
LlamaIndex 核心概念:索引类型、检索策略与查询引擎全解析
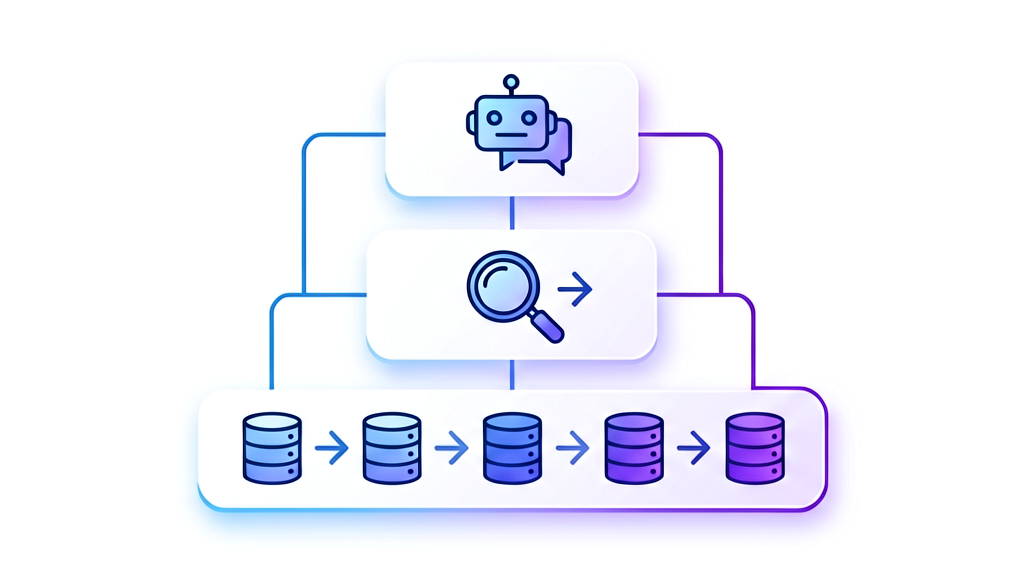
这三个概念在LlamaIndex中扮演不同角色,共同构成RAG(检索增强生成)流程的核心链条:索引是数据的结构化存储形式 → 检索策略是从索引中查找相关内容的方法 → 查询引擎是封装检索与生成的完整问答接口。
一、Index(索引):数据的结构化存储形态
定义:索引是将原始文档(Documents)切分为节点(Nodes)后,构建的优化数据结构,目的是让后续检索更高效、更精准。它是数据的“结构化容器”,决定了数据如何被组织和存储。
常见索引类型及特点
| 索引类型 | 核心结构 | 适用场景 | 检索方式 | 优缺点 |
|---|---|---|---|---|
| VectorStoreIndex(最常用) | 向量数据库存储文本嵌入向量 | 通用问答、语义搜索 | 向量相似度匹配(Top-k) | 语义理解强、扩展性好;需Embedding成本 |
| SummaryIndex(原ListIndex) | 线性列表 | 小数据集、全文总结 | 顺序遍历或全量输入 | 不遗漏信息;大规模数据效率低、Token消耗大 |
| TreeIndex | 树形层次结构 | 长文档摘要、多文档汇总 | 从根节点向下遍历,逐层摘要 | 适合结构化回答;构建成本高 |
| KeywordTableIndex | 关键词倒排索引 | 精准关键词匹配(如产品型号) | 关键词匹配 | 检索速度最快;语义理解弱 |
| KnowledgeGraphIndex | 图结构(实体-关系) | 关系推理、知识图谱 | 实体关系遍历 | 擅长复杂关系查询;构建复杂 |
| MultiModalVectorStoreIndex | 多模态向量存储 | 文本+图像跨模态检索 | 跨模态向量匹配 | 支持多模态数据;需多模态Embedding模型 |
核心作用:将非结构化数据转化为机器可高效检索的结构化形式,是检索的基础。
二、Retrieval Strategy(检索策略):从索引中找答案的方法
定义:检索策略是从索引中筛选与查询最相关节点的算法或规则,决定了如何“搜索”数据。它是索引与查询引擎之间的“桥梁”,定义了检索的逻辑和方式。
常见检索策略及特点
| 策略类型 | 实现方式 | 适用场景 | 优势 |
|---|---|---|---|
| 语义检索(Semantic Retrieval) | 计算查询向量与索引向量的余弦相似度,取Top-k | 通用问答、模糊匹配 | 理解语义,不依赖关键词完全匹配 |
| 关键词检索(Keyword Retrieval) | 基于TF-IDF等算法匹配关键词 | 精确查询、特定术语 | 速度快、准确性高(特定场景) |
| 混合检索(Hybrid Retrieval) | 结合语义检索与关键词检索(AND/OR逻辑) | 复杂查询、提高召回率 | 兼顾语义理解与精确匹配 |
| 分层检索(Hierarchical Retrieval) | 先检索上层摘要,再定位下层细节 | 长文档、大规模知识库 | 平衡效率与准确性 |
| 路由检索(Router Retrieval) | 分类器判断查询类型,路由到对应索引/检索器 | 多数据源、混合索引 | 智能选择最优检索路径 |
| 句子窗口检索(Sentence Window Retrieval) | 检索目标句子及其上下文窗口 | 提高答案准确性 | 保留语境,减少信息丢失 |
核心作用:根据查询意图,从索引中高效筛选出最相关的上下文,为后续生成答案提供素材。
三、Query Engine(查询引擎):完整的问答接口
定义:查询引擎是封装了检索、后处理和生成的高级接口,接收自然语言查询,返回最终答案。它是用户与系统交互的“入口”,隐藏了底层复杂的检索和生成逻辑。
常见查询引擎类型及特点
| 引擎类型 | 核心功能 | 适用场景 | 工作流程 |
|---|---|---|---|
| RetrieverQueryEngine(基础) | 检索+生成 | 通用问答 | 检索→后处理→提示词构建→LLM生成 |
| SQLQueryEngine | 文本转SQL查询 | 结构化数据库 | 解析查询→生成SQL→执行查询→格式化结果 |
| SubQuestionQueryEngine | 复杂问题拆解为子问题 | 多文档复杂查询 | 问题拆解→并行查询→结果汇总 |
| RouterQueryEngine | 多引擎路由 | 混合数据源 | 意图识别→路由到对应引擎→整合结果 |
| ChatQueryEngine | 会话式问答 | 多轮对话 | 保留对话历史→上下文感知检索→生成回复 |
核心作用:提供一站式问答服务,将检索到的上下文与LLM结合,生成准确、自然的答案。
四、三者关系与工作流程
1. 核心关系图
原始数据 → [Index构建] → 索引(数据结构)→ [Retrieval策略] → 相关节点 → [Query Engine] → 最终答案
2. 典型工作流程(以VectorStoreIndex为例)
- 数据准备:加载文档→切分为节点→生成Embedding向量
- 索引构建:创建VectorStoreIndex,将向量存储到向量数据库
- 检索阶段:用户查询→生成查询向量→使用语义检索策略(Top-k)找到最相关节点
- 生成阶段:查询引擎将检索结果与查询结合,构建提示词→调用LLM生成答案
3. 关键区别总结
| 维度 | Index(索引) | Retrieval(检索策略) | Query Engine(查询引擎) |
|---|---|---|---|
| 本质 | 数据结构/存储形式 | 搜索算法/规则 | 完整问答接口 |
| 作用 | 组织数据以便高效检索 | 筛选与查询最相关内容 | 接收查询→返回最终答案 |
| 关注点 | 数据如何存储 | 如何找到相关数据 | 如何生成高质量答案 |
| 可配置性 | 选择不同索引类型适配数据 | 调整检索参数(如Top-k) | 自定义提示词、后处理等 |
五、实操示例:三者的代码体现
# 1. 构建索引(Index)
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents) # 选择VectorStoreIndex类型
# 2. 配置检索策略(Retrieval)
retriever = index.as_retriever(
similarity_top_k=5, # 语义检索策略,返回Top-5相似结果
# 可添加其他策略,如混合检索
)
# 3. 创建查询引擎(Query Engine)
query_engine = index.as_query_engine(
retriever=retriever, # 指定检索策略
# 可添加后处理、提示词模板等配置
)
# 4. 执行查询
response = query_engine.query("LlamaIndex的核心概念有哪些?")
print(response)
总结
- 索引决定了数据的“存储形态”,是检索的基础
- 检索策略决定了“如何查找”数据,是连接索引与答案的桥梁
- 查询引擎则是“完整的问答服务”,封装了所有底层逻辑,为用户提供简洁接口
理解这三者的区别,有助于你根据不同场景选择合适的组合,构建高效、准确的RAG应用。