

OpenClaw 核心原理深度解析:Agent运行时与记忆系统内部实现
面向读者:本文假设你了解 TypeScript 基础语法和 LLM 的基本概念(Token、System Prompt、Tool Call),但不需要你读过 OpenClaw 源码。我们会从最核心的代码逐行分析,配合类比和图解,让新手也能看懂。
前言:为什么要从架构师视角看 OpenClaw
大多数 Agent 框架的技术文章止步于"它做了什么"——列出模块、展示代码、描述流程。但真正值得理解的是它为什么这样做。每一个设计决策背后,都有被权衡过的替代方案、被妥协过的理想目标、被防御过的故障模式。
OpenClaw 的 Agent 运行时与记忆系统,其源码分布跨越 packages/agent-core(通用核心)、src/agents(运行时扩展)、src/context-engine(上下文引擎)、src/memory(工作区记忆)四大模块。本文不打算做源码导读,而是从架构师的视角,揭示这些模块背后的设计原理、概念模型与权衡哲学。
为了让新手也能跟上,每章开头会用生活化的类比引入问题,然后用实际源码佐证分析。
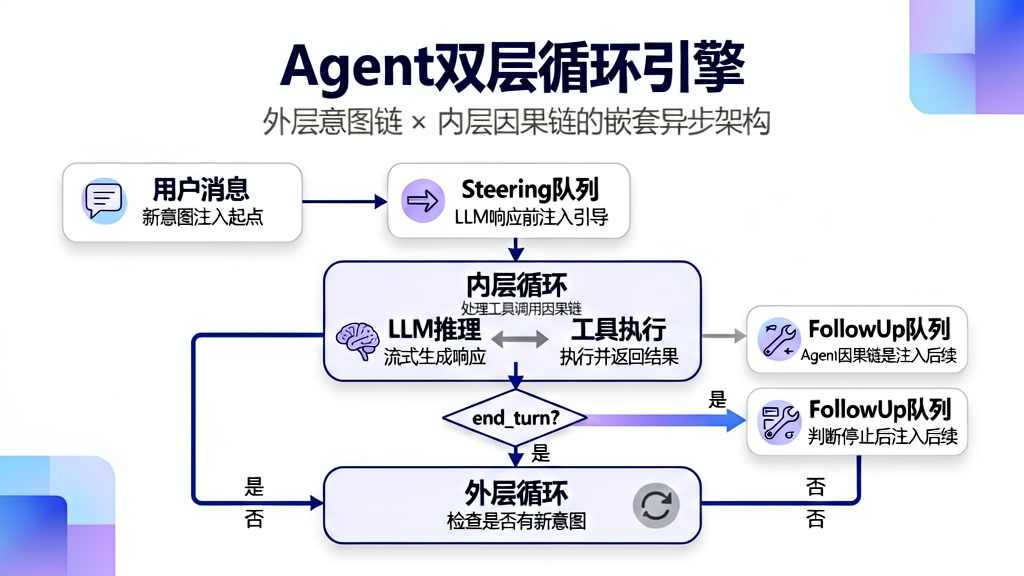
第一章 双层循环引擎:为什么 Agent Loop 不是单层循环
1.1 问题本质:Agent 的"思考"是一个嵌套的异步过程
生活类比:想象你在厨房做饭(Agent),你有一个任务清单(用户消息)。
- 内层循环:你决定做番茄炒蛋 → 发现没番茄 → 去超市买番茄 → 回来继续做 → 发现蛋不够 → 再去买蛋。这是一个因果链,每一步的结果决定了下一步做什么。
- 外层循环:番茄炒蛋做完了 → 你又想做汤 → 开始新的因果链。这是意图链,多个互不依赖的任务串行执行。
这两个层次的终止条件完全不同:
- 工具链在 LLM 输出
end_turn时终止(菜做完了) - 意图延续在队列为空时终止(所有菜都做完了)
如果把它们混在一个循环里,代码会变成一团浆糊——需要在循环体内写大量条件分支来区分"工具链中间插入新消息"和"工具链结束后处理新消息"。
源码验证:打开 packages/agent-core/src/agent-loop.ts 第 258 行的 runLoop 函数:
async function runLoop(
initialContext: AgentContext,
newMessages: AgentMessage[],
initialConfig: AgentLoopConfig,
signal: AbortSignal | undefined,
emit: AgentEventSink,
streamFn?: StreamFn,
runtime?: AgentCoreStreamRuntimeDeps,
): Promise<void> {
let currentContext = initialContext;
let config = initialConfig;
let firstTurn = true;
// 外层循环开始前,先检查是否有 steering 消息
let pendingMessages: AgentMessage[] = (await config.getSteeringMessages?.()) || [];
// ---- 外层循环:处理意图链 ----
while (true) {
let hasMoreToolCalls = true;
// ---- 内层循环:处理因果链(工具调用链)----
while (hasMoreToolCalls || pendingMessages.length > 0) {
// ... 处理 pendingMessages、调用 LLM、执行工具 ...
}
// 内层循环结束后,检查是否有 follow-up 消息
const followUpMessages = (await config.getFollowUpMessages?.()) || [];
if (followUpMessages.length > 0) {
// 有后续消息,重新进入内层循环
pendingMessages = followUpMessages;
continue; // 关键:continue 回到外层循环顶部,开启新轮次
}
break; // 没有更多消息,退出外层循环
}
}
注意代码中两层 while 的嵌套关系:外层 while(true) 控制意图切换,内层 while 控制工具调用链。当内层退出后,外层检查 followUpQueue,如果有新消息就 continue 重新开启内层循环。
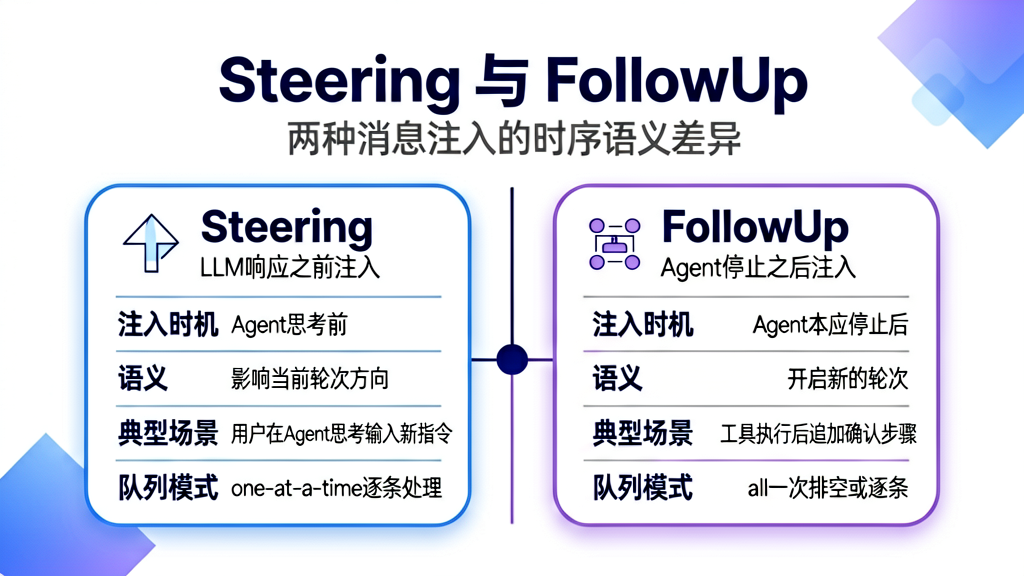
1.2 Steering 与 FollowUp:两种消息注入的时序语义
Agent 运行时有两个消息队列:
| 队列 | 注入时机 | 语义 | 生活类比 |
|---|---|---|---|
steeringQueue |
LLM 响应之前 | “在 Agent 开始下一轮思考之前,先看看有没有新的引导信息” | 你在做饭时,家人说"记得少放盐"——在你下盐之前就听到了 |
followUpQueue |
Agent 本应停止之后 | “Agent 认为任务完成了,但还有后续工作要做” | 你做完饭准备休息,系统说"等等,碗还没洗" |
源码验证:在 packages/agent-core/src/agent.ts 的 Agent 类中:
private readonly steeringQueue: PendingMessageQueue;
private readonly followUpQueue: PendingMessageQueue;
// 构造函数中初始化
constructor(options: AgentOptions = {}) {
this.steeringQueue = new PendingMessageQueue(options.steeringMode ?? "one-at-a-time");
this.followUpQueue = new PendingMessageQueue(options.followUpMode ?? "one-at-a-time");
}
// 注入 steer 消息
steer(message: AgentMessage): void {
this.steeringQueue.enqueue(message);
}
// 注入 followUp 消息
followUp(message: AgentMessage): void {
this.followUpQueue.enqueue(message);
}
而这两个队列的消费方式,是在 createLoopConfig 中作为 getSteeringMessages 和 getFollowUpMessages 传入 runLoop:
getSteeringMessages: async () => {
// 首次轮次跳过 steering 检查(第一次应该是处理用户输入的 prompt)
if (skipInitialSteeringPoll) {
skipInitialSteeringPoll = false;
return [];
}
return this.steeringQueue.drain();
},
getFollowUpMessages: async () => this.followUpQueue.drain(),
QueueMode 的两种排空模式:PendingMessageQueue 的 drain 方法有两种模式:
drain(): AgentMessage[] {
if (this.mode === "all") {
const drained = this.messages.slice();
this.messages = [];
return drained; // 一次排空所有消息
}
// one-at-a-time: 每次只取第一条,剩下的留到后续轮次
const first = this.messages[0];
if (!first) return [];
this.messages = this.messages.slice(1);
return [first];
}
"one-at-a-time" 的设计动机是防止消息堆积导致上下文膨胀——如果一次注入 10 条消息,LLM 的上下文窗口可能瞬间溢出。而逐条处理可以让 Agent 在每条消息后重新评估是否需要继续。
1.3 事件流:为什么 Agent Loop 不直接返回结果
初学者问题:为什么 agentLoop 函数不直接返回 AgentMessage[],而是返回一个 EventStream?
答案:因为 Agent 的执行是增量产出的。如果等整个循环结束才返回结果,调用者就无法实现:
- 流式输出(一边生成文字一边显示)
- 工具执行进度(实时看到工具调用状态)
- 中途取消(用户按了取消按钮)
源码验证(agent-loop.ts 第 87 行):
export function agentLoop(
prompts: AgentMessage[],
context: AgentContext,
config: AgentLoopConfig,
signal?: AbortSignal,
streamFn?: StreamFn,
runtime?: AgentCoreStreamRuntimeDeps,
): EventStream<AgentEvent, AgentMessage[]> {
const stream = createAgentStream();
// 异步执行,但立即返回 stream
void runAgentLoop(prompts, context, config, async (event) => {
stream.push(event); // 每产生一个事件就推入 stream
}, signal, streamFn, runtime)
.then((messages) => {
stream.end(messages); // 完成后结束 stream,附带最终结果
})
.catch((error: unknown) => {
pushLoopFailure(stream, config, error, signal?.aborted === true);
});
return stream; // 立即返回,不等待执行完毕
}
EventStream 的设计借鉴了 ReactiveX 的思想:将异步过程建模为事件序列,而不是一次性结果。调用者可以订阅事件流,在 agent_start 时显示"Agent 开始思考",在 message_update 时追加流式文字,在 tool_execution_start 时显示"正在调用工具X"。
AgentEvent 的事件类型(types.ts 第 504 行):
export type AgentEvent =
| { type: "agent_start" }
| { type: "agent_end"; messages: AgentMessage[] }
| { type: "turn_start" }
| { type: "turn_end"; message: AgentMessage; toolResults: ToolResultMessage[] }
| { type: "message_start"; message: AgentMessage }
| { type: "message_update"; message: AgentMessage; ... }
| { type: "message_end"; message: AgentMessage }
| { type: "tool_execution_start"; toolCallId: string; toolName: string; args: unknown }
| { type: "tool_execution_update"; ... }
| { type: "tool_execution_end"; ... };
整个事件生命周期是:agent_start → turn_start → message_start → message_update×N → message_end → tool_execution_start → … → turn_end → … → agent_end。
1.4 prepareNextTurn:运行时模型切换的架构意义
内层循环的 prepareNextTurn 钩子允许在每个轮次之间动态切换模型和推理级别。
生活类比:写论文时,先用 GPT-4 做推理(需要高智商),然后用 GPT-3.5 写摘要(够用了),最后用专用模型做格式检查。不同阶段用不同的"大脑"。
源码验证(agent-loop.ts 第 342-358 行):
const nextTurnSnapshot = await config.prepareNextTurn?.(nextTurnContext);
if (nextTurnSnapshot) {
currentContext = nextTurnSnapshot.context ?? currentContext;
const nextModel = nextTurnSnapshot.model ?? config.model;
const nextThinkingLevel = nextTurnSnapshot.thinkingLevel ?? config.thinkingLevel;
config = Object.assign({}, config, {
model: nextModel,
thinkingLevel: nextThinkingLevel,
reasoning: nextReasoning,
});
}
这里的 Object.assign({}, config, ...) 创建了新配置对象,而不是修改原对象——再次体现了不可变性原则。
1.5 两种循环入口的设计意图
Agent Loop 提供两种入口:
| 入口函数 | 用途 | 前置校验 |
|---|---|---|
agentLoop |
从新的用户消息开始 | 无(新消息总是 user 角色) |
agentLoopContinue |
从当前上下文继续(重试) | 最后一条消息不能是 assistant |
为什么 agentLoopContinue 要校验最后一条消息不能是 assistant?因为 LLM 的对话格式要求:消息轮次必须是 user/assistant/toolResult 交替。如果最后一条是 assistant,LLM API 会拒绝请求。
export function agentLoopContinue(...): EventStream<...> {
if (context.messages.length === 0) {
throw new Error("Cannot continue: no messages in context");
}
if (context.messages[context.messages.length - 1].role === "assistant") {
throw new Error("Cannot continue from message role: assistant");
}
// ...
}
而 Agent.continue() 方法的逻辑更复杂一些:如果最后一条是 assistant,它不会直接报错,而是先尝试处理队列中的消息:
async continue(): Promise<void> {
const lastMessage = this.mutableState.messages[this.mutableState.messages.length - 1];
if (lastMessage.role === "assistant") {
const queuedSteering = this.steeringQueue.drain();
if (queuedSteering.length > 0) {
await this.runPromptMessages(queuedSteering, { skipInitialSteeringPoll: true });
return;
}
const queuedFollowUps = this.followUpQueue.drain();
if (queuedFollowUps.length > 0) {
await this.runPromptMessages(queuedFollowUps);
return;
}
throw new Error("Cannot continue from message role: assistant");
}
await this.runContinuation();
}
这是优雅降级的典型:先尝试通过队列消息来"消费"掉 assistant 消息,如果队列为空才报错。
第二章 Agent 状态机:防御性拷贝与不可变视图
2.1 状态的"写时拷贝"哲学
新手理解:想象你在写一份共享文档。如果别人直接修改了你正在看的那一页,你的视图就会混乱。所以 OpenClaw 的做法是:每次写入都创建一个新副本,保证其他人持有的引用不会突然改变。
源码验证(agent.ts 第 72-101 行 createMutableAgentState):
function createMutableAgentState(
initialState?: Partial<Omit<AgentState, "pendingToolCalls" | "isStreaming" | "streamingMessage" | "errorMessage">>,
): MutableAgentState {
let tools = initialState?.tools?.slice() ?? []; // 注意 .slice()!
let messages = initialState?.messages?.slice() ?? []; // 注意 .slice()!
return {
get tools() { return tools; },
set tools(nextTools: AgentTool[]) {
tools = nextTools.slice(); // 每次 set 都 .slice() 创建新数组
},
get messages() { return messages; },
set messages(nextMessages: AgentMessage[]) {
messages = nextMessages.slice(); // 每次 set 都 .slice() 创建新数组
},
// ...
};
}
为什么用 .slice()?因为 JavaScript 中数组是引用类型。如果没有 .slice():
const myTools = agent.state.tools;
myTools.push(newTool); // ❌ 直接修改了内部数组!
Agent 的运行时是一个高度并发的异步环境,如果外部代码持有对内部数组的引用并直接修改,就会产生难以追踪的竞态条件。用微小的内存开销换取状态一致性保证——这是典型的防御性编程。
另外注意 createContextSnapshot 方法也做了同样的保护:
private createContextSnapshot(): AgentContext {
return {
systemPrompt: this.mutableState.systemPrompt,
messages: this.mutableState.messages.slice(), // 拷贝
tools: this.mutableState.tools.slice(), // 拷贝
};
}
2.2 Agent 事件处理的"先减后播"模式
核心源码(agent.ts 第 568 行 processEvents):
private async processEvents(event: AgentEvent): Promise<void> {
// 第一步:根据事件类型更新内部状态
switch (event.type) {
case "agent_start":
case "turn_start":
case "tool_execution_update":
break; // 这些事件不需要更新状态
case "message_start":
this.mutableState.streamingMessage = event.message;
break;
case "message_end":
this.mutableState.streamingMessage = undefined;
this.mutableState.messages.push(event.message); // 消息正式加入历史
break;
case "tool_execution_start":
const pendingToolCalls = new Set(this.mutableState.pendingToolCalls);
pendingToolCalls.add(event.toolCallId);
this.mutableState.pendingToolCalls = pendingToolCalls;
break;
case "tool_execution_end":
const pendingToolCalls = new Set(this.mutableState.pendingToolCalls);
pendingToolCalls.delete(event.toolCallId);
this.mutableState.pendingToolCalls = pendingToolCalls;
break;
// ...
}
// 第二步:再广播给外部监听器
for (const listener of this.listeners) {
await listener(event, signal);
}
}
先减后播 的时序保证:当外部监听器收到事件时,Agent 的内部状态已经反映了该事件的效果。如果顺序反过来(先播后减),监听器在处理事件时查询 agent.state.messages,可能看到过时的数据。
特别注意:pendingToolCalls 的修改方式——它不是直接 this.mutableState.pendingToolCalls.add(),而是先创建一个新 Set:
const pendingToolCalls = new Set(this.mutableState.pendingToolCalls);
pendingToolCalls.add(event.toolCallId);
this.mutableState.pendingToolCalls = pendingToolCalls;
这意味着 pendingToolCalls 属性每次变化都指向一个新的 Set 对象,强制外部通过 getter 获取的引用是最新的。这也是写时拷贝思想的一贯体现。
2.3 运行生命周期:ActiveRun 的 Promise 桥接
Agent 通过 ActiveRun 类型管理运行生命周期:
type ActiveRun = {
promise: Promise<void>;
resolve: () => void;
abortController: AbortController;
};
waitForIdle() 的实现很简单:
waitForIdle(): Promise<void> {
return this.activeRun?.promise ?? Promise.resolve();
}
关键区别:agent_end 事件和 finishRun() 之间有一个微妙但重要的时序差异:
// processEvents 中,agent_end 事件的处理
case "agent_end":
this.mutableState.streamingMessage = undefined;
break;
// ...然后广播给外部监听器...
// finishRun 在 runWithLifecycle 的 finally 块中调用
private finishRun(): void {
this.mutableState.isStreaming = false;
this.mutableState.streamingMessage = undefined;
this.mutableState.pendingToolCalls = new Set<string>();
this.activeRun?.resolve(); // 通知 waitForIdle() 的调用者
this.activeRun = undefined;
}
agent_end 表示"不再有循环事件产生",但此时外部监听器可能还在处理 agent_end 事件(比如保存会话到磁盘)。finishRun() 表示"所有监听器已执行完毕,运行状态已清理"。waitForIdle() 等待的是后者(activeRun.resolve() 触发)。
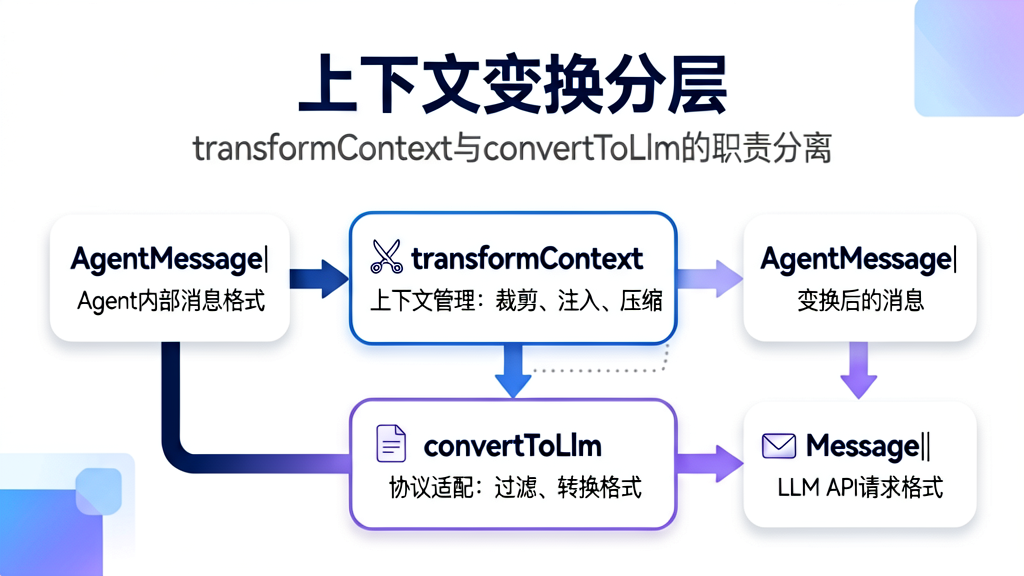
2.4 上下文变换的分层:transformContext 与 convertToLlm
在 streamAssistantResponse 中,消息从 Agent 内部格式到 LLM 请求格式经历了 2 层变换:
async function streamAssistantResponse(
context: AgentContext,
config: AgentLoopConfig,
signal: AbortSignal | undefined,
emit: AgentEventSink,
streamFn?: StreamFn,
runtime?: AgentCoreStreamRuntimeDeps,
): Promise<AssistantMessage> {
// 第1层:transformContext - 上下文管理
let messages = context.messages;
if (config.transformContext) {
messages = await config.transformContext(messages, signal); // AgentMessage[] → AgentMessage[]
}
// 第2层:convertToLlm - 协议适配
const llmMessages = await config.convertToLlm(messages); // AgentMessage[] → Message[]
// 构建 LLM 请求
const llmContext: Context = {
systemPrompt: context.systemPrompt,
messages: llmMessages,
tools: context.tools,
};
// ...调用 LLM ...
}
为什么需要两层变换?
| 变换 | 负责 | 不关心 |
|---|---|---|
transformContext |
裁剪旧消息、注入外部上下文、压缩历史 | LLM 消息格式差异 |
convertToLlm |
过滤不支持的消息类型、转换自定义格式 | 上下文管理的逻辑 |
这种分层使得上下文管理逻辑与 LLM 协议适配逻辑解耦。更换 LLM 提供商只需要修改 convertToLlm(比如 Claude 用 content 数组而 OpenAI 用 content 字符串),而更换上下文策略(比如从"保留最近 50 条"改为"基于 Token 预算裁剪")只需要修改 transformContext。
在 Agent 类中,这两个工具的默认值:
// convertToLlm 默认不做任何特殊转换
this.convertToLlm = options.convertToLlm ?? defaultConvertToLlm;
// transformContext 默认不存在(undefined),即不进行上下文变换
this.transformContext = options.transformContext;
defaultConvertToLlm 的实现(agent.ts 第 33 行)是一个简单的类型断言映射:
function defaultConvertToLlm(messages: AgentMessage[]): Message[] {
return messages as Message[];
}
因为 AgentMessage 兼容 Message 类型(AgentMessage 继承了 Message 的所有字段),所以默认情况下它们就是同一个东西。
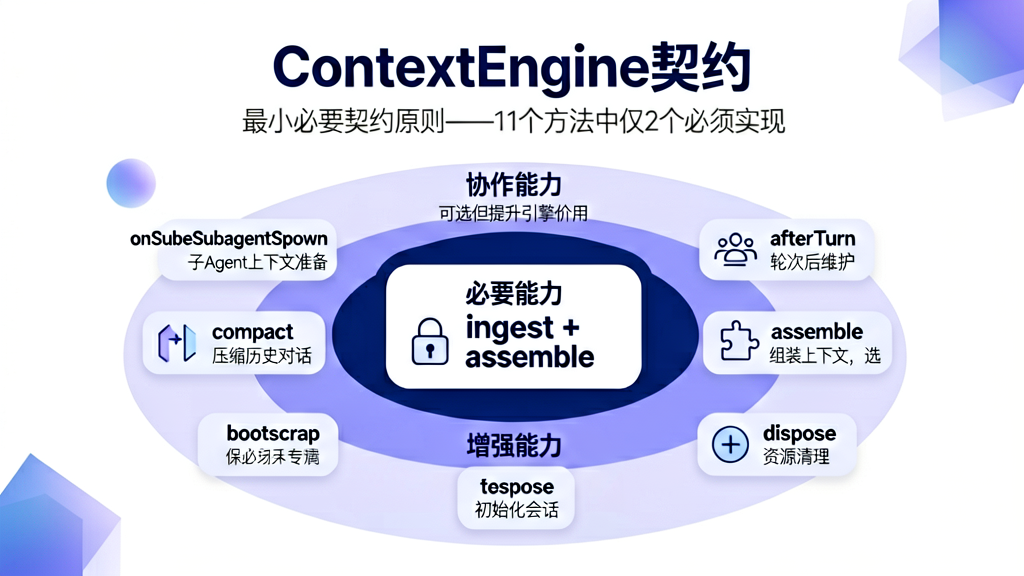
第三章 ContextEngine:可插拔契约的权衡哲学
3.1 接口设计的"最小必要契约"原则
ContextEngine 接口(src/context-engine/types.ts 第 238 行)有 11 个方法,但只有 2 个是必需的:
export interface ContextEngine {
readonly info: ContextEngineInfo;
// ★ 必需方法 ★
ingest(params: { sessionId: string; message: AgentMessage; ... }): Promise<IngestResult>;
assemble(params: { sessionId: string; messages: AgentMessage[]; tokenBudget?: number; ... }): Promise<AssembleResult>;
// ☆ 可选方法 ☆
bootstrap?(params: { ... }): Promise<BootstrapResult>;
maintain?(params: { ... }): Promise<ContextEngineMaintenanceResult>;
ingestBatch?(params: { ... }): Promise<IngestBatchResult>;
afterTurn?(params: { ... }): Promise<void>;
compact?(params: { ... }): Promise<CompactResult>;
prepareSubagentSpawn?(params: { ... }): Promise<SubagentSpawnPreparation | undefined>;
onSubagentEnded?(params: { ... }): Promise<void>;
dispose?(): Promise<void>;
}
不是偷懒,而是最小必要契约原则:一个上下文引擎至少需要做什么?
- 接收消息(
ingest) - 组装上下文(
assemble)
仅此两点。压缩、维护、子 Agent 准备——这些都是增强能力,不是必要能力。
最有力的证明:LegacyContextEngine(src/context-engine/legacy.ts):
export class LegacyContextEngine implements ContextEngine {
readonly info: ContextEngineInfo = {
id: "legacy",
name: "Legacy Context Engine",
version: "1.0.0",
};
async ingest(_params: { ... }): Promise<IngestResult> {
// No-op: SessionManager handles message persistence
return { ingested: false };
}
async assemble(params: { ... }): Promise<AssembleResult> {
// Pass-through: just return messages as-is
return {
messages: params.messages,
estimatedTokens: 0, // Caller handles estimation
};
}
async compact(params: { ... }): Promise<CompactResult> {
return await delegateCompactionToRuntime(params); // 委托给运行时
}
async dispose(): Promise<void> {
// Nothing to clean up
}
}
LegacyContextEngine 的 ingest 是 no-op(什么都不做),assemble 是 pass-through(直接返回原始消息),但它仍然是一个合法的 ContextEngine。这验证了"最小必要契约"的设计意图:让实现者可以渐进式增强,从最简实现开始,逐步添加可选方法。
设计权衡:可选方法越多,实现者的入门门槛越低(“我只用实现两个方法就能跑起来”),但也意味着不同引擎的行为差异可能很大(引擎 A 实现了 compact,引擎 B 没有,它们的长期行为就不同)。OpenClaw 通过 ContextEngineInfo 的元数据来声明引擎的能力特征:
export type ContextEngineInfo = {
id: string;
name: string;
version: string;
supportedOperations?: ContextEngineOperation[];
hostCapabilities?: ContextEngineHostCapability[];
hostRequirements?: ContextEngineHostRequirements[];
};
调用者通过检查 engine.info.supportedOperations 来了解引擎支持哪些操作,而不是通过 instanceof 或鸭子类型推断。
3.2 隔离与降级:Quarantine 机制的架构思想
resolveContextEngine 实现了三级降级策略:
尝试创建配置的引擎 → 失败则隔离 → 降级到默认引擎 → 默认引擎不可用则抛异常
这个设计的核心思想:隔离(Quarantine)不是错误,是保护。
自定义引擎是第三方的代码,可能包含 bug、内存泄漏、无限循环。如果自定义引擎的故障影响到了系统的基本可用性,那整个 Agent 都会瘫痪。所以系统说:“你的引擎不行了,先用我的默认引擎顶着,你慢慢修。”
默认引擎作为"安全岛",始终提供最基本的功能。这是一个经典的**舱壁模式(Bulkhead Pattern)**在 Agent 框架中的体现。
3.3 promptAuthority:Token 估算的"信任边界"
AssembleResult 中有一个名为 promptAuthority 的字段:
export type AssembleResult = {
messages: AgentMessage[];
estimatedTokens: number;
promptAuthority?: "assembled" | "preassembly_may_overflow";
systemPromptAddition?: string;
contextProjection?: ContextEngineProjection;
};
promptAuthority 控制的是:谁对 Token 估算有最终解释权?
"assembled"(默认):只用组装后的 prompt 的估算值"preassembly_may_overflow":取组装前和组装后估算的最大值
为什么会有这种区别?因为某些 ContextEngine 的组装过程会"隐藏"真实的上下文大小。比如引擎把 10 万 Token 的历史压缩成 1 万 Token 的摘要,estimatedTokens 是 1 万。但实际上,原始 10 万 Token 的历史仍然存在(只是没发给 LLM),如果你认为只有 1 万 Token 而继续追加新消息,最终写入会话文件的数据会膨胀到无法管理。
"preassembly_may_overflow" 采用悲观策略:取组装前后估算的最大值,宁可误报溢出也不漏报。这是典型的安全优先于性能的权衡。
3.4 子 Agent 上下文准备:事务性 Spawn
prepareSubagentSpawn 返回一个包含 rollback 函数的对象:
export type SubagentSpawnPreparation = {
rollback?: () => Promise<void>;
};
如果后续步骤失败,rollback 可以清理之前准备的状态。这是 Saga 模式的简化版本:每个步骤提供补偿操作,失败时按逆序执行补偿。
具体流程(subagent-spawn.ts 中 prepareContextEngineSubagentSpawn):
async function prepareContextEngineSubagentSpawn(params: { ... }): Promise<...> {
const rollbacks: Array<() => Promise<void>> = [];
// 步骤1:准备 ContextEngine
const enginePrep = await contextEngine.prepareSubagentSpawn?.({
parentSessionKey,
childSessionKey,
contextMode,
// ...
});
if (enginePrep?.rollback) {
rollbacks.push(enginePrep.rollback); // 注册补偿操作
}
// 如果后续步骤失败,执行所有已注册的 rollback
// ...
}
这个设计对应着:准备操作可能已经产生了副作用(创建文件、分配资源),必须要有清理机制。没有 rollback 的话,失败后会产生"幽灵资源"。
第四章 上下文压缩:MapReduce 思想的引入与安全边距设计
4.1 为什么需要 MapReduce?单次摘要的失败模式
新手理解:想象你要给朋友讲一本 500 页小说的剧情。如果你一次性讲完,你大概率会:记住开头和结尾,中间部分一团浆糊。LLM 在处理超长文本时有同样的"中间稀释"现象——开头和结尾的信息被强化,中间部分被忽略。
所以 OpenClaw 的做法是:把小说分成 5 个 100 页的小册子,每个小册子写一个摘要(Map),再把 5 个摘要合并成一个总摘要(Reduce)。每个小册子的信息密度更高,丢失信息的概率更低。
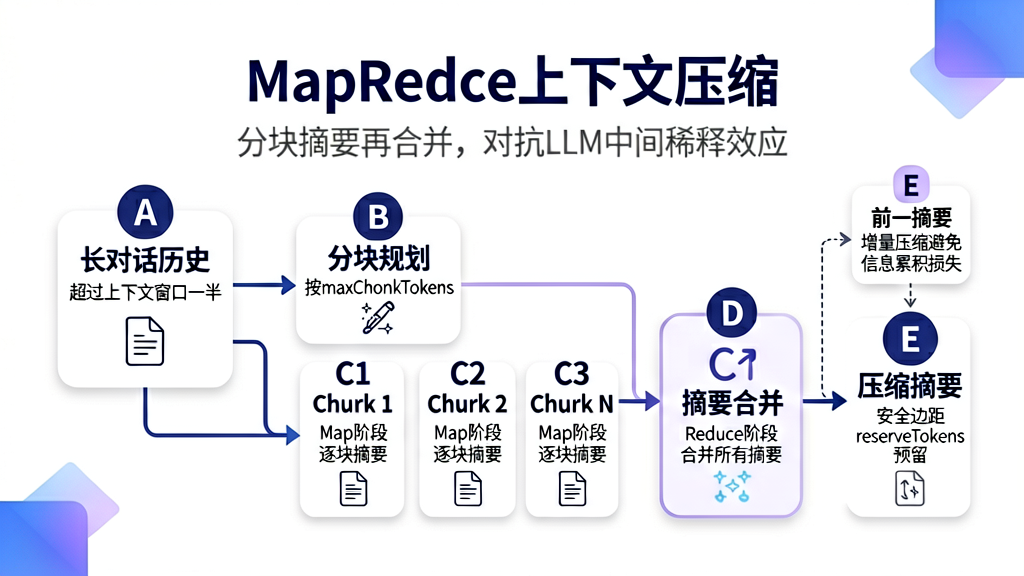
4.2 分块策略:buildStageSplitPlanWithWorker 的智能规划
summarizeInStages(src/agents/compaction.ts 第 334 行)的第一步是规划分块策略:
export async function summarizeInStages(params: { ... }): Promise<string> {
const { messages } = params;
if (messages.length === 0) {
return params.previousSummary ?? DEFAULT_SUMMARY_FALLBACK;
}
// 第一步:规划分块策略
const plan = await buildStageSplitPlanWithWorker({
messages,
maxChunkTokens: params.maxChunkTokens,
parts: params.parts,
minMessagesForSplit: params.minMessagesForSplit,
signal: params.signal,
});
// 单块模式:直接走单次摘要
if (plan.mode === "single") {
return summarizeWithFallback(params);
}
// 多块模式:Map → Reduce
const partialSummaries: string[] = [];
for (const chunk of plan.chunks) {
// === Map 阶段 ===
partialSummaries.push(
await summarizeWithFallback({ ...params, messages: chunk, previousSummary: undefined }),
);
}
// === Reduce 阶段 ===
const summaryMessages: AgentMessage[] = partialSummaries.map((summary) => ({
role: "user",
content: summary,
timestamp: Date.now(),
}));
return summarizeWithFallback({ ...params, messages: summaryMessages, customInstructions: mergeInstructions });
}
设计意图:minMessagesForSplit 阈值的存在是因为拆分本身有开销。如果只有 3 条消息(假设阈值是 10),拆分成 3 个 chunk 后每个 chunk 只有 1 条消息,信息量太少,LLM 难以产生有意义的摘要。这是一个拆分收益与开销的权衡。
buildStageSplitPlanWithWorker 的实现还利用了一个"规划 Worker":
export async function buildStageSplitPlanWithWorker(params: { ... }): Promise<StageSplitPlan> {
const messages = sanitizeCompactionMessages(params.messages);
// 消息太少时,直接在主线程计算(避免启动 Worker 的开销)
if (!shouldUsePlanningWorker(messages.length)) {
return buildStageSplitPlan(params);
}
// 消息太多时,交给 Worker 线程计算(不阻塞主线程)
const value = await runWithUnavailableFallback({
input: { kind: "stageSplit", messages, maxChunkTokens: params.maxChunkTokens, ... },
signal: params.signal,
fallback: () => ({ kind: "stageSplit" as const, ...buildStageSplitPlan(params) }),
isExpected: (valueResult): valueResult is ... => valueResult.kind === "stageSplit",
});
return value.mode === "split" ? { mode: "split", chunks: value.chunks } : { mode: "single" };
}
注意这里的 runWithUnavailableFallback:如果 Worker 线程不可用(比如在受限环境中),会有同步的 fallback 作为降级方案。
4.3 安全边距:reserveTokens 的架构意义
summarizeInStages 接收一个 reserveTokens 参数:
// 调用方传入 reserveTokens
const summary = await summarizeInStages({
messages,
model: params.model,
reserveTokens: SYSTEM_PROMPT_TOKENS + TOOL_DEFINITION_TOKENS + OUTPUT_BUFFER_TOKENS,
maxChunkTokens: params.maxChunkTokens,
// ...
});
reserveTokens 代表的是系统提示词、工具定义、输出缓冲等"不可压缩开销"。这些内容在每次 LLM 调用中都必须存在,不能被压缩掉。
为什么要在 Token 预算中预留安全边距?因为 LLM 的上下文窗口是一个硬约束——超过就会报错减去。而摘要本身也需要 Token 来输出,如果摘要输出把 Token 预算撑爆了,整个调用就会失败。
resolveSummaryReserveTokens 函数的实现(src/agents/agent-hooks/compaction-safeguard.ts):
function resolveSummaryReserveTokens(
requestedReserveTokens: number,
model: NonNullable<Parameters<typeof summarizeInStages>[0]["model"]>,
): number {
const requested = Math.max(1, Math.floor(requestedReserveTokens));
const modelMaxTokens = model.maxTokens;
// 如果模型有 maxTokens 限制,预留空间不能超过模型能力
// ...
}
4.4 带前一摘要的增量压缩
summarizeInStages 支持 previousSummary 参数:
export async function summarizeInStages(params: {
// ...
previousSummary?: string; // 前一次的摘要
}): Promise<string>
当存在前一次的摘要时,压缩不是从零开始,而是在前一摘要的基础上增量更新。这是通过 prependPreviousSummaryForRedistill 实现的:
function buildPreviousSummaryMessage(previousSummary: string): AgentMessage {
return {
role: "user" as const,
content: [
{
type: "text" as const,
text: `Previous compaction summary to re-distill with the current conversation. ` +
`Prune stale, duplicate, or superseded details instead of preserving it verbatim.\n\n` +
previousSummary,
},
],
timestamp: Date.now(),
};
}
为什么增量压缩很重要? 假设你的 Agent 已经运行了 100 轮对话,第一次压缩把 100 轮 → 摘要 A(信息密度 80%)。又运行了 50 轮,现在需要再次压缩。如果不使用 previousSummary,你需要重新处理全部 150 轮 → 摘要 B(信息密度还是 80%,但丢失了第一次压缩时已经丢失的 20% 信息)。而使用增量压缩:摘要 A + 新增 50 轮 → 摘要 B’(信息密度接近 80%,保留了历史摘要的信息)。
这解决了一个关键问题:如果每次压缩都从原始消息开始,信息损失会累积。增量压缩只需要处理新增的消息,既减少了计算量,又保留了历史摘要的信息。
第五章 工具循环检测:多探针防御体系的设计逻辑
5.1 为什么单一检测器不够?LLM 循环的多样性
生活类比:你家装了防盗系统,但只有一个红外传感器。小偷可以:绕过红外区、用热源屏蔽、从地下进入……单一传感器只能检测一种入侵模式。
LLM 的工具循环同样有多种模式:
| 模式 | 表现 | 检测器 |
|---|---|---|
| 精确重复 | 完全相同的工具+参数,连续出现多次 | generic_repeat |
| 未知工具重试 | 不断尝试调用一个不存在的工具 | unknown_tool_repeat |
| 死循环轮询 | 同一个轮询工具返回相同结果 | known_poll_no_progress |
| 乒乓循环 | 两个工具交替调用:A→B→A→B | ping_pong |
| 全局断路器 | 任意工具重复超过全局阈值 | global_circuit_breaker |
每种模式需要不同的检测策略。单一检测器无法覆盖所有模式。
5.2 SHA-256 指纹:为什么不用简单的字符串比较
源码验证(src/agents/tool-loop-detection.ts 第 137 行):
export function hashToolCall(toolName: string, params: unknown): string {
return `${toolName}:${digestStable(params)}`;
}
function digestStable(value: unknown): string {
const serialized = stableStringify(value); // 确定性序列化
return createHash("sha256").update(serialized).digest("hex"); // SHA-256 哈希
}
为什么不直接用 JSON.stringify + 字符串比较?
-
对象序列化的不确定性:
{a:1, b:2}和{b:2, a:1}在 JavaScript 中表示同一个对象,但JSON.stringify的结果不同。stableStringify确保了属性顺序的确定性。 -
固定长度指纹:如果工具参数是一个深层嵌套的 JSON 对象,直接用字符串比较需要存储整个序列化结果(可能是几千字符)。SHA-256 摘要固定为 64 字符的十六进制字符串。
设计权衡:哈希计算有 CPU 开销(SHA-256 计算),但换来了两个好处:固定长度的键(方便存储和比较)和确定性的指纹(避免误报)。
对于工具结果的哈希,逻辑更复杂:
function hashToolOutcome(
toolName: string,
params: unknown,
result: ToolResult,
): string {
// 对易变字段做特殊处理:去掉时间戳、随机ID等
return createHash("sha256")
.update(toolName)
.update(digestStable(stripVolatileSendIds(params)))
.update(digestStable(stripVolatileTimestamps(result)))
.digest("hex");
}
stripVolatileSendIds 的作用是去除消息投递中的易变字段(如消息 ID、时间戳),避免因为每次调用 ID 不同而导致摘要不同,从而无法检测到语义上的重复。
5.3 双级告警:warning 与 critical 的语义差异
type LoopDetectionResult =
| { stuck: false }
| {
stuck: true;
level: "warning" | "critical";
detector: LoopDetectorKind;
count: number;
message: string;
pairedToolName?: string;
warningKey?: string;
};
level 字段不是简单的"计数超过阈值就升级",而是不同检测器的不同严重程度:
| 检测器 | level | 原因 |
|---|---|---|
generic_repeat(精确重复) |
critical |
LLM 完全失去了探索能力 |
unknown_tool_repeat(未知工具) |
critical |
不断尝试不可能成功的操作 |
known_poll_no_progress(轮询无进展) |
warning(低阈值)→ critical(高阈值) |
可能是合理的轮询操作 |
ping_pong(交替循环) |
warning |
可能是合理的多步骤操作 |
关键阈值:
export const WARNING_THRESHOLD = 10; // 10次 → warning
export const UNKNOWN_TOOL_THRESHOLD = 10; // 10次未知工具 → critical
export const CRITICAL_THRESHOLD = 20; // 20次 → critical
export const GLOBAL_CIRCUIT_BREAKER_THRESHOLD = 30; // 30次 → 全局断路器
5.4 检测器的可扩展性:LoopDetectorKind 的开放枚举
type LoopDetectorKind =
| "generic_repeat"
| "unknown_tool_repeat"
| "known_poll_no_progress"
| "global_circuit_breaker"
| "ping_pong";
这是一个字符串联合类型,而非 TypeScript enum。这意味着可以在不修改类型定义的情况下添加新的检测器类型——只需要在 detectToolCallLoop 函数中增加新的检测逻辑,返回一个新的 detector 字符串即可。
对比 enum 的缺点:每次添加新值都需要修改枚举定义,且 enum 在运行时是对象(有反向映射),增加包体积。字符串联合类型在编译期就擦除了,运行时零开销。
第六章 模型降级链:冷却探针与熔断器的协作逻辑
6.1 降级不是失败,是自保
当主模型返回错误时,系统不是立即重试,而是尝试降级到备用模型。
决策逻辑:主模型的错误可能是持续性的(服务过载、配额耗尽),重试只会浪费时间和配额。降级是更快的恢复路径。
6.2 冷却探针:什么时候尝试恢复主模型?
降级后的关键问题是:什么时候尝试恢复主模型?
- 太快:主模型还没恢复,又失败了
- 太慢:用户一直用慢速的备用模型,体验下降
冷却探针的设计是:
- 降级后设置一个冷却期,期间不尝试主模型
- 冷却期结束后,发送一个探针请求(一次轻量级的 LLM 调用)
- 探针成功 → 恢复主模型
- 探针失败 → 重新进入冷却期(通常冷却期会翻倍)
设计意图:冷却探针本质上是指数退避策略的变体。它在"尽早恢复"和"避免无效重试"之间找到平衡点。探针请求的成本很低(一次 LLM 调用),但能提供实时的服务状态信号。
6.3 熔断器:从降级到拒绝服务
如果所有模型都不可用,熔断器会打开。熔断器打开后,后续请求直接失败,不再尝试任何模型。
这是服务保护的最后一道防线:与其让用户等待超时(可能等 30 秒才超时),不如快速失败(10 毫秒内返回错误)并给出明确的错误信息。
熔断器的三种状态:
- 关闭:正常运行
- 打开:所有请求快速失败
- 半开:允许少量请求通过,测试服务是否恢复
熔断器的存在使得系统在极端情况下也能保持可预测的行为——用户永远不会遇到"卡住不动"的情况,要么拿到结果,要么快速得到错误信息。
第七章 子 Agent 治理:深度限制、角色三态与上下文继承
7.1 深度限制:防止 Agent"无限套娃"
生活类比:俄罗斯套娃。你打开最大的娃娃,里面有一个中等的,再打开有一个小的。但如果娃娃没有数量限制,你可能会打开 100 层,每一层都在消耗你的注意力和空间。
源码验证(src/agents/subagent-spawn.ts 第 1169 行):
const callerDepth = getSubagentDepthFromSessionStore(requesterInternalKey, { cfg });
const maxSpawnDepth =
cfg.agents?.defaults?.subagents?.maxSpawnDepth ?? DEFAULT_SUBAGENT_MAX_SPAWN_DEPTH;
// 关键:深度限制检查
if (callerDepth >= maxSpawnDepth) {
return {
status: "forbidden",
error: `sessions_spawn is not allowed at this depth (current depth: ${callerDepth}, max: ${maxSpawnDepth})`,
};
}
深度限制不是唯一的限制。紧接着还有子 Agent 数量限制:
const maxChildren =
cfg.agents?.defaults?.subagents?.maxChildrenPerAgent ?? DEFAULT_SUBAGENT_MAX_CHILDREN_PER_AGENT;
const activeChildren = countActiveRunsForSession(requesterInternalKey);
if (activeChildren >= maxChildren) {
return {
status: "forbidden",
error: `sessions_spawn has reached max active children for this session (${activeChildren}/${maxChildren})`,
};
}
为什么同时限制深度和子 Agent 数量?因为 Agent 的递归创建会导致资源指数级增长——每一层 Agent 都需要自己的 LLM 连接(API 连接数)、上下文窗口(内存)和工具执行环境(进程/线程)。深度限制是纵向边界,子 Agent 数量是横向边界。两者结合形成一个"矩形"资源约束范围。
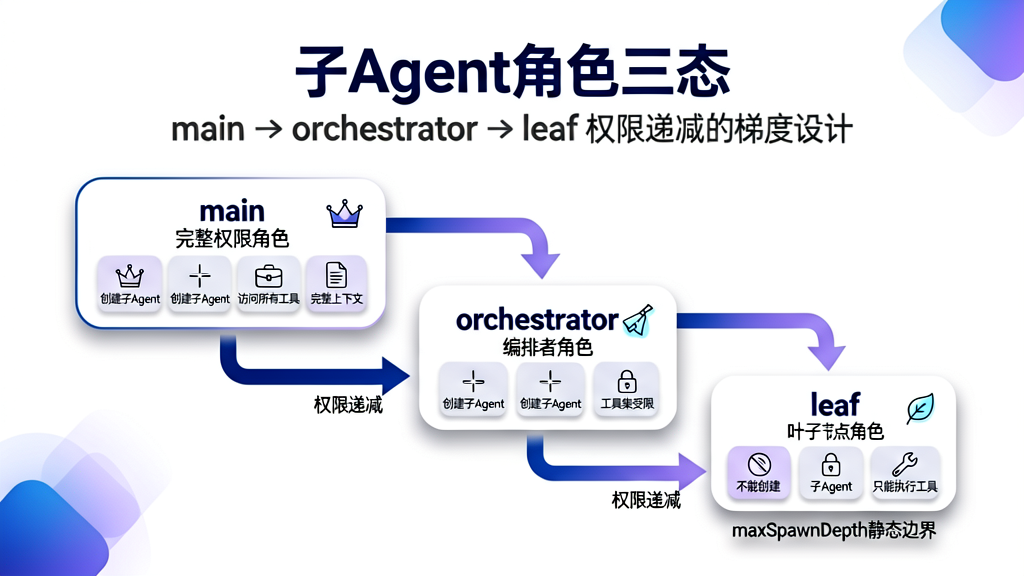
7.2 角色三态:main/orchestrator/leaf 的权限梯度
源码验证(src/agents/subagent-capabilities.ts 第 161 行):
function resolveSubagentRoleForDepth(params: {
depth: number;
maxSpawnDepth?: number;
}): SubagentSessionRole {
const depth = resolveNonNegativeIntegerOption(params.depth, 0);
const maxSpawnDepth = resolveIntegerOption(params.maxSpawnDepth, DEFAULT_SUBAGENT_MAX_SPAWN_DEPTH, { min: 1 });
if (depth <= 0) {
return "main"; // 根 Agent:完整权限
}
return depth < maxSpawnDepth ? "orchestrator" : "leaf"; // 中间层 / 叶子节点
}
三种角色的权限递减:
| 角色 | depth | 能否创建子 Agent | 工具集 | 控制范围 |
|---|---|---|---|---|
main |
0 | ✅ 完整权限 | 全部工具 | children |
orchestrator |
1 ~ maxSpawnDepth-1 | ✅ 可以 | 受限制 | children |
leaf |
≥ maxSpawnDepth | ❌ 不能 | 最小集 | none |
完整的 resolveSubagentCapabilities 返回:
export function resolveSubagentCapabilities(params: { depth: number; maxSpawnDepth?: number }) {
const role = resolveSubagentRoleForDepth(params);
const controlScope = resolveSubagentControlScopeForRole(role);
return {
depth,
role,
controlScope,
canSpawn: role === "main" || role === "orchestrator",
// ...
};
}
角色三态解决的是权限最小化问题:如果所有子 Agent 都有完整权限,一个受损的子 Agent 可能创建无限子 Agent 链。角色梯度确保了即使子 Agent 行为异常,其影响范围也被限制在可控范围内。
7.3 上下文继承:isolated 与 fork 的权衡
prepareSubagentSpawn 支持两种上下文模式:
prepareSubagentSpawn?(params: {
parentSessionKey: string;
childSessionKey: string;
contextMode?: "isolated" | "fork"; // 关键参数
// ...
}): Promise<SubagentSpawnPreparation | undefined>;
| 模式 | 行为 | 优点 | 缺点 |
|---|---|---|---|
isolated |
子 Agent 从空白上下文开始 | 完全隔离,不会被父 Agent 的上下文污染 | 缺少背景信息,需要更多轮次理解任务 |
fork |
子 Agent 继承父 Agent 的上下文副本 | 有完整背景,可以立即开始工作 | 上下文污染风险,父 Agent 的无关信息可能干扰子 Agent |
架构意义:fork 模式是"写时拷贝"——子 Agent 拿到的是父 Agent 上下文的快照副本,而非引用。这意味着:
- 子 Agent 对上下文的修改不会影响父 Agent
- 父 Agent 后续的上下文变化也不会影响子 Agent
- 两者完全隔离,互不干扰
这对应着 Agent 类中的 createContextSnapshot:
private createContextSnapshot(): AgentContext {
return {
systemPrompt: this.mutableState.systemPrompt,
messages: this.mutableState.messages.slice(), // 数组拷贝
tools: this.mutableState.tools.slice(), // 数组拷贝
};
}
每次给子 Agent 传上下文时,都是通过 .slice() 创建的新数组。
第八章 会话安全:文件锁、PID 复用检测与信号处理
8.1 为什么需要文件锁?Agent 的并发写入问题
Agent 的会话状态存储在文件系统中。在多 Agent 场景下,多个 Agent 可能同时写入同一个会话文件(例如父 Agent 和子 Agent 共享同一个 session 文件)。如果没有锁,并发写入会导致数据损坏。
为什么不用数据库?因为 Agent 的会话数据是临时性的、低并发的。引入数据库(如 SQLite、Redis)会增加运维复杂度(安装、配置、备份),而文件锁在低并发场景下更简单、更可靠。
8.2 PID 复用检测:死锁的防御
文件锁的经典问题是死锁:持锁进程崩溃后没有释放锁。锁定文件会永远存在,后续所有进程都无法获取锁。
OpenClaw 的解决方案是在锁文件中记录 PID。获取锁时:
- 检查锁文件是否存在
- 如果存在,读取文件中的 PID
- 检查该 PID 对应的进程是否还在运行
- PID 不存在 → 死锁,可以安全地强制获取锁
- PID 存在 → 锁仍被持有,等待
但 PID 复用会导致误判:进程 A 持有锁→进程 A 崩溃→操作系统将 PID 分配给新进程 B→进程 B 检查 PID 发现存在→误以为锁的持有者还在运行。
OpenClaw 通过 PID + 启动时间戳 的组合来解决这个问题,大幅降低了误判概率。即使 PID 被复用,启动时间戳也不同。
8.3 信号处理:优雅的中断与清理
Agent Loop 接受 AbortSignal 参数:
agentLoop(prompts, context, config, signal, streamFn, runtime)
// ↑ 关键参数
当用户取消或系统关闭时,信号会传递到所有异步操作:
// Agent 类中
private async runWithLifecycle(executor: (signal: AbortSignal) => Promise<void>): Promise<void> {
const abortController = new AbortController();
// ...
this.activeRun = { promise, resolve: resolvePromise, abortController };
try {
await executor(abortController.signal); // 把 signal 传递给整个执行链
} catch (error) {
await this.handleRunFailure(error, abortController.signal.aborted);
} finally {
this.finishRun();
}
}
关键设计:中断是协作式停止,不是强制终止。Agent Loop 在检测到中断信号后:
- 发出
aborted停止原因(而不是直接抛异常) - 执行必要的清理(释放锁、写入当前状态到磁盘)
- 生成一个包含错误信息的
failureMessage - 通过正常的事件流(
message_start→message_end→turn_end→agent_end)优雅退出
private async handleRunFailure(error: unknown, aborted: boolean): Promise<void> {
const failureMessage = {
role: "assistant",
content: [{ type: "text", text: "" }],
stopReason: aborted ? "aborted" : "error", // 区分中断和错误
errorMessage: error instanceof Error ? error.message : String(error),
timestamp: Date.now(),
} satisfies AgentMessage;
// 仍然通过正常事件流发布
await this.processEvents({ type: "message_start", message: failureMessage });
await this.processEvents({ type: "message_end", message: failureMessage });
await this.processEvents({ type: "turn_end", message: failureMessage, toolResults: [] });
await this.processEvents({ type: "agent_end", messages: [failureMessage] });
}
这意味着监听事件的 UI 层不需要特殊处理中断情况——它和正常流程一样处理事件,最后看到一个 stopReason: "aborted" 的消息。
在工具执行层面,中断信号也同样传递:
// agent-loop.ts 第 610 行
if (signal?.aborted) {
break; // 工具执行中检测到中断,立即停止
}
第九章 系统韧性:从各个组件的防御设计中提炼统一原则
回顾前八章的分析,OpenClaw 的 Agent 运行时和记忆系统体现了一组统一的设计原则。每一章中我们都能看到这些原则的反复出现:
9.1 防御性编程:写时拷贝与不可变视图
出现在以下地方:
- 2.1 状态管理:
tools.slice()和messages.slice()写入时拷贝(agent.ts) - 2.3 上下文快照:
createContextSnapshot()创建不可变的上下文副本(agent.ts) - 7.3 子 Agent fork:子 Agent 继承的上下文是父 Agent 的快照副本
核心思想:不可变性是并发安全的基础。在 Agent 的异步并发环境中,共享可变状态是万恶之源。每条代码路径都假设"别人可能在修改同一个数据",所以每次写入都通过拷贝隔离影响。
9.2 最小必要契约:接口的可选性设计
出现在以下地方:
- 3.1 ContextEngine:11 个方法中只有 2 个是必需的,其余都是可选的(
context-engine/types.ts) - 5.4 LoopDetectorKind:字符串联合类型而非枚举,允许不修改类型定义就添加新检测器(
tool-loop-detection.ts) - 1.2 PendingMessageQueue:drain 的
"all"和"one-at-a-time"两种模式(agent.ts)
核心思想:最小化强制约束,最大化扩展空间。强制约束越少,实现者的自由度越高,但也需要通过元数据和能力声明来弥补约束的缺失。
9.3 故障隔离:从 Quarantine 到熔断器
出现在以下地方:
- 3.2 ContextEngine 隔离:自定义引擎故障不影响默认引擎(
context-engine/registry.ts) - 6.3 熔断器:所有模型不可用时快速失败而非等待超时
- Agent.handleRunFailure:异常通过正规事件流优雅传播,不抛异常打断调用者
核心思想:故障应该被隔离,不应该传播。一个模块的失败不应该拖垮整个系统。
9.4 增量处理:从增量压缩到冷却探针
出现在以下地方:
- 4.4 增量压缩:
previousSummary参数避免全量信息损失 - 6.2 冷却探针:轻量级探针检测模型恢复状态,而非全量重试
- PendingMessageQueue drain:
"one-at-a-time"一次只处理一条消息
核心思想:处理应该是增量的,不是全量的。全量处理的开销随数据量线性增长,而增量处理的开销是恒定的。在 Agent 的长时间运行场景中,增量处理是可持续性的关键。
9.5 权限最小化:从角色三态到深度限制
出现在以下地方:
- 7.1 深度限制:防止 Agent 无限制递归创建子 Agent
- 7.2 角色三态:main → orchestrator → leaf 的权限递减
- 7.1 子 Agent 数量限制:横向限制并发子 Agent 数量
- Agent.continue:校验最后消息角色,防止非法 LLM 调用
核心思想:每个组件只应该拥有完成任务所需的最小权限。这不仅是安全考量,也是可靠性考量:权限越小,出错的可能性越小。
结语
OpenClaw 的 Agent 运行时和记忆系统不是一组独立的组件,而是一个共生的架构体系。每个组件的设计都不是孤立的决策,而是在特定约束下的权衡结果。理解这些权衡,比理解具体实现更重要——因为实现会变,但权衡的逻辑是恒久的。
从架构师的视角看,OpenClaw 的核心设计哲学可以概括为一句话:在不确定性中寻找确定性。LLM 的输出是不确定的(同一个 prompt 可能得到不同的结果),工具调用的顺序是不确定的(工具的副作用不可预测),模型的可用性是不确定的(服务可能过载、API 可能限流)。但通过防御性编程、故障隔离、增量处理和权限最小化,系统在整体上表现出可预测的行为。
这正是工程化的价值所在:把不可控的 AI 能力,嵌入到一个可控的、可预测的、可维护的系统中。
附录:核心源文件索引
为了方便读者自行查阅源码,以下是本文涉及的核心文件的路径:
| 模块 | 文件路径 | 关键内容 |
|---|---|---|
| Agent Loop | packages/agent-core/src/agent-loop.ts |
双层循环引擎、工具执行 |
| Agent 类 | packages/agent-core/src/agent.ts |
状态管理、事件处理、生命周期 |
| Agent 类型 | packages/agent-core/src/types.ts |
AgentEvent、AgentState、AgentTool |
| ContextEngine 接口 | src/context-engine/types.ts |
接口定义、AssembleResult |
| Legacy Engine | src/context-engine/legacy.ts |
最小实现的示范 |
| 上下文压缩 | src/agents/compaction.ts |
summarizeInStages、MapReduce |
| 分块规划 | src/agents/compaction-planning-worker.ts |
智能分块策略 |
| 循环检测 | src/agents/tool-loop-detection.ts |
多探针防御 |
| 子 Agent 权限 | src/agents/subagent-capabilities.ts |
角色三态、深度限制 |
| 子 Agent Spawn | src/agents/subagent-spawn.ts |
深度检查、Saga rollback |
| 压缩保护 | src/agents/agent-hooks/compaction-safeguard.ts |
增量压缩、安全边距 |