改动、强顺序、需求还模糊的时候,单 agent 最稳。
- 主上下文会不会被污染。长日志、大搜索、跨目录阅读、多个失败栈,会让主 agent 变浑。把这些丢给 explorer 或只读 subagent 很合理。
- 子任务能不能独立。安全 review、测试 review、性能 review 可以并行;先定位 bug 再决定怎么修,更适合 pipeline。
- 结果是否必须在本轮返回。必须本轮返回,用 fork/join;不必本轮返回,可以用 background job;需要跨天、重试、等待人类,用 durable queue 或 Kanban。
- worker 是否需要互相挑战。只需要分头查资料,星型足够;需要互相质疑和共享任务状态,再考虑 team mesh。
- 是否会并行写文件。只要多个 worker 会写文件,就先写 ownership。谁改哪个目录,谁只读,谁最后合并,没有这些约束就不要并行写。
- 是否需要入口隔离。多渠道、多身份、多权限的系统,优先考虑 Gateway routing,而不是把所有消息丢给一个万能 agent。
- 失败后如何恢复。能不能 retry?能不能 block?能不能保留 handoff?能不能看见子任务的证据?这些决定了系统能不能长期运行。
Delegation Contract 模板
如果只想拿走一个实践模板,可以用下面这个。它适用于 Codex、Claude Code、Hermes,也适用于任何需要委派 worker 的系统。
Role: 你是 read-only auth explorer / scoped implementation worker / security reviewer。 Goal: 你要回答或完成什么,边界是什么。 Context: 项目路径、相关文件、错误信息、用户目标、已有判断。 Allowed actions: 能读哪些文件,能不能跑命令,能不能写文件,能不能联网。 Ownership: 如果能写,只能写哪些目录或文件。 Forbidden actions: 不要改哪些文件,不要做哪些重构,不要问用户,不要继续 spawn child。 Output format: 返回 findings / patch summary / test result / confidence / open questions。 Stop condition: 什么情况下算完成,什么情况下应该停止并报告阻塞。
这个模板看起来朴素,但它解决的是多 agent 的基本问题:上下文、权限、边界、输出和收口。没有这些,再高级的拓扑都会变成随机并行。
结论
多智能体协作不是越多越好,也不是越自动越好。
工程上更稳健的顺序是:
- 先决定调度方式,再决定状态放哪里
- 先决定上下文和权限边界,再决定拓扑
- 先决定谁 reduce,再决定开几个 worker
| 框架 | 适合场景 | 核心模式 |
|---|---|---|
| Codex | 显式、可控的星型并行 | 显式 Fan-out |
| Claude Code | Description 驱动的专家委派 | Description + Team + Worktree |
| OpenClaw | 多入口、常驻、带权限隔离的 Agent 网络 | Gateway Routing + Background Subagent |
| Hermes | 短程并行和长期队列分离 | Delegate_task + Kanban |
- 如果一个任务只是需要更快地查四条线,用星型 subagents。
- 如果一个问题需要多方互相挑战,用 team mesh。
- 如果消息来自不同渠道和身份,用 Gateway routing。
- 如果任务要跨天、重试、等待人类,用 durable board。
- 如果多个 worker 会写同一片代码,先停下来,把 ownership 写清楚。
先设计边界,再增加 agent 数量。
这个顺序不会显得炫,但它更接近真实工程。